正确率、精确率、召回率介绍+Tensorflow代码实现
1.二分类评价标准介绍
在进行二分类后需要对分类结果进行评价,评价的标准除了常用的正确率之外还有召回率精确度,虚警率和漏警率等。首先介绍一下最常用的正确率
正确率(Accuracy)表示正负样本被正确分类的比例,计算公式如下:
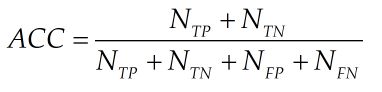
其中 N T P N_{TP} NTP 表示正类样本被正确分类的数目, N T N N_{TN} NTN表示负类样本被正确分类的数目, N F P N_{FP} NFP表示负类样本被分为正类的数目, N F N N_{FN} NFN表示正类样本被分为负类的数目。
如下表所示:

-
精确率(Precision)表示原本为正类样本在所有被分为正类样本(正的被分为正的+错的被分为正的)的比例

-
召回率(Recall)表示原本为正类样本在原本正类样本(正的被分为正的+正的被分为错的)的比例
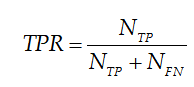
-
虚警率(False alarm)表示负类样本被分为正类样本在所有负类样本中的比例

-
漏警率表示(Missing alarm)表示正类样本被分为负类样本在所有正类样本中的比例

2. Tensorflow实现代码
计算公式已经在第一节给出了,代码实现最难的部分不是计算而是对于数据格式的转换。本文背景为,利用保存好的模型在测试集上进行测试,然后对测试集的分分类结果进行评估。建议先看下这篇博客:Tensorflow在训练好的模型上进行测试。
直接上代码,其中函数的predict是预测结果,也就是神经网络的输出,real是真实的标签,sess就是tensorflow当前的会话,feed_dict是需要喂的数据。下面详细讲解一下代码
prediction=tf.matmul(tf.reshape(outputs, [-1, 2 * lstmUnits]), weight) + bias #注意这里的维度,lstmUnits是双向LSTM隐藏层单元,weight和bias为全连接层权重和偏置,outputs为BiLSTM最后一个输出
labels = tf.placeholder(tf.float32, [batchSize, numClasses])
pred=tf.argmax(prediction, 1)
lab= tf.argmax(labels,1)
#函数tf.argmax()返回值是是数值最大值的索引位置,如果最大值位置相同,则分类正确,反之则分类错误
下面的代码是将上述代码获得到变量设置为元素为0或者1的矩阵,在后面计算的时候只需要按照逻辑与计算即可.
ones_like_actuals = tf.ones_like(lab)
zeros_like_actuals = tf.zeros_like(lab)
ones_like_predictions = tf.ones_like(pred)
zeros_like_predictions = tf.zeros_like(pred)
后面的都是按第一节公式计算的部分
tp_op = tf.reduce_sum(
tf.cast(
tf.logical_and(
tf.equal(lab, ones_like_actuals),
tf.equal(pred, ones_like_predictions)#zeros_like_predictions多分类,替换tp_op和fp_op 中的ones_like_predictions
),
"float"
)
)
tn_op = tf.reduce_sum(
tf.cast(
tf.logical_and(
tf.equal(lab, zeros_like_actuals),
tf.equal(pred, zeros_like_predictions)
),
"float"
)
)
fp_op = tf.reduce_sum(
tf.cast(
tf.logical_and(
tf.equal(lab, zeros_like_actuals),
tf.equal(pred, ones_like_predictions)
),
"float"
)
)
fn_op = tf.reduce_sum(
tf.cast(
tf.logical_and(
tf.equal(lab, ones_like_actuals),
tf.equal(pred, zeros_like_predictions)
),
"float"
)
)
完整函数代码
def tf_confusion_metrics(predict, real, session, feed_dict):
predictions = tf.argmax(predict, 1)
actuals = tf.argmax(real, 1)
ones_like_actuals = tf.ones_like(actuals)
zeros_like_actuals = tf.zeros_like(actuals)
ones_like_predictions = tf.ones_like(predictions)
zeros_like_predictions = tf.zeros_like(predictions)
tp_op = tf.reduce_sum(
tf.cast(
tf.logical_and(
tf.equal(actuals, ones_like_actuals),
tf.equal(predictions, ones_like_predictions)
),
"float"
)
)
tn_op = tf.reduce_sum(
tf.cast(
tf.logical_and(
tf.equal(actuals, zeros_like_actuals),
tf.equal(predictions, zeros_like_predictions)
),
"float"
)
)
fp_op = tf.reduce_sum(
tf.cast(
tf.logical_and(
tf.equal(actuals, zeros_like_actuals),
tf.equal(predictions, ones_like_predictions)
),
"float"
)
)
fn_op = tf.reduce_sum(
tf.cast(
tf.logical_and(
tf.equal(actuals, ones_like_actuals),
tf.equal(predictions, zeros_like_predictions)
),
"float"
)
)
tp, tn, fp, fn = session.run([tp_op, tn_op, fp_op, fn_op], feed_dict)
#feed_dict为喂养的数据,比如我这批预测数据为数据是nextBatch, nextBatchLabels = getTestBatch(),nextBatch为数据,而nextBatchLabels 则是数据标签。则 feed_dict={input_data: nextBatch, labels: nextBatchLabels})
tpr = float(tp)/(float(tp) + float(fn))
fpr = float(fp)/(float(fp) + float(tn))
fnr = float(fn)/(float(tp) + float(fn))
accuracy = (float(tp) + float(tn))/(float(tp) + float(fp) + float(fn) + float(tn))
recall = tpr
precision = float(tp)/(float(tp) + float(fp))
f1_score = (2 * (precision * recall)) / (precision + recall)
计算评价标准的函数不难,难得是调用函数,这部分可以结合:Tensorflow在训练好的模型上进行测试来看。
尊重原创,文章摘自:Tensorflow计算正确率、精确率、召回率、虚警率和漏检率