hibernate内存泄漏_ConcurrentStatisticsImpl
背景:
前段时间有个在线的系统(压力比较大),发现每隔一段时间就会出现系统有警报,如1000条请求就有几条是read time out.
跟踪问题
首先看下发现CPU,服务器内存,硬盘等信息都还OK,
然后查看下jvm的进程健康情况:
jstat -gcutil <进程号>
[root@ZN-YSTJQ-06 ~]# jstat -gcutil 99251 2000 40
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 15.56 23.14 95.96 95.62 92.12 16549 323.923 63 122.766 446.689
0.00 15.56 29.73 95.96 95.62 92.12 16549 323.923 63 122.766 446.689
0.00 15.56 36.30 95.96 95.62 92.12 16549 323.923 63 122.766 446.689
0.00 15.56 43.52 95.96 95.62 92.12 16549 323.923 63 122.766 446.689
0.00 15.56 48.96 95.96 95.62 92.12 16549 323.923 63 122.766 446.689发现fgc已经非常高了,我查看了一下内存的设置,堆的大小设置为4G,我们也没有在进程里设置业务数据的内存,按理,这些内存是OK的,
临时的解决方案自然是先重启,因为他一段时间才会重现,也能让服务器多撑一段时间,
后续要找出具体的原因,于是就把jvm的dump文件给导出来查看下内容.
jmap -dump:format=b,file=dump.bin <进程号>分析过程
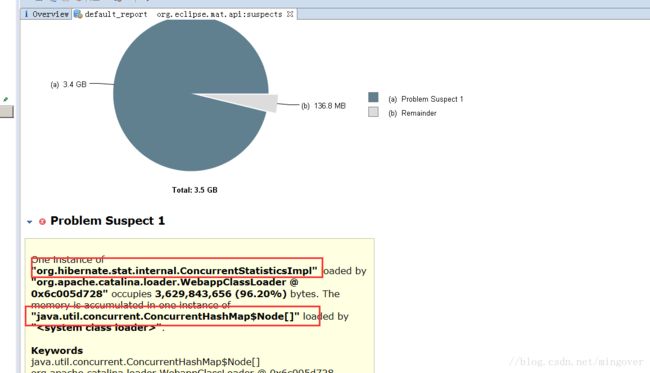
这个泄漏嫌疑的类已经很明显了,但是这个类是 hibernate的类,不好确认,于是再进一步分析。
我们找到这个类,跟下去找,发现
java.util.concurrent.ConcurrentHashMap$Node 这个类有300多万个对象,

由于是框架内的类,我们要去找下这个类相关的资料
org.hibernate.stat.internal.ConcurrentStatisticsImpl
相关源码:
https://github.com/hibernate/hibernate-orm/blob/master/hibernate-core/src/main/java/org/hibernate/stat/internal/ConcurrentStatisticsImpl.java
这个类有很多cache相关的 关键字,我们可以容易想到这是和缓存有关的类,我们去找hibernate 的配置,发现缓存都是给关闭的.
<prop key="hibernate.cache.use_second_level_cache">falseprop>
<prop key="hibernate.cache.use_query_cache">falseprop>还以为是版本问题配置不同了,但找了几下也没感觉有问题。
继续跟踪

如上图,发现内容存的都是hql或sql,
是org.hibernate.stat.internal.ConcurrentStatisticsImpl这个类下面的queryStatistics 成员变量的table存了大量数据。
后来发现 queryStatistics 这是一个 监控性能 里的一个内容,只要把下面的这个设置为false即可
<prop key="hibernate.generate_statistics">falseprop>验证
最好的验证方式是多次请求后看看gc,不过这个验证时间太长了,我们还是以debug的方式查看下
Statistics statistics = sessionFactory.getStatistics();查看这个statistics 里面的 queryStatistics ,如果里面是空,说明问题已经解决了.