《RocketMq》二、存储篇
RocketMQ的数据存储部分也是一个重头戏,他主要用于存储Producer生产的消息,Consume的逻辑队列,索引,以及主从复制,这里也是一个非常好的范例,我们可以看到如何处理数据存储,如何提高IO效率。
东西太多信息量略大有点乱,之后再整理吧......
一、总体结构
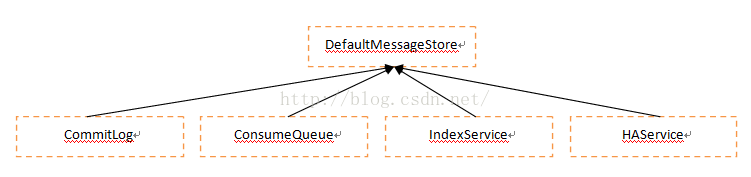
CommitLog:实时执行,真正的I/O写入磁盘操作, 要求是实时的(当然,有时候只是写入内存,定时刷盘);
ConsumeQueue:后台非实时执行,根据CommitLog,生成ConsumeQueue的信息,其记录了每个queue的物理commitOffset和逻辑logicOffset的信息;
IndexService:后台非实时执行,如果发送消息的propety字段里面有keys字段,那么会将他以空格为分隔符,生成key和对应的index信息;
HAService:后台非实时执行,处理和slave之间的信息备份。
队列逻辑结构:
逻辑上来看,每一个Topic有很多queue,他们各自处于自己的ConsumeQueue进行处理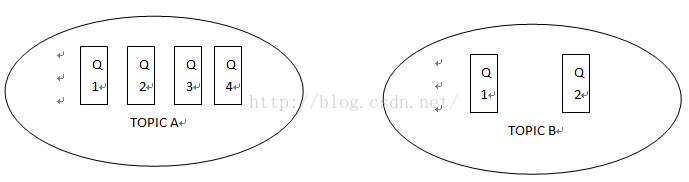
二、基础数据结构
MapedFileQueue:包含了很多MapedFile,以及每个MapedFile的真实大小;
MapedFile:包含了具体的文件信息,包括文件路径,文件名,文件起始偏移,写位移,读位移等等信息,同时使用了虚拟内存映射来提高IO效率;
这两个数据结构是真实的保存了存放在物理机器上的文件信息,后续的很多模块如果涉及到文件存储,都会使用到这两个数据结构。
2.1. MapedFileQueue:
// 每次触发删除文件,最多删除多少个文件
private static final int DeleteFilesBatchMax = 10;
// 文件存储位置
private final String storePath;
// 每个文件的大小
private final int mapedFileSize;
// 各个文件
private final List mapedFiles = new ArrayList();
// 读写锁(针对mapedFiles)
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
// 预分配MapedFile对象服务
private final AllocateMapedFileService allocateMapedFileService;
// 刷盘刷到哪里
private long committedWhere = 0;
// 最后一条消息存储时间
private volatile long storeTimestamp = 0;
2.2. MapedFile:保存了文件的详细信息,包括:
TotalMapedVitualMemory:JVM中映射的虚拟内存总大小
TotalMapedFiles:JVM中mmap的数量
fileName:文件名
fileFromOffset:文件的起始偏移量
fileSize:文件大小
file:文件句柄
mappedByteBuffer:映射的内存对象
wrotePostion:当前文件的写位置
committedPosition:当前文件Flush到的位置
fileChannel:映射的FileChannel对象
storeTimestamp:最后一条消息保存时间
firstCreateInQueue:是不是刚刚创建的Map
2.3. AllocateMappedFileService:用于异步创建MappedFile,其实这里和通讯的I/O操作是一样的,也是采用异步创建文件的方式,超时会报错,其中的细节与通讯的ResponseFuture类似,通过AllocateRequest里面的countdown来判断是否创建成功。
2.4. 写入文件的优化策略:
由于每次都写入磁盘,其实是非常慢的,因此对于写盘操作有2种优化方式:
第一种方式是写入filechannel map的缓存:mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);,这里主要使用2个pos,一个是writeposition,表示写入map的位置;一个是flushposition,表示真正刷入磁盘的位置;同时还将启动一个定时任务,flushCommitLogService,用于刷新到磁盘当中。
第二种方式是写入自定义的缓存,这种方式只有在ASYNC_FLUSH刷盘模式,且transientStorePoolEnable模式开启的时候,才会启用:this.writeBuffer = transientStorePool.borrowBuffer();这里主要使用3个pos,一个是commitposition,表示写入真正的filechannel的位置;一个是writeposition,表示写入自定义buffer的位置;一个是flushposition,表示真正刷入磁盘的位置;同时会启用2个service服务,一个是commitLogService,用于启动定时任务刷新缓存到filechannel,一个是flushCommitLogService,用于刷新到磁盘当中。
2.5 刷盘策略:
1. GroupCommitService:如果是同步刷盘,flushCommitLogService使用该策略;要注意如果是同步刷盘,是不会启用自定义buffer优化模式的,所以不用担心自定义刷盘模式的commit没有被调用导致刷盘失败。这里的刷盘策略和之前的map文件写入以及通讯io操作相同,都是使用request的方式,将其放入到GroupCommitRequest的请求当中,等待这个request的countDownLatch唤起,否则这个操作将会超时,返回客户端失败。
2. CommitRealtimeService:其中的commitLogService使用该策略;这里是每隔200ms会进行一次commit到filechannel的操作;
3. FlushRealTimeService:如果是异步刷盘,flushCommitLogService使用该策略;这里每隔2s会进行一次真正的刷盘操作。
三、主要模块介绍
3.1 CommitLog(物理队列):
CommitLog是用于存储真实的物理消息的结构,ConsumeQueue是逻辑队列,仅仅存储了CommitLog的位移而已,真实的存储都在本结构中。
1. 首先这里会使用CommitLog.this.topicQueueTable.put(key, queueOffset),其中的key是 topic-queueId, queueOffset是当前这个key中的消息数,每增加一个消息增加一(不会自减);
这里queueOffset的用途如下:每次用户请求putMessage的时候,将queueOffset返回给客户端使用,这里的queueoffset表示逻辑上的队列偏移。 2. 其次就是将消息写入真正的MapedFile,MapedFile中,每条消息的格式如下:

MagicCode:MessageMagicCode = 0xAABBCCDD ^ 1880681586 + 8
BodyCRC:对Body的校验码
queueId:队列Id
queueOffset:topic-queueId对应的队列数目
physicalOffset:真实的地址偏移,包括所有文件的总偏移
3. putMessage所做操作
3.1 将数据写入mapedFile,并将topic-queueId,queueOffset写入topicQueueTable
3.2 创建DispatchRequest,将消息放入DispatchMessageService的List中,进行后续处理
3.3 进行同步刷盘,或者异步刷盘
FlushCommitLogService:刷盘基类;
GroupCommitService:同步刷盘;每次写入消息时,调用swapRequests进行数据交换,然后将所有的请求进行刷盘
FlushRealTimeService:异步刷盘;调用mappedByteBuffer.force()进行刷盘操作
CommitRealTimeService:异步刷盘模式,如果启用了transientStorePoolEnable,那么会启动该service进行刷盘到filechannel
3.2 ConsumeQueue(逻辑队列):
1.ConsumeQueue的结构
该结构对应于消费者逻辑队列,为什么要将一个topic抽象出很多的queue呢?这样的话,对集群模式更有好处,可以使多个消费者共同消费,而不用上锁;
对应于consumeQueueTable
offset: CommitLog中的物理位移
size: CommitLog中的日志大小
tagsCode:和storeTimestamp相关
2. ConsumeQueue创建过程:
1. 首先会创建CommitLog,在将数据写入CommitLog之后,会创建DispatchRequest,调用defaultMessageStore.putDispatchRequest
2. DispatchMessageService调用putMessagePostionInfo将数据写入ConsumeQueue
3.3 IndexService(索引)
IndexService用于创建索引文件集合,当用户想要查询某个topic下某个key的消息时,能够快速响应,这里的key是发送消息时,在其propety字段中的keys值,以空格分割的每个关键字都会产生一个索引;同时,如果propety字段中包含UNIQ_KEY时,也会为他创建一个索引。这里注意不要与上述的ConsumeQueue混合,ConsumeQueue只是为了抽象出多个queue,方便并发情况下,用户put/get消息,而这个是为了通过关键字快速定位消息。
服务的启动参见
IndexService由一系列的IndexFile文件组成:
// 索引文件集合
private final ArrayList
1. IndexFile的结构:
IndexFile的格式如下所示:
其中的hashslot字段如果对应是0,则表示到尾部。
其中:
A. IndexHeader的结构如下
beginTimestamp = new AtomicLong(0);
endTimestamp = new AtomicLong(0);
beginPhyOffset = new AtomicLong(0);
endPhyOffset = new AtomicLong(0);
hashSlotCount = new AtomicInteger(0); // 已经使用的hashslot的个数
indexCount = new AtomicInteger(1);B. HashSlot里面的每一项保存了这个topic-key计算出的hash的Index,所有的链表,所以他的每个大小是4字节,一共有500W项
C.Index的结构如下:

keyHash:topic-key(key是消息的key)的hashCode组成
phyOffset:commitLog真实的物理位移
timeOffset:时间位移
slotValue:下一个记录的slot位置
2. IndexFile的创建过程:
1. 首先在DispatchMessageService写入ConsumeQueue后,会再调用indexService.putRequest,创建索引请求
2. 调用IndexService的buildIndex创建索引
3.4 HAService(主从复制模块)
他的启动有3个部分:
3.4.1AcceptSocketService:作为HAServer进行监听
beginAccept,start;主要就是在socketAddressListen监听Slave的请求服务,如果有请求进入,新建HAConnection,并start;同时将其加入到HAService的connectionList中
3.4.2HAConnection:用于管理Master接收的连接,readSocketService和writeSocketService分别启动;
有slaveRequestOffset和slaveAckOffset两个变量:
slaveRequestOffset:它只使用一次,即第一次slave发送给master时,表示slave请求的起始offset;
slaveAckOffset:由slave上传到master,表示其确认接收到的offset
A. ReadSocketService:接收处理slave的请求
首先接收到slave的请求后,slave的请求是一个8字节的Long:
先判断slaveRequestOffset是否小于0,小于0则表示第一次请求,将slaveRequestOffset置为此值,需要从这个位置进行commitLog拉取;
否则将slaveAckOffset置为slave请求的offset,表示确认接收到该请求;
再调用notifyTransferSome(slaveAckOffset)
B. WriteSocketService:发送给slave物理数据CommitLog
A. 初始化:如果nextTransferFromWhere=-1,则表示是第一次传输;slaveRequestOffset如果也为0,表示slave上面没有数据,直接从master的最后一个文件开始上传,将nextTransferFromWhere置为最后一个文件的位移;如果slaveRequestOffset不为0,则从slave请求的位置开始传输;
B. 心跳包:如果本次传输距离上次的时间超过了5S的心跳时间,那么发送心跳包:8(下次传输的位置)+4(固定值0)
C. 数据包:获取从nextTransferFromWhere开始的SelectMapedBufferResult(MapFile,size, startOffset);如果size大于传输的BatchSize,则设置size为BatchSize;接下来:
设置nextTranserFromWhere;
设置byteBufferHeader设置头部:8(传输的offset)+4(内容长度)
调用transferData()传输数据:首先传输头部,再根据selectMapedBufferResult传输body部分;
如果没有数据,则
WaitNotifyObject:感觉用于多个线程之间的同步
notifyTransferSome(slaveAckOffset)
如果客户端ack的值比当前push2SlaveMaxOffset的值大,那么将push2SLaveMaxOffset的值设置为ack,然后调用groupTranserServer唤起线程
groupTransferService:它用于同步slave-master的模式,当master收到commitLog,同时又是同步复制的情况,就会将Requets放入,随后进行复制
push2SlaveMaxOffset的值为slaveAckOffset
3.4.3HaClient
1. 首先连接到master,同时获取到最大的offset,到currentReportedOffset
2. 向master发送心跳
3. 不断向master发送当前的offset,同时读取master的答复,将master的答复写入commitLog中;如果master的答复不满足我们slave的offset,则关闭与master之间的连接3.5 上述三个模块的启动
当store模块启动时,会启动一个后台服务ReputMessageService,这个服务会定时调用根据commitLog产生的数据,发送DispatchRequest到CommitLogDispatcherBuildConsumeQueue,CommitLogDispatcherBuildIndex,CommitLogDispatcherCalcBitMap这三个模块中,这三个模块分别产生上述描述的数据写到磁盘中。
四、后台非实时模块
4.1 FlushConsumeQueueService:用于将ConsumeQueue的File文件写入入里磁盘;
首先判断是否到达了刷盘时间,如果到达了,那么全盘通刷;
否则,遍历所有的ConsumeQueue,调用cq.commit(flushConsumeQueueLeastPages)进行刷盘,flushConsumeQueueLeastPages是目前文件的未刷盘大小达到flushConsumeQueueLeastPages*OS_PAGE_SIZE(1024*4)个,才进行刷盘
4.2 CleanCommitLogService:用于定期删除CommitLog的物理文件;
如果到达删除时间或者磁盘大小达到阈值:
文件保存时长:72小时
删除文件间隔时间:100ms
强制删除文件间隔时间:1000* 120ms
一次最多删除文件数:10个
4.3 CleanConsumeQueueService
获取commitLog的最小offset,遍历所有的consumeQueue,将小于offset的consumeQueue删除;
同时遍历IndexFile,将offset小于commitLog的索引删除
4.4 DispatchMessageService:这个服务主要是处理DispatchRequest,当写入CommitLog后,会将Dispatch请求写入Queue,然后该服务进行ConsumeQueue和IndexService的写入
4.5 AllocateMapedFileService:包含在MapedFileQueue中,主要用于每次getLastMapedFile(startOffset)时,如果最后一个文件满了,那么调用allocateMapedFileService.putRequestAndReturnMapedFile,将文件创建请求放入allocateMapedFileService的requestTable和requestQueue中,后续会进行文件创建,如果超过5S还没创建,则报错;
4.6 ReputMessageService:这个用于Slave中,当Slave模式时,会启动这个模块,然后首先设置reputFormOffset为初始值0;不断遍历commitLog,得到其SelectMapedBufferResult,然后对每一个Message创建DispatchRequest,创建对应的ConsumeQueue和IndexFile,相关的类如下:CommitLogDispatcherBuildConsumeQueue,CommitLogDispatcherBuildIndex,CommitLogDispatcherCalcBitMap
4.7 ScheduleMessageService:如果设置发送的消息设置了延时多久消费,那么这个任务会将延时到期的任务正式写到mq中
4.8 StoreStatsService:不断统计当前的数据储存状况
4.9 StoreCheckpoint
4.10 BrokerStatsManager:统计broker的使用状况
附:
A.
同步请求的处理方式和异步请求的处理方式统一:
同步请求和异步请求都是将Request放入Queue中,然后再起一个线程进行处理
B. 双缓冲
可以起2个队列,一个读,一个写,这两个队列不断交换;这样可以解决一个问题,写和读不会出现并发问题,不需要上锁,能提高效率,但是仅仅适用于对put顺序没有要求的情况
C. 为什么要逻辑队列:可以使写效率更高
D. I/O通用的设计:
在通讯的io模块,创建map文件的模块,以及这里的刷盘模块,无一不使用了放入后台线程queue中执行的方式,并使用countdown来获取异步执行的结果。这样设计的好处是,io操作的时间始终是不可控的,这种方式在一致性和可用性中取得了平衡。