【LeetCode数据库】 题目总结——经典题目题解与分析(八)--中等难度
刷完了简单和中等难度的数据库题目,对sql中的一些语法特性有了简单的了解,算是学会了挺多思路,还有很多的小技巧
总之就是感觉使用sql能完成的任务越来越多了,能解决的业务场景也也越来越复杂了。有许多之前不得不拿到程序中才能处理的数据使用简单的sql就能够达成,当事人就很有成就感。
所以刷题整理这个过程还会持续下去,从这篇博文开始,就是中等难度的了,由于题目较长或者题解较简单稍微复杂。所以为了避免每篇博文过于冗长,暂定是5-6道题一篇。会挑选博主觉得比较有意义的题目(根据博主不算高的水平)
往期的题解会放在最后,欢迎阅览、交流、讨论。
最后一个能进入电梯的人
题目链接
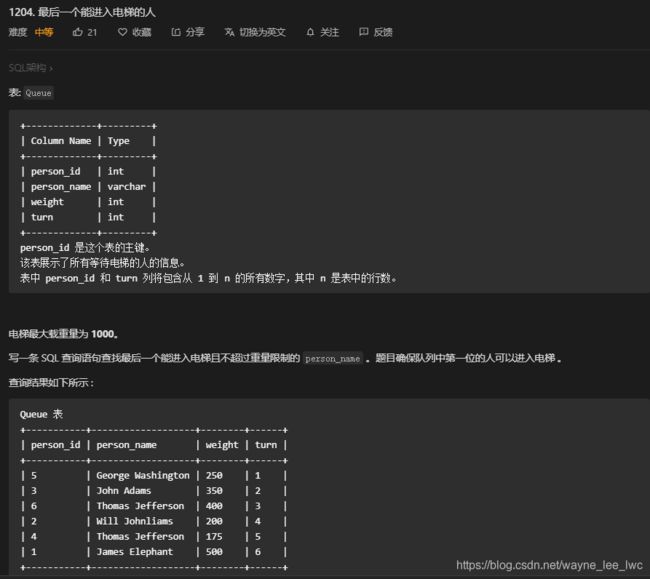

这道题需要我们统计最后一个能上电梯的人,每个人按照排队顺序进入电梯,每个人都有体重,电梯有限重。
既然要统计最后一个能上电梯的人,那我们就先统计所有能上电梯的人,使用自连接,将所有序号小于等于自己的人联结起来,分组后就能统计出轮到每个人时的总重量。筛选出总重量小于等于电梯限重(1000)的所有人。
选出所有人之后我们只需要按照顺序降序排序,然后取第一个就是最后一个能上电梯的人了。
# Write your MySQL query statement below
select
a.person_name
from
queue a
left join queue b on a.turn >= b.turn
group by
a.person_id
having
sum(b.weight) <= 1000
order by
sum(b.weight) desc
limit 0,1
;
每月交易II
题目链接


这道题需要我们统计每个国家或地区每月的已批准的订单数量和总和以及退单的数量和总和
仔细观察不难发现,这两部分内容其实关系不是很大,已批准的订单信息在事务表中,退单的信息在退单表中。
于是我们可以考虑分开查询这些信息,然后再将它们联结起来。但是这样的联结有一个问题,就是两个问题的集合并不是相等或者包含的关系,各自会有不属于对方集合的元素,所以如果使用内联结或者外联结的话会出现数据丢失的问题。所以我们需要更换一下思路
类似的,我们还可以使用另一种思路,将这些信息筛选出来后按照统一格式使用union将它们联合起来,同时打上标记,再根据标记分别进行分组。
select
month,
country,
count(if(tag = 'approved',1,null)) as approved_count,
sum(if(tag = 'approved',amount,0)) as approved_amount,
count(if(tag = 'chargeback',1,null)) as chargeback_count,
sum(if(tag = 'chargeback',amount,0)) as chargeback_amount
from
(
select
left(trans_date,7) as month,
country,
amount,
'approved' as tag
from
transactions
where
state = 'approved'
union all
select
left(c.trans_date,7) as month,
country,
amount,
'chargeback' as tag
from
chargebacks c
left join transactions t on c.trans_id = t.id
) temp
group by
country,month
查询球队积分
题目链接

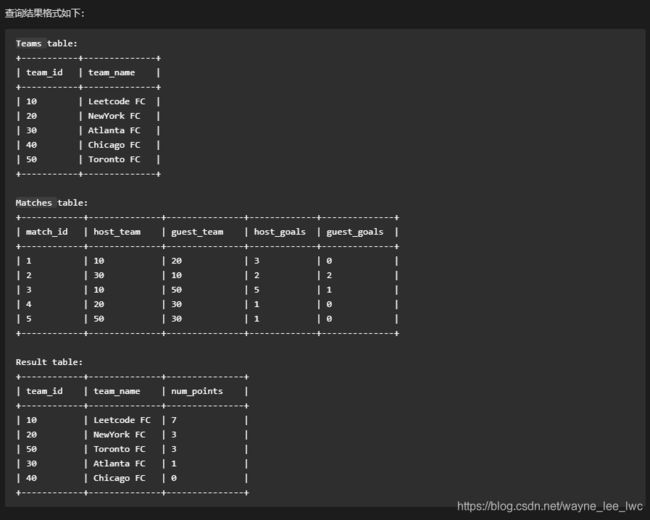
这道题,需要统计一下各个球队的得分情况。
不难发现,球队的所有比赛可能是客场或者是主场,这导致统计上出现了一定的问题。
那我们就缓一步,分别求出每场的客场和主场的得分情况,统集成(球队,得分)的格式在使用union all将他们链接在一起。
最后对这个统计了每场比赛每支球队的表,分组统计得分即可。记得处理null!
# Write your MySQL query statement below
select
team_id,
team_name,
ifnull(sum(temp.goals),0) as num_points
from
teams t
left join (
select
host_team as team,
(
case
when host_goals > guest_goals then 3
when host_goals = guest_goals then 1
else 0
end
) as goals
from
matches
union all
select
guest_team as team,
(
case
when host_goals < guest_goals then 3
when host_goals = guest_goals then 1
else 0
end
) as goals
from
matches
)as temp on temp.team = t.team_id
group by
team_id
order by
num_points desc,team_id
向公司CEO汇报工作的所有人
题目链接


这道题需要我们统计所有向ceo汇报工作的人,考虑到公司的人员结构是树形的,因此这道题其实就是查询以ceo为根的树中的所有节点。
如果这个题目出现在算法题中,那么直接直接遍历整棵树即可。但是现在它是一道数据库题目。好在题目限定这种传递关系深度不超过3。
所以我们只需要自连接三次,并且抽取其中每一层的节点即可。
# Write your MySQL query statement below
select
e4.employee_id
from
employees e1,
employees e2,
employees e3,
employees e4
where
e1.employee_id = 1
and
e2.employee_id != 1
and
e2.manager_id = 1
and
e3.manager_id = e2.employee_id
and
e4.manager_id = e3.employee_id
union
select
e3.employee_id
from
employees e1,
employees e2,
employees e3
where
e1.employee_id = 1
and
e2.employee_id != 1
and
e2.manager_id = 1
and
e3.manager_id = e2.employee_id
union
select
e2.employee_id
from
employees e1,
employees e2
where
e1.employee_id = 1
and
e2.employee_id != 1
and
e2.manager_id = 1
找到连续区间的开始和结束数字
题目链接


这道题非常的有意思,也很值得思考。
要完成这道题,我们需要仔细思考一个区间的起始和结尾都有什么特点。
不难发现,如果一个连续的序列在某个地方因为删除了一系列的数字变成了两个区间。
那么前面区间的末尾后一个元素和后面区间的开头的前一个元素都会缺失
举个粟子:123 567中,3后面的4缺失了,5前面的4缺失了,所以他们一个是末尾,一个是开头。
值得庆幸的是,第一个区间的开头和最后一个区间的末尾也满足这个条件,长度为1的区间也满足这个条件。
于是我们可以放心大胆的筛选出比自己小一的值不存在的元素作为开头,选出比自己大一的值不存在的元素作为结尾。
最后,按照末尾一定大于等于开头的性质进行联结并进行分组,拿出每个末尾中最大的开头即可。
# Write your MySQL query statement below
select
a.id as start_id,
min(b.id) as end_id
from
(
select
log_id as id
from
logs
where
log_id - 1 not in (select * from logs)
) as a,
(
select
log_id as id
from
logs
where
log_id + 1 not in (select * from logs)
) as b
where
a.id <= b.id
group by
a.id
order by
a.id
- 题目总结——经典题目题解与分析(一)–简单
- 题目总结——经典题目题解与分析(二)–简单
- 题目总结——经典题目题解与分析(三)–简单
- 题目总结——经典题目题解与分析 (四)–中等
- 题目总结——经典题目题解与分析 (五)–中等
- 题目总结——经典题目题解与分析 (六)–中等
- 题目总结——经典题目题解与分析(七)–中等