【鲁班学院】面试总结:Java高级篇(上):集合的类型以及重新认识HashMap
1.你用过哪些集合类?
大公司最喜欢问的Java集合类面试题
40个Java集合面试问题和答案
java.util.Collections 是一个包装类。它包含有各种有关集合操作的静态多态方法。
java.util.Collection 是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
Map
├Hashtable
├HashMap
└WeakHashMap
ArrayList、HashMap、TreeMap和HashTable类提供对元素的随机访问。
(1)线程安全
Vector
HashTable(不允许插空值)
(2)非线程安全
ArrayList
LinkedList
HashMap(允许插入空值)
HashSet
TreeSet
TreeMap(基于红黑树的Map实现)
2.你说说 arraylist 和 linkedlist 的区别?
ArrayList和LinkedList两者都实现了List接口,但是它们之间有些不同。
1、ArrayList是由Array所支持的基于一个索引的数据结构,所以它提供对元素的随机访问。
2、与ArrayList相比,在LinkedList中插入、添加和删除一个元素会更快。
3、LinkedList比ArrayList消耗更多的内存,因为LinkedList中的每个节点存储了前后节点的引用。
3.HashMap 底层是怎么实现的?还有什么处理哈希冲突的方法?
处理哈希冲突的方法:
解决HashMap一般没有什么特别好的方式,要不扩容重新hash要不优化冲突的链表结构。
1.开放定地址法-线性探测法
2.开放定地址法-平方探查法
3.链表解决-可以用红黑树提高查找效率
HashMap简介: HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。 HashMap
继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。 HashMap
的实现不是同步的,这意味着它不是线程安全的,但可以用
Collections的synchronizedMap方法使HashMap具有线程安全的能力。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
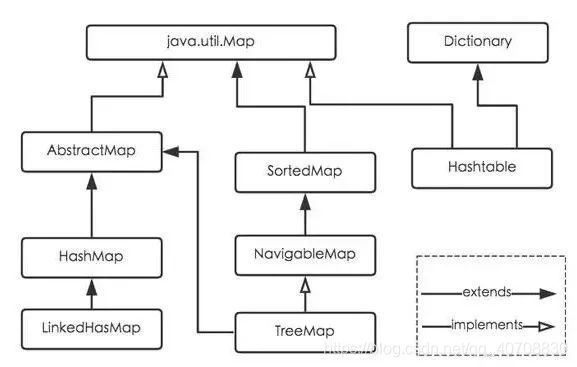
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。
初始容量默认是16。默认加载因子是 0.75,这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本。HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,当链表长度太长(默认超过8)时,链表就转换为红黑树。
4.Java8系列之重新认识HashMap
功能实现-方法:
1、确定哈希桶数组索引位置 :这里的Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算。
方法一:static final int hash(Object key) { //jdk1.8 & jdk1.7int h;// h = key.hashCode() 为第一步 取hashCode值// h ^ (h >>> 16) 为第二步 高位参与运算return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
方法二:static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的return h & (length-1); //第三步 取模运算}
1.分析HashMap的put方法
2.扩容机制:原来的两倍
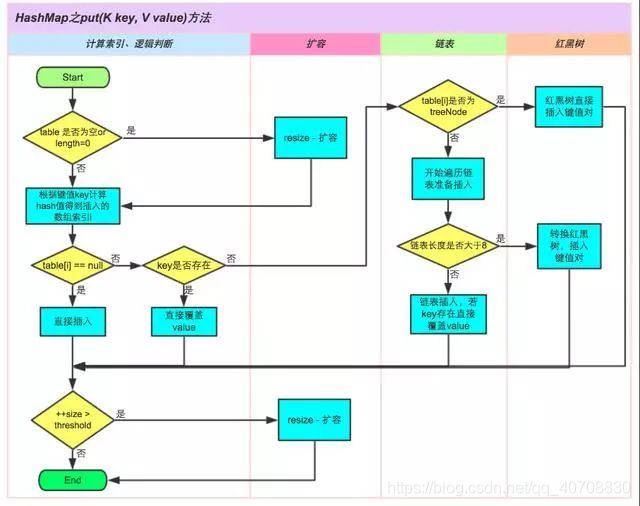
4.熟悉什么算法,还有说说他们的时间复杂度?
经典排序算法总结与实现
5.ArrayList和Vector的底层代码和他们的增长策略,它们是如何进行扩容的?
ArrayList 默认数组大小是10,其中ensureCapacity扩容,trimToSize容量调整到适中,扩展后数组大小为((原数组长度1.5)与传递参数中较大者。
Vector的扩容,是可以指定扩容因子,同时Vector扩容策略是:1.原来容量的2倍,2.原来容量+扩容参数值。(*详细内容可以配合阅读源码)
6.jvm 原理,程序运行区域划分
问:Java运行时数据区域? 回答:包括程序计数器、JVM栈、本地方法栈、方法区、堆。 问:方法区里存放什么?
本地方法栈:和jvm栈所发挥的作用类似,区别是jvm栈为jvm执行java方法(字节码)服务,而本地方法栈为jvm使用的native方法服务。
JVM栈:局部变量表、操作数栈、动态链接、方法出口。 方法区:用于存储已被虚拟机加载的类信息,常量、静态变量、即时编译器编译后的代码等。
堆:存放对象实例。
7.minor GC 与 Full GC,分别什么时候会触发? 分别采用哪种垃圾回收算法?简单介绍算法。
GC(或Minor GC):收集 生命周期短的区域(Young area)。
Full GC (或Major GC):收集生命周期短的区域(Young area)和生命周期比较长的区域(Old area)对整个堆进行垃圾收集。
新生代通常存活时间较短基于Copying算法进行回收,将可用内存分为大小相等的两块,每次只使用其中一块;当这一块用完了,就将还活着的对象复制到另一块上,然后把已使用过的内存清理掉。在HotSpot里,考虑到大部分对象存活时间很短将内存分为Eden和两块Survivor,默认比例为8:1:1。代价是存在部分内存空间浪费,适合在新生代使用。
老年代与新生代不同,老年代对象存活的时间比较长、比较稳定,因此采用标记(Mark)算法来进行回收,所谓标记就是扫描出存活的对象,然后再进行回收未被标记的对象,回收后对用空出的空间要么进行合并、要么标记出来便于下次进行分配,总之目的就是要减少内存碎片带来的效率损耗。
在执行机制上JVM提供了串行GC(Serial MSC)、并行GC(Parallel MSC)和并发GC(CMS)。
Minor GC ,Full GC 触发条件
Minor GC触发条件:当Eden区满时,触发Minor GC。
Full GC触发条件:
1、调用System.gc时,系统建议执行Full GC,但是不必然执行。
2、老年代空间不足。
3、方法去空间不足。
4、通过Minor GC后进入老年代的平均大小大于老年代的可用内存。
5、由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。
8.HashMap 实现原理
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
9.java.util.concurrent 包下使用过哪些
(1).阻塞队列
BlockingQueue( ArrayBlockingQueue, DelayQueue, LinkedBlockingQueue,SynchronousQueue,LinkedTransferQueue,LinkedBlockingDeque)
(2).ConcurrentHashMap
(3).Semaphore–信号量
(4) .CountDownLatch–闭锁
(5).CyclicBarrier–栅栏
(6).Exchanger–交换机
(7).Executor-
>ThreadPoolExecutor,ScheduledThreadPoolExecutor
Semaphore semaphore = new Semaphore(1);//critical section semaphore.acquire();...semaphore.release();
8.锁
Lock–ReentrantLock,ReadWriteLock,Condition,LockSupport
Lock lock = new ReentrantLock();lock.lock();//critical section lock.unlock();
9.concurrentMap 和 HashMap 区别
1.hashMap可以有null的键,concurrentMap不可以有
2.hashMap是线程不安全的,在多线程的时候需要Collections.synchronizedMap(hashMap),ConcurrentMap使用了重入锁保证线程安全。
3.在删除元素时候,两者的算法不一样。 ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁,可以简单理解成把一个大的HashTable分解成多个,形成了锁分离。
10.信号量是什么,怎么使用?volatile关键字是什么?
信号量-semaphore:荷兰著名的计算机科学家Dijkstra 于1965年提出的一个同步机制。是在多线程环境下使用的一种设施,
它负责协调各个线程, 以保证它们能够正确、合理的使用公共资源。整形信号量:表示共享资源状态,且只能由特殊的原子操作改变整型量。
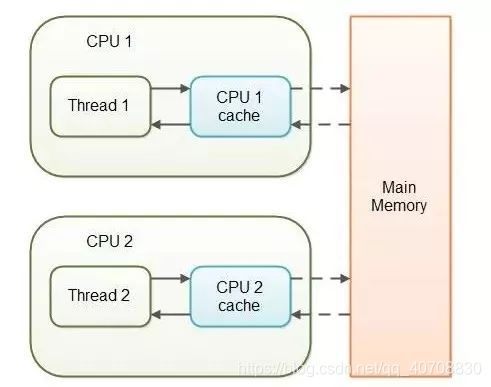
同步与互斥:同类进程为互斥关系(打印机问题),不同进程为同步关系(消费者生产者)。使用volatile关键字是解决同步问题的一种有效手段。 java
volatile关键字预示着这个变量始终是“存储进入了主存”。更精确的表述就是每一次读一个volatile变量,都会从主存读取,而不是CPU的缓存。同样的道理,每次写一个volatile变量,都是写回主存,而不仅仅是CPU的缓存。
Java 保证volatile关键字保证变量的改变对各个线程是可见的。
11.阻塞队列了解吗?怎么使用?
阻塞队列 (BlockingQueue)是Java
util.concurrent包下重要的数据结构,BlockingQueue提供了线程安全的队列访问方式:当阻塞队列进行插入数据时,如果队列已满,线程将会阻塞等待直到队列非满;从阻塞队列取数据时,如果队列已空,线程将会阻塞等待直到队列非空。并发包下很多高级同步类的实现都是基于BlockingQueue实现的。

以ArrayBlockingQueue为例,我们先来看看代码:
public void put(E e) throws InterruptedException {if (e == null) throw new
NullPointerException();final ReentrantLock lock = this.lock;lock.lockInterruptibly();try
{while (count == items.length)notFull.await();enqueue(e);} finally {lock.unlock();}}
从put方法的实现可以看出,它先获取了锁,并且获取的是可中断锁,然后判断当前元素个数是否等于数组的长度,如果相等,则调用notFull.await()进行等待,当被其他线程唤醒时,通过enqueue(e)方法插入元素,最后解锁。
/*** Inserts element at current put position, advances, and signals.* Call only when
holding lock.*/private void enqueue(E x) {// assert lock.getHoldCount() == 1;// assert items[putIndex] == null;final Object[]
items = this.items;items[putIndex] = x;if
(++putIndex == items.length) putIndex = 0;count++;notEmpty.signal();}
插入成功后,通过notEmpty唤醒正在等待取元素的线程。
12.Java中的NIO,BIO,AIO分别是什么?
IO的方式通常分为几种,同步阻塞的BIO、同步非阻塞的NIO、异步非阻塞的AIO
1.BIO,同步阻塞式IO,简单理解:一个连接一个线程.BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
在JDK1.4之前,用Java编写网络请求,都是建立一个ServerSocket,然后,客户端建立Socket时
就会询问是否有线程可以处理,如果没有,要么等待,要么被拒绝。即:一个连接,要求Server 对应一个处理线程。
2.NIO,同步非阻塞IO,简单理解:一个请求一个线程.NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题:
在使用同步I/O的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。也就是说,将每一个客户端请求分配给一个线程来单独处理。这样做虽然可以达到我们的要求,但同时又会带来另外一个问题。
由于每创建一个线程,就要为这个线程分配一定的内存空间(也叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程序可能会因为不堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪。
3.AIO,异步非阻塞IO,简单理解:一个有效请求一个线程.AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
13.类加载机制是怎样的?
JVM中类的装载是由ClassLoader和它的子类来实现的,Java
ClassLoader是一个重要的Java运行时系统组件。它负责在运行时查找和装入类文件的类。
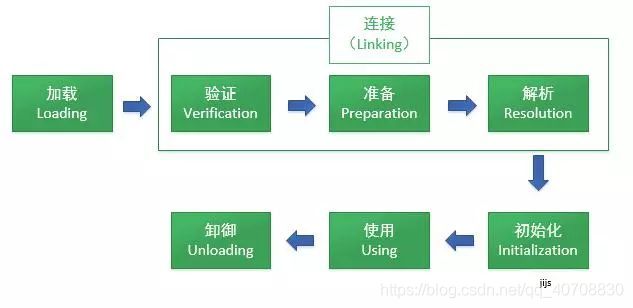
类加载的五个过程:加载、验证、准备、解析、初始化。
从类被加载到虚拟机内存中开始,到卸御出内存为止,它的整个生命周期分为7个阶段,加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)、卸御(Unloading)。其中验证、准备、解析三个部分统称为连接。
14.什么是幂等性?
所谓幂等,简单地说,就是对接口的多次调用所产生的结果和调用一次是一致的。
那么我们为什么需要接口具有幂等性呢?设想一下以下情形:
•在App中下订单的时候,点击确认之后,没反应,就又点击了几次。在这种情况下,如果无法保证该接口的幂等性,那么将会出现重复下单问题。
•在接收消息的时候,消息推送重复。如果处理消息的接口无法保证幂等,那么重复消费消息产生的影响可能会非常大。
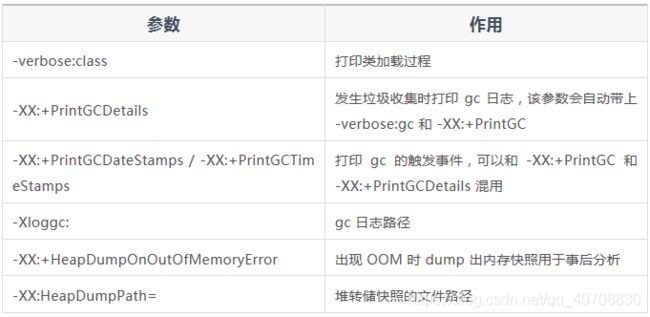
15.有哪些 JVM 调优经验?
Jvm参数总结:http://linfengying.com/?p=2470
◾内存参数

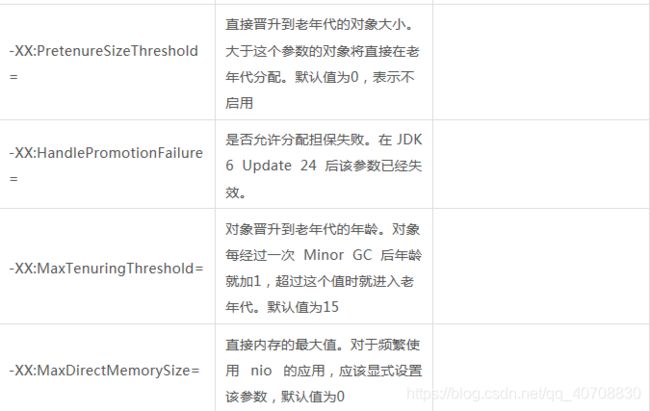

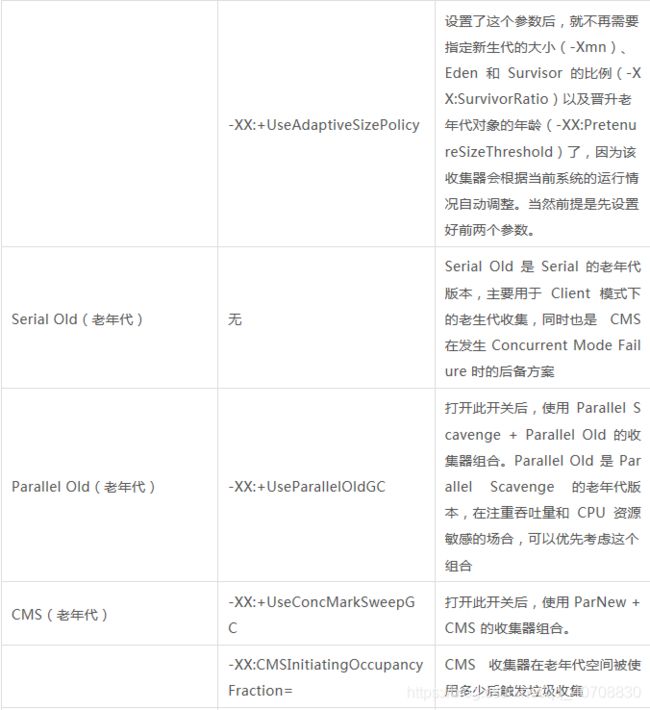
上面有7中收集器,分为两块,上面为新生代收集器,下面是老年代收集器。如果两个收集器之间存在连线,就说明它们可以搭配使用。
16.分布式 CAP 了解吗?
一致性(Consistency)
可用性(Availability)
分区容忍性(Partition tolerance)
17.Java中HashMap的key值要是为类对象则该类需要满足什么条件?
需要同时重写该类的hashCode()方法和它的equals()方法。
当程序试图将一个 key-value 对放入 HashMap 中时,程序首先根据该 key 的 hashCode() 返回值决定该
Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。
如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry
的 value,但 key 不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成
Entry 链,而且新添加的 Entry 位于 Entry 链的头部——具体说明继续看 addEntry() 方法的说明。
18.java 垃圾回收会出现不可回收的对象吗?怎么解决内存泄露问题?怎么定位问题源?
一般不会有不可回收的对象,因为现在的GC会回收不可达内存。
19.终止线程有几种方式?终止线程标记变量为什么是 valotile 类型?
1.线程正常执行完毕,正常结束
2.监视某些条件,结束线程的不间断运行
3.使用interrupt方法终止线程
在定义exit时,使用了一个Java关键字volatile,这个关键字的目的是使exit同步,也就是说在同一时刻只能由一个线程来修改exit的值。
21.用过哪些并发的数据结构? cyclicBarrier 什么功能?信号量作用?数据库读写阻塞怎么解决?
•主要有锁机制,然后基于CAS的concurrent包。
•CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。
CyclicBarrier默认的构造方法是CyclicBarrier(int
parties),其参数表示屏障拦截的线程数量,每个线程调用await方法告诉CyclicBarrier我已经到达了屏障,然后当前线程被阻塞。•CountDownLatch的计数器只能使用一次。而CyclicBarrier的计数器可以使用reset() 方法重置。
•Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。
很多年以来,我都觉得从字面上很难理解Semaphore所表达的含义,只能把它比作是控制流量的红绿灯,比如XX马路要限制流量,只允许同时有一百辆车在这条路上行使,其他的都必须在路口等待,所以前一百辆车会看到绿灯,可以开进这条马路,后面的车会看到红灯,不能驶入XX马路,但是如果前一百辆中有五辆车已经离开了XX马路,那么后面就允许有5辆车驶入马路。
这个例子里说的车就是线程,驶入马路就表示线程在执行,离开马路就表示线程执行完成,看见红灯就表示线程被阻塞,不能执行。