idea远程调试setJars设置及遇到的问题java.lang.ClassNotFoundException: XXX$$anonfun$2
在这个过程中遇到的错误
Master: Got status update for unknown executor app-20191108092736-0010/0
SparkException: Could not find CoarseGrainedScheduler.
spark WARNTaskSchedulerImpl:Initial job has not accepted any resources; check your cluster UI to
WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, worker1): java.lang.ClassNotFoundException: com.spark.firstApp.HelloSpark$$anonfun$2
【把IDEA当做你的Driver来运行,保持和整个Spark集群的连接关系】
当以idea作为driver端时,就需要将写好的程序打包,复制路径,
然后在原来的打包的程序设置setJars 和 setIfMissing (
设置driver 即windows的映射原因是 worker找不到driver
猜想,idea作为driver向master提交作业信息,master去通知并启动worker,可能只是告诉worker,有个driver名字叫xxx,有个任务需要你对接一下,worker就去找这个名字对应的主机,可是worker的本机映射没有xxx所对应的ip地址,怎么找?
所以要设置这个),这样worker才能找到driver端,告诉driver,我这个worker启动好了,你把jar包发给我吧。就这样。
所以说到这还有另外一种解决办法,在worker机子配置idea端即windows的的host映射也能解决问题
还有要注意的:别忘了设置master
还有 注意setJars里面是个List("") 不要光填路径
还有设置本机的IP地址要和集群的IP地址要在同网段
1.刚开始idea没有报错,就一直在响应 resources 这个就是映射找不到
两种解决办法 .setIfMissing(“spark.driver.host”, “192.168.37.1”) 注意网段跟虚拟机一致 设置windows的映射
2.在三台虚拟机配置windows映射

两种都可以 我都配上了

3.然后就报类找不到的错误,测试了一下 是没有将依赖打进去,普通打包是40M,
在pom里面加上下面的build 有警告,不过一样用,打完包100M
然后就可以了。
4.步骤就是先打开注释的那句话,就是先不设置setJars 、setIfMissing 先打包
然后再设置这个 将打好的jar路径加上 映射加上
再运行。
5.还有要注意 写的读取存取文件的路径要是hdfs路径 不能是windows路径了
虚拟机地址192.168.37.xxx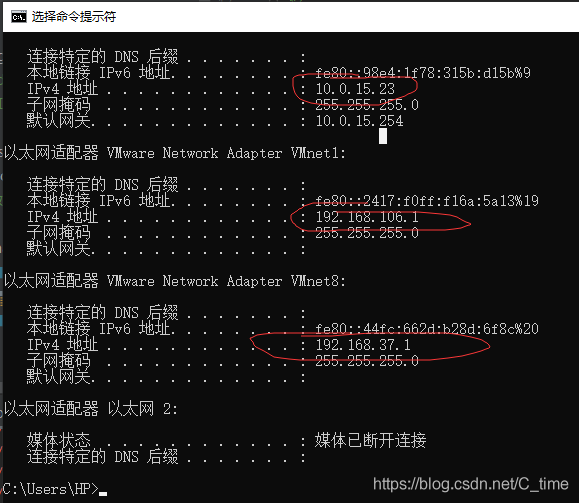
windows地址 192.168.37.1
要同一个网段


<build>
<sourceDirectory>src/main/scalasourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.4.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>mainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
package exercise
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.joda.time.DateTime
/**
* 数据格式: timestamp province city userid adid
* 时间点 省份 城市 用户 广告
*
* 用户ID范围:0-99
* 省份,城市,ID相同:0-9
* adid:0-19
*
*
* //需求:统计每一个省份每一个小时的TOP3广告ID
*/
object Peo_Hour_AD_TopN {
def main(args: Array[String]): Unit = {
// val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[2]")
// val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("spark://hadoop01:7077")
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("spark://hadoop01:7077")
.setJars(List("C:\\Users\\HP\\IdeaProjects\\sparkCore\\target\\sparkCore-1.0-SNAPSHOT.jar"))
.setIfMissing("spark.driver.host", "192.168.37.1")
val sc = new SparkContext(conf)
// val res: RDD[String] = sc.textFile("/sparkdata/Advert.log")
//Exception in thread "main" java.lang.IllegalArgumentException: Pathname /D:/Program Files/feiq/Recv Files/sparkcoursesinfo/spark/data/advert/Advert.log from
// hdfs://qf/D:/Program Files/feiq/Recv Files/sparkcoursesinfo/spark/data/advert/Advert.log is not a valid DFS filename.
// val splited: RDD[(String, Int)] = sc.textFile("D:\\Program Files\\feiq\\Recv Files\\sparkcoursesinfo\\spark\\data\\advert\\Advert.log")
//本地路径读取文件会出错,因为jar包已经传到worker woker是要去hdfs上找读取的文件的
val splited: RDD[(String, Int)] = sc.textFile("/sparkdata/Advert.log")
.map(line => {
val arr = line.split("\t")
val timestamp = arr(0)
val hour = new DateTime(timestamp.toLong).getHourOfDay.toString
val province = arr(1)
val adid = arr(4)
((hour + "_" + province + "_" + adid), 1)
})
//聚合计算点击次数
val reduced: RDD[(String, Int)] = splited.reduceByKey(_+_)
//整合数据粒度
val pro_hour_adid_count: RDD[(String, (String, Int))] = reduced.map(tup => {
val arr: Array[String] = tup._1.split("_")
(arr(1) + "_" + arr(0), (arr(0), tup._2)) //(pro_hour,(adid,count))
})
//按照省份和小时分组
val grouped: RDD[(String, Iterable[(String, Int)])] = pro_hour_adid_count.groupByKey()
//组内降序排序 并取前3
val top3: RDD[(String, List[(String, Int)])] = grouped.mapValues(_.toList.sortWith(_._2 > _._2).take(3))
val res: RDD[(String, String, List[(String, Int)])] = top3.map(tup => {
val array: Array[String] = tup._1.split("_")
val pro = array(0)
val hour = array(1)
val adid_count = tup._2
(pro, hour, adid_count)
})
// println(res.collect.toBuffer)
res.saveAsTextFile("/sparkdata/03")
}
}
19/11/08 10:09:13 WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, 192.168.37.113, executor 1): java.lang.ClassNotFoundException: exercise.Peo_Hour_AD_TopN$$anonfun$2
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.resolveClass(JavaSerializer.scala:67)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1868)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1751)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2042)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:75)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:114)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:85)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
19/11/08 10:09:13 INFO TaskSetManager: Starting task 1.1 in stage 0.0 (TID 2, 192.168.37.113, executor 1, partition 1, ANY, 4842 bytes)
19/11/08 10:09:14 INFO TaskSetManager: Lost task 1.1 in stage 0.0 (TID 2) on 192.168.37.113, executor 1: java.lang.ClassNotFoundException (exercise.Peo_Hour_AD_TopN$$anonfun$2) [duplicate 1]
19/11/08 10:09:14 INFO TaskSetManager: Starting task 1.2 in stage 0.0 (TID 3, 192.168.37.113, executor 1, partition 1, ANY, 4842 bytes)
19/11/08 10:09:14 INFO TaskSetManager: Lost task 1.2 in stage 0.0 (TID 3) on 192.168.37.113, executor 1: java.lang.ClassNotFoundException (exercise.Peo_Hour_AD_TopN$$anonfun$2) [duplicate 2]
19/11/08 10:09:14 INFO TaskSetManager: Starting task 1.3 in stage 0.0 (TID 4, 192.168.37.113, executor 1, partition 1, ANY, 4842 bytes)
19/11/08 10:09:14 INFO TaskSetManager: Lost task 1.3 in stage 0.0 (TID 4) on 192.168.37.113, executor 1: java.lang.ClassNotFoundException (exercise.Peo_Hour_AD_TopN$$anonfun$2) [duplicate 3]
19/11/08 10:09:14 ERROR TaskSetManager: Task 1 in stage 0.0 failed 4 times; aborting job
19/11/08 10:09:14 INFO TaskSchedulerImpl: Cancelling stage 0
19/11/08 10:09:14 INFO TaskSchedulerImpl: Stage 0 was cancelled
19/11/08 10:09:14 INFO DAGScheduler: ShuffleMapStage 0 (map at Peo_Hour_AD_TopN.scala:32) failed in 1.305 s due to Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 4, 192.168.37.113, executor 1): java.lang.ClassNotFoundException: exercise.Peo_Hour_AD_TopN$$anonfun$2
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.resolveClass(JavaSerializer.scala:67)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1868)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1751)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2042)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:75)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:114)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:85)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
19/11/08 10:09:14 INFO DAGScheduler: Job 0 failed: saveAsTextFile at Peo_Hour_AD_TopN.scala:66, took 1.764049 s
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 4, 192.168.37.113, executor 1): java.lang.ClassNotFoundException: exercise.Peo_Hour_AD_TopN$$anonfun$2
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.resolveClass(JavaSerializer.scala:67)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1868)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1751)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2042)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:75)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:114)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:85)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1499)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1487)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1486)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1486)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:814)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:814)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:814)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1714)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1669)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1658)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:630)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2022)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2043)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2075)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply$mcV$sp(PairRDDFunctions.scala:1151)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply(PairRDDFunctions.scala:1096)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply(PairRDDFunctions.scala:1096)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:362)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopDataset(PairRDDFunctions.scala:1096)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply$mcV$sp(PairRDDFunctions.scala:1070)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply(PairRDDFunctions.scala:1035)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply(PairRDDFunctions.scala:1035)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:362)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:1035)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply$mcV$sp(PairRDDFunctions.scala:961)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply(PairRDDFunctions.scala:961)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply(PairRDDFunctions.scala:961)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:362)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:960)
at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply$mcV$sp(RDD.scala:1489)
at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply(RDD.scala:1468)
at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply(RDD.scala:1468)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:362)
at org.apache.spark.rdd.RDD.saveAsTextFile(RDD.scala:1468)
at exercise.Peo_Hour_AD_TopN$.main(Peo_Hour_AD_TopN.scala:66)
at exercise.Peo_Hour_AD_TopN.main(Peo_Hour_AD_TopN.scala)
Caused by: java.lang.ClassNotFoundException: exercise.Peo_Hour_AD_TopN$$anonfun$2
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.resolveClass(JavaSerializer.scala:67)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1868)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1751)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2042)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:75)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:114)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:85)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)