维数灾难问题及数据分析中的降维方法
维数灾难问题及数据分析中的降维方法
- 一、维数灾难(curse of dimentionality)
- 降维的主要方法
- 1. 投影(Projection)
- 2. 流形学习
- 二、降维方法
- 1. 什么是降维
- 2. 为什么要降维
- 3. PCA主成分分析(Principal components analysis)
- 3.1 PCA算法模型
- 3.2讨论PCA约简前先要讨论向量的表示及基变换 - PCA低损压缩的理论基础
- 3.2.1 内积与投影
- 3.2.2 基
- 3.2.3 基变换的矩阵表 - 基变换是有损的
- 3.2.4 协方差矩阵及优化目标 - 如何找到损失最低的变换基
- 3.3 PCA的限制
- 3.4 基于原生python+numpy实现PCA算法
一、维数灾难(curse of dimentionality)
我们已经习惯生活在一个三维的世界里,以至于当我们尝试想象更高维的空间时,我们的直觉不管用了。即使是一个基本的 4D 超正方体也很难在我们的脑中想象出来(见图 8-1),更不用说一个 200 维的椭球弯曲在一个 1000 维的空间里了。
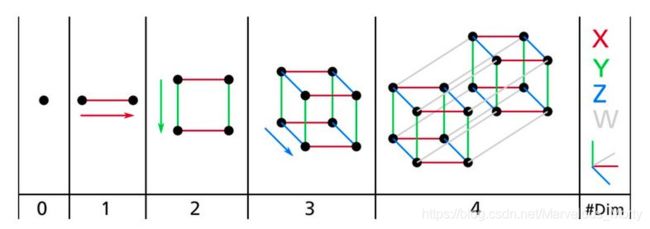
图 8-1 点,线,方形,立方体和超正方体(0D 到 4D 超正方体)
这表明很多物体在高维空间表现的十分不同。比如,如果你在一个正方形单元中随机取一个点(一个1×1的正方形),那么随机选的点离所有边界大于 0.001(靠近中间位置)的概率为 0.4%(1 - 0.998^2)(换句话说,一个随机产生的点不大可能严格落在某一个维度上。但是在一个 1,0000 维的单位超正方体(一个1×1×…×1的立方体,有 10,000 个 1),这种可能性超过了 99.999999%。在高维超正方体中,大多数点都分布在边界处。
还有一个更麻烦的区别:如果你在一个平方单位中随机选取两个点,那么这两个点之间的距离平均约为 0.52。如果您在单位 3D 立方体中选取两个随机点,平均距离将大致为 0.66。但是,在一个 1,000,000 维超立方体中随机抽取两点呢?那么,平均距离,信不信由你,大概为 408.25(大致![]() )这非常违反直觉:当它们都位于同一单元超立方体内时,两点是怎么距离这么远的?这一事实意味着高维数据集有很大风险分布的非常稀疏:大多数训练实例可能彼此远离。当然,这也意味着一个新实例可能远离任何训练实例,这使得预测的可靠性远低于我们处理较低维度数据的预测,因为它们将基于更大的推测(extrapolations)。简而言之,训练集的维度越高,过拟合的风险就越大。
)这非常违反直觉:当它们都位于同一单元超立方体内时,两点是怎么距离这么远的?这一事实意味着高维数据集有很大风险分布的非常稀疏:大多数训练实例可能彼此远离。当然,这也意味着一个新实例可能远离任何训练实例,这使得预测的可靠性远低于我们处理较低维度数据的预测,因为它们将基于更大的推测(extrapolations)。简而言之,训练集的维度越高,过拟合的风险就越大。
理论上来说,维数爆炸的一个解决方案是增加训练集的大小从而达到拥有足够密度的训练集。不幸的是,在实践中,达到给定密度所需的训练实例的数量随着维度的数量呈指数增长。如果只有 100 个特征(比 MNIST 问题要少得多)并且假设它们均匀分布在所有维度上,那么如果想要各个临近的训练实例之间的距离在 0.1 以内,您需要比宇宙中的原子还要多的训练实例。
降维的主要方法
降低维度的两种主要方法:投影和流形学习。
1. 投影(Projection)
在大多数现实生活的问题中,训练实例并不是在所有维度上均匀分布的。许多特征几乎是常数,而其他特征则高度相关(如前面讨论的 MNIST)。结果,所有训练实例实际上位于(或接近)高维空间的低维子空间内。这听起来有些抽象,所以我们不妨来看一个例子。在图 8-2 中,您可以看到由圆圈表示的 3D 数据集。
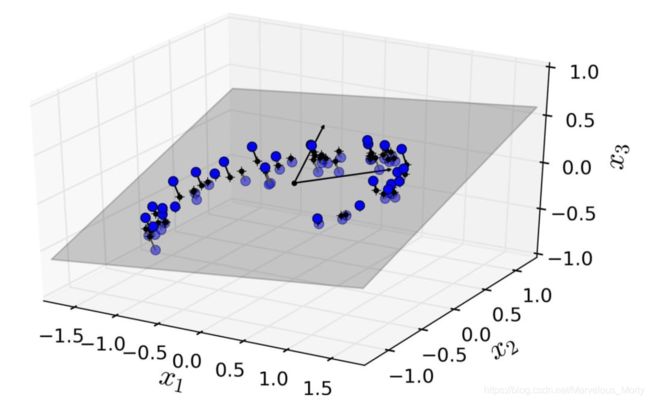
图 8-2 一个分布接近于2D子空间的3D数据集
注意到所有训练实例的分布都贴近一个平面:这是高维(3D)空间的较低维(2D)子空间。现在,如果我们将每个训练实例垂直投影到这个子空间上(就像将短线连接到平面的点所表示的那样),我们就可以得到如图8-3所示的新2D数据集。我们刚刚的操作,将数据集的维度从 3D 降低到了 2D。请注意,坐标轴对应于新的特征z1和z2(平面上投影的坐标)。

图 8-3 一个经过投影后的新的 2D 数据集
但是,投影并不总是降维的最佳方法。在很多情况下,子空间可能会扭曲和转动,比如图 8-4 所示的着名瑞士滚动玩具数据集。

图 8-4 瑞士滚动数玩具数据集
简单地将数据集投射到一个平面上(例如,直接丢弃x3)会将瑞士卷的不同层叠在一起,如图 8-5 左侧所示。但是,你真正想要的是展开瑞士卷所获取到的类似图 8-5 右侧的 2D 数据集。
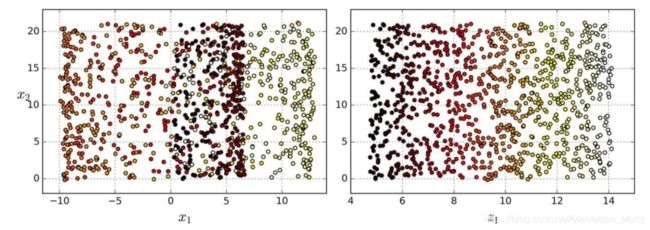
图 8-5 投射到平面的压缩(左)vs 展开瑞士卷(右)
2. 流形学习
瑞士卷一个是二维流形的例子。简而言之,二维流形是一种二维形状,它可以在更高维空间中弯曲或扭曲。更一般地,一个d维流形是类似于d维超平面的n维空间(其中d < n)的一部分。在我们瑞士卷这个例子中,d = 2,n = 3:它有些像 2D 平面,但是它实际上是在第三维中卷曲。
许多降维算法通过对训练实例所在的流形进行建模从而达到降维目的;这叫做流形学习。它依赖于流形猜想(manifold assumption),也被称为流形假设(manifold hypothesis),它认为大多数现实世界的高维数据集大都靠近一个更低维的流形。这种假设经常在实践中被证实。
让我们再回到 MNIST 数据集:所有手写数字图像都有一些相似之处。它们由连线组成,边界是白色的,大多是在图片中中间的,等等。如果你随机生成图像,只有一小部分看起来像手写数字。换句话说,如果您尝试创建数字图像,那么您的自由度远低于您生成任何随便一个图像时的自由度。这些约束往往会将数据集压缩到较低维流形中。
流形假设通常包含着另一个隐含的假设:你现在的手上的工作(例如分类或回归)如果在流形的较低维空间中表示,那么它们会变得更简单。例如,在图 8-6 的第一行中,瑞士卷被分为两类:在三维空间中(图左上),分类边界会相当复杂,但在二维展开的流形空间中(图右上),分类边界是一条简单的直线。
但是,这个假设并不总是成立。例如,在图 8-6 的最下面一行,决策边界位于x1 = 5(图左下)。这个决策边界在原始三维空间(一个垂直平面)看起来非常简单,但在展开的流形中却变得更复杂了(四个独立线段的集合)(图右下)。
简而言之,如果在训练模型之前降低训练集的维数,那训练速度肯定会加快,但并不总是会得出更好的训练效果;这一切都取决于数据集。
希望你现在对于维数爆炸以及降维算法如何解决这个问题有了一定的理解,特别是对流形假设提出的内容。本章的其余部分将介绍一些最流行的降维算法。

图 8-6 决策边界并不总是会在低维空间中变的简单
二、降维方法
1. 什么是降维
降维是将高维数据映射到低维空间的过程,该过程与信息论中有损压缩概念密切相关。同时要明白的,不存在完全无损的降维。
有很多种算法可以完成对原始数据的降维,在这些方法中,降维是通过对原始数据的线性变换实现的。即,如果原始数据是 d 维的,我们想将其约简到 n 维(n < d),则需要找到一个矩阵使得映射。选择 W 的一个最自然的选择的是在降维的同时那能够复原原始的数据 x,但通常这是不可能,区别只是损失多少的问题。
2. 为什么要降维
降维的原因通常有以下几个:
2.1 首先,高维数据增加了运算的难度
2.2 其次,高维使得学习算法的泛化能力变弱(例如,在最近邻分类器中,样本复杂度随着维度成指数增长),维度越高,算法的搜索难度和成本就越大。
2.3 最后,降维能够增加数据的可读性,利于发掘数据的有意义的结构
以一个具体的业务场景来说:
malware detection这种non-linear分类问题中,我们提取的feature往往是sparce high-dimension vector(稀疏高维向量),典型地例如对malware binary的code .text section提取byte n-gram,这个时候,x轴(代码段的byte向量)高达45w,再乘上y轴(最少也是256),直接就遇到了维数灾难问题,导致神经网络求解速度极慢,甚至内存MMO问题。
这个时候就需要维度约简技术,值得注意的是,深度神经网络CNN本身就包含“冗余信息剔除”机制,在完成了对训练样本的拟合之后,网络之后的权重调整会朝着剔除训练样本中的信息冗余目标前进,即我们所谓的信息瓶颈。
Relevant Link:
http://www.tomshardware.com/news/deep-instinct-deep-learning-malware-detection,31079.html
https://www.computerpoweruser.com/article/18961/israeli-company-aims-to-be-first-to-apply-deep-learning-to-cybersecurity
https://www.technologyreview.com/s/542971/antivirus-that-mimics-the-brain-could-catch-more-malware/
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/MalwareRandomProjections.pdf
http://e-nns.org/
https://arxiv.org/pdf/1703.02244.pdf
http://www.dartmouth.edu/~gvc/
http://www.cs.toronto.edu/~gdahl/
3. PCA主成分分析(Principal components analysis)
3.1 PCA算法模型
令 x1,…,xm 为 m 个 d 维向量,我们想利用线性变换对这些向量进行降维。给定矩阵![]() ,则存在映射
,则存在映射![]() ,其中
,其中![]() 是 x 的低维表示。
是 x 的低维表示。
另外,矩阵![]() 能够将压缩后的信息(近似)复原为原始的信号。即,对于压缩向量
能够将压缩后的信息(近似)复原为原始的信号。即,对于压缩向量![]() ,其中 y 在低维空间
,其中 y 在低维空间![]() 中,我们能够构建
中,我们能够构建![]() ,使得
,使得![]() 是 x 的复原版本,处于原始的高维空间
是 x 的复原版本,处于原始的高维空间![]() 中。
中。
在PCA中,我们要找的压缩矩阵 W 和复原矩阵 U 使得原始信号和复原信号在平方距离上最小,即,我们需要求解如下问题:
 ,即尽量无损压缩。
,即尽量无损压缩。
令(U,W)是上式的一个解,则 U 的列是单位正交的(即![]() 是
是![]() 上的单位矩阵)以及
上的单位矩阵)以及![]()
PCA(Principal Component Analysis)是一种常用的数据分析方法。PCA通过线性变换将原始数据变换为一组各维度线性无关(单位正交)的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。
其实“信息瓶颈理论”的核心观点也是认为:所有的信息都是存在冗余的,其需要抽取其中最核心关键的部分就可以大致代表该原始信息。
降维当然意味着信息的丢失,不过鉴于实际数据本身常常存在的相关性,我们可以想办法在降维的同时将信息的损失尽量降低
3.2讨论PCA约简前先要讨论向量的表示及基变换 - PCA低损压缩的理论基础
既然我们面对的数据被抽象为一组向量,那么下面有必要研究一些向量的数学性质。而这些数学性质将成为后续导出PCA的理论基础。
3.2.1 内积与投影
向量运算内积。两个维数相同的向量的内积被定义为,即向量对应的各维度元素两两相乘累加和。
(a1,a2,⋯,an)T⋅(b1,b2,⋯,bn)T=a1b1+a2b2+⋯+anbn
内积运算将两个向量映射为一个实数。其计算方式非常容易理解,但是其意义并不明显。
下面我们分析内积的几何意义。假设A和B是两个n维向量,我们知道n维向量可以等价表示为n维空间中的一条从原点发射的有向线段,为了简单起见我们假设A和B均为二维向量,则A=(x1,y1)则投影的矢量长度为|A|cos(a)注意这里我们专门区分了矢量长度和标量长度,标量长度总是大于等于0,值就是线段的长度;而矢量长度可能为负,其绝对值是线段长度,而符号取决于其方向与标准方向相同或相反。
接着我们将内积表示为另一种我们熟悉的形式:![]() A与B的内积等于:**A到B的投影长度乘以B的模。**再进一步,如果我们假设B的模为1,即让|B|=1,可以看到:设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度
A与B的内积等于:**A到B的投影长度乘以B的模。**再进一步,如果我们假设B的模为1,即让|B|=1,可以看到:设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度
这就是内积的一种几何解释
3.2.2 基
上文说过,一个二维向量可以对应二维笛卡尔直角坐标系中从原点出发的一个有向线段

在代数表示方面,我们经常用线段终点的点坐标表示向量,例如上面的向量可以表示为(3,2),不过我们常常忽略,只有一个(3,2)本身是不能够精确表示一个向量的。我们仔细看一下,这里的3实际表示的是向量在x轴上的投影值是3,在y轴上的投影值是2。
也就是说我们其实隐式引入了一个定义:以x轴和y轴上正方向长度为1的向量为标准。那么一个向量(3,2)实际是说在x轴投影为3而y轴的投影为2。注意投影是一个矢量,所以可以为负。
更正式的说,向量(x,y)实际上表示线性组合
![]()
所有二维向量都可以表示为一定数量的基的线性组合。 此处(1,0)和(0,1)叫做二维空间中的一组基
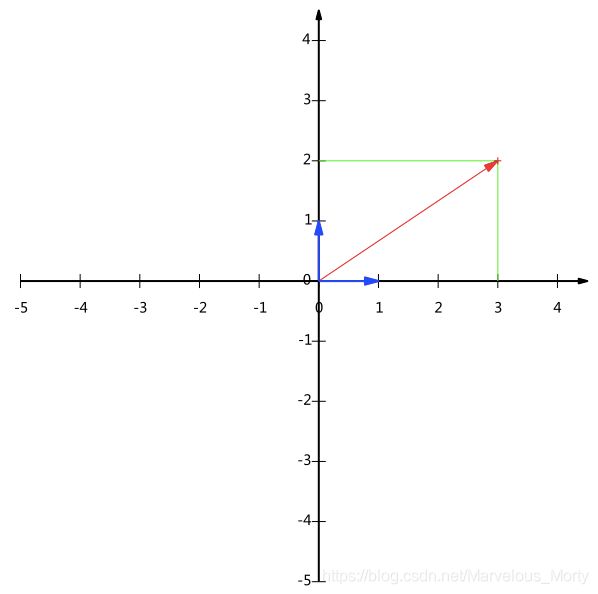
所以,要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。只不过我们经常省略第一步,而默认以(1,0)和(0,1)为基
我们之所以默认选择(1,0)和(0,1)为基,当然是比较方便,因为它们分别是x和y轴正方向上的单位向量,因此就使得二维平面上点坐标和向量一一对应,非常方便。
但实际上任何两个线性无关的二维向量都可以成为一组基(基不一定要正交,正交是一个更强的条件),所谓线性无关在二维平面内可以直观认为是两个不在一条直线上的向量(这个概念非常重要,因为PCA分析中用于降维投影的基常常就不是x/y轴单位向量)
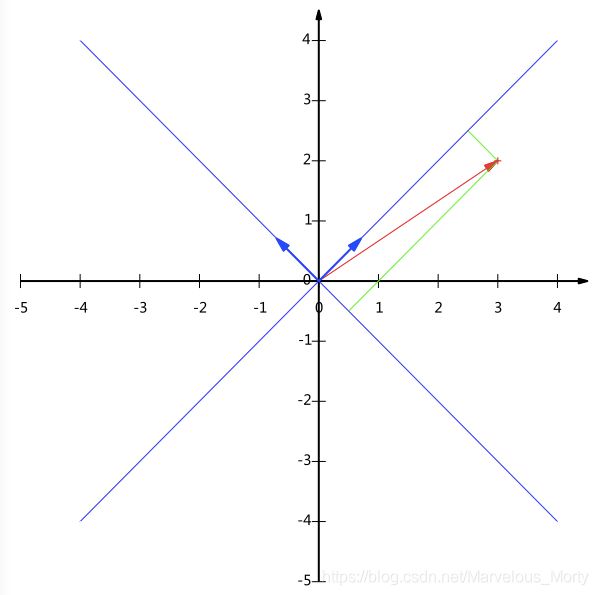
这里就引出了一个概念,坐标是一个相对的概念,只是我们平时见标准的0-90.的坐标轴看多了,其实所有的向量/坐标都是一个相对于坐标轴的概念值而已。
另外这里要注意的是,我们列举的例子中基是正交的(即内积为0,或直观说相互垂直),但可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。 不过因为正交基有较好的性质,所以一般使用的基都是正交的。
我们来继续看上图,(1,1)和(-1,1)也可以成为一组基。一般来说,我们希望基的模是1,因为从内积的意义可以看到,如果基的模是1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!
实际上,对应任何一个向量我们总可以找到其同方向上模为1的向量,只要让两个分量分别除以模就好了。例如,上面的基可以变为![]() ,各个基的模为1。
,各个基的模为1。
3.2.3 基变换的矩阵表 - 基变换是有损的
在上一小节我们讨论了一个非常重要的概念,即任意的一组线性无关的向量都可以表示为基,而不仅限于90°的 x-y 坐标轴。
同时我们现在熟悉的(x,y)坐标其实本质是在一组特定基上的表示方法,一旦我们的基发生概念,坐标值也会发生改变,这个改变的过程就叫基变换。
我们换一种更简便的方式来表示基变换,继续以上图的坐标系为例:
将(3,2)变换为新基上的坐标,就是用(3,2)与第新基的各分量分别做内积运算(将一个坐标系上的点"转换"到另一个坐标系本质就是在投影),得到的结果作为第新的坐标。实际上,我们可以用矩阵相乘的形式简洁的表示这个变换,这里![]() 是新基的向量,(3,2)是原基的向量。
是新基的向量,(3,2)是原基的向量。

其中矩阵的两行分别为两个基,乘以原向量,其结果刚好为新基的坐标。
稍微推广一下,如果我们有m个二维向量,只要将二维向量按列排成一个两行m列矩阵,然后用“基矩阵”乘以这个矩阵,就得到了所有这些向量在新基下的值。例如(1,1),(2,2),(3,3),想变换到刚才那组基上,则可以这样表示

于是一组向量的基变换被干净的表示为矩阵的相乘。
一般的,如果我们有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A, 然后将原始向量按列组成矩阵B, 那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果。
注:
- N维向量,必须有N维的基,否则无法投影。N 的作用可以理解为一个“接收器”,对原始向量的每一个维度都必须要有一个对应的维度去对应接收。
- R代表基的个数,注意,这里 R 的数量可以是任意多个,区别只是向多少个轴进行投影的区别而已,如果 R < N,则转换后维数减少了;如果 R > N,则转换后维数增加了。
- M是原始向量的数量,数量在基变换前后是保持不变的。
数学表示为
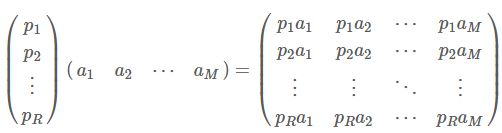
(R x N). (N x M)=(R x M)
其中特别要注意的是,这里R可以小于N,而R决定了变换后数据的维数。也就是说,我们可以将 N维数据变换到更低维度的空间中去,变换后的维度取决于基的数量。因此这种矩阵相乘的表示也可以表示"降维变换"
最后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。
3.2.4 协方差矩阵及优化目标 - 如何找到损失最低的变换基
上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,而且如果基的数量少于向量本身的维数,则可以达到降维的效果。
但是我们还没有回答一个最最关键的问题:**如何选择基才是最优的。**或者说,如果我们有一组N维向量,现在要将其降到K维(K小于N),那么我们应该如何选择K个基才能最大程度保留原有的信息。
假设我们的数据由五条记录组成,将它们表示成矩阵形式:

其中每一列为一条数据记录(列向量),而一行为一个字段。为了后续处理方便,我们首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为0。我们看上面的数据,第一个字段均值为2,第二个字段均值为3,所以变换后:

我们可以看下五条数据在平面直角坐标系内的样子
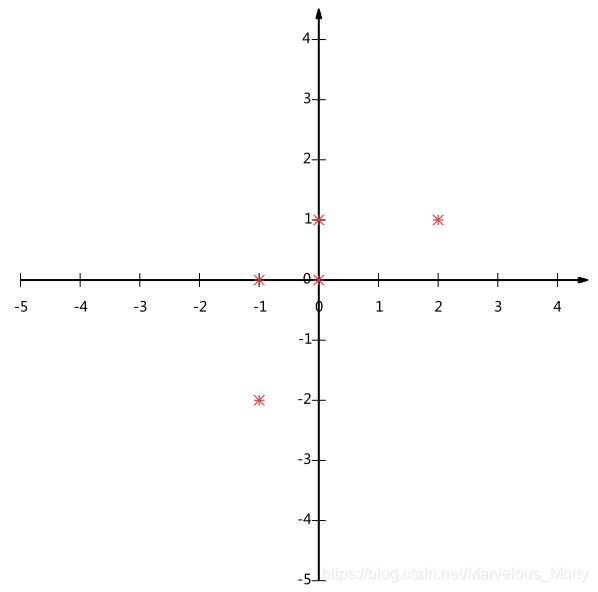
现在问题来了:如果我们必须使用一组新的基来表示这些数据,又希望尽量保留原始的信息(保留原始数据的概率分布),我们应该如何选择?
通过上一节对基变换的讨论我们知道,这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。数据越分散,可分性就越强,可分性越强,概率分布保存的就越完整。
以上图为例:
可以看出如果向x轴投影,那么最左边的两个点会重叠在一起,中间的两个点也会重叠在一起,于是本身四个各不相同的二维点投影后只剩下两个不同的值了,这是一种严重的信息丢失。
同理,如果向y轴投影最上面的两个点和分布在x轴上的两个点也会重叠。
所以看来x和y轴都不是最好的投影选择。我们直观目测,如果向通过第一象限和第三象限的斜线投影,则五个点在投影后还是可以区分的。
下面,我们用数学方法表述和讨论这个问题
投影后的新坐标点的方差 - 一种表征信息丢失程度的度量
上文说到,我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。此处,一个字段的方差可以看做是每个元素与字段均值的差的平方和的均值,即

在使用应用中,在运行PCA之前需要对样本进行“中心化”。即,我们首先计算,然后再进行PCA过程。
由于上面我们已经将每个字段的均值都化为0了,因此方差可以直接用每个元素的平方和除以元素个数表示

于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
协方差
对于二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,还有一个问题需要解决。
考虑三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。如果我们还是单纯只选择方差最大的方向,很明显,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因此,应该有其他约束条件。
从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。
数学上可以用两个字段的协方差表示其相关性,由于已经让每个字段均值为0,则

可以看到,在字段均值为0的情况下,两个字段的协方差简洁的表示为其内积除以元素数m
当协方差为0时,表示两个字段完全独立。为了让协方差为0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。至此,我们得到了降维问题的优化目标
将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0(各自独立);
而字段的方差则尽可能大(投影后的点尽可能离散)。在正交的约束下,取最大的K个方差
协方差矩阵 - 字段内方差及字段间协方差的统一数学表示
我们看到,最终要达到的目的与字段内方差及字段间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关
假设我们只有a和b两个字段,那么我们将它们按行组成矩阵X
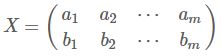
然后我们用X乘以X的转置,并乘上系数1/m

这个矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是a和b的协方差。两者被统一到了一个矩阵的,根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况
设我们有m个n维数据记录,将其按列排成n乘m的矩阵X,设![]() ,则C是一个对称矩阵,其对角线分别是各个字段的方差,而第i行j列和j行i列元素相同,表示i和j两个字段的协方差。
,则C是一个对称矩阵,其对角线分别是各个字段的方差,而第i行j列和j行i列元素相同,表示i和j两个字段的协方差。
协方差矩阵对角化
根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线(方差要尽可能大)外的其它元素化为0(协方差为0),并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的
设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:
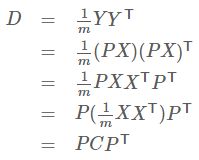
现在事情很明白了!我们要找的P不是别的,而是能让原始协方差矩阵对角化的P。换句话说:
优化目标变成了寻找一个矩阵P,满足 ![]() 是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基(因为要取尽可能大的方差),用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件
是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基(因为要取尽可能大的方差),用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件
由上文知道,协方差矩阵C是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质
1)实对称矩阵不同特征值对应的特征向量必然正交。
2)设特征向量λλ重数为r,则必然存在r个线性无关的特征向量对应于λλ,因此可以将这r个特征向量单位正交化。
由上面两条可知,一个n行n列的实对称矩阵一定可以找到n个单位正交特征向量,设这n个特征向量为e1,e2,⋯,en![]()
则对协方差矩阵C有如下结论
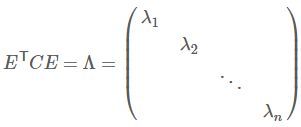
其中Λ。到这里,我们发现我们已经找到了需要的矩阵P:![]()
P是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是C的一个特征向量。如果设P按照Λ在PCA中,我们要找的压缩矩阵 W 和复原矩阵 U 使得原始信号和复原信号在平方距离上最小,即,我们需要求解如下问题:
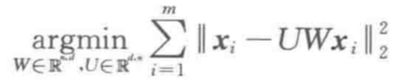 ,即尽量无损压缩。
,即尽量无损压缩。
令 x1,…,xm是![]() 中的任意向量,
中的任意向量,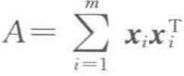 ,以及 u1,…,un是 A 中最大的 n 个特征值对应的特征向量。那么,上式PCA优化问题的解为:令 U 的列等于 u1,…,un,以及
,以及 u1,…,un是 A 中最大的 n 个特征值对应的特征向量。那么,上式PCA优化问题的解为:令 U 的列等于 u1,…,un,以及
- 降维后的信息损失尽可能小,尽可能保留原始样本的概率分布
- 降维后的基之间是完全正交的
总结一下PCA的算法步骤
-
设有m条n维数据
-
将原始数据按列组成n行m列矩阵X
-
将X的每一行(代表一个属性字段,即一个维度)进行零均值化,即减去这一行的均值
-
求出协方差矩阵
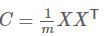
-
求出协方差矩阵的特征值(矩阵特征值)及对应的特征向量(矩阵特征向量)
-
将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
-
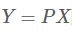 即为降维到k维后的数据。
即为降维到k维后的数据。
总的来说,PCA降维的目的是让降维后的向量方差最大(最离散),协方差最小(目标维的各个基之间的相关性最小)
一个例子

我们用PCA方法将这组二维数据其降到一维。
因为这个矩阵的每行已经是零均值,这里我们直接求协方差矩阵

然后求其特征值和特征向量。求解后特征值为![]()
其对应的特征向量分别是
其中对应的特征向量分别是一个通解,c1
因此我们的矩阵P是
可以验证协方差矩阵C的对角化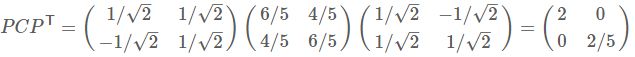
最后我们用P的第一行乘以数据矩阵,就得到了降维后的表示![]()
降维投影结果如下图

3.3 PCA的限制
- 它可以很好的解除线性相关,但是对于高阶相关性就没有办法了,对于存在高阶相关性的数据,可以考虑Kernel PCA,通过Kernel函数将非线性相关转为线性相关;
- PCA假设数据各主特征是分布在正交方向上,如果在非正交方向上存在几个方差较大的方向,PCA的效果就大打折扣了;
- PCA是一种无参数技术,无法实现个性优化。
也就是说面对同样的数据,如果不考虑清洗,谁来做结果都一样,没有主观参数的介入,所以PCA便于通用实现,但是本身无法个性化的优化;
3.4 基于原生python+numpy实现PCA算法
先对原始数据零均值化(在图像里表现为白化处理,忽略各个图像不同的亮度),然后求协方差矩阵,接着对协方差矩阵求特征向量和特征值,这些特征向量组成了新的特征空间
- 零均值化
假如原始数据集为矩阵dataMat,dataMat中每一行代表一个样本,每一列代表同一个特征。零均值化就是求每一列的平均值,然后该列上的所有数都减去这个均值。也就是说,这里零均值化是对每一个特征而言的
def zeroMean(dataMat):
meanVal=np.mean(dataMat,axis=0) #按列求均值,即求各个特征的均值
newData=dataMat-meanVal
return newData,meanVal
用numpy中的mean方法来求均值,axis=0表示按列求均值 - 求协方差矩阵
newData,meanVal=zeroMean(dataMat)
covMat=np.cov(newData,rowvar=0)
numpy中的cov函数用于求协方差矩阵,参数rowvar很重要!若rowvar=0,说明传入的数据一行代表一个样本,若非0,说明传入的数据一列代表一个样本。因为newData每一行代表一个样本,所以将rowvar设置为0 - 求特征值、特征矩阵
调用numpy中的线性代数模块linalg中的eig函数,可以直接由协方差矩阵求得特征值和特征向量
eigVals,eigVects=np.linalg.eig(np.mat(covMat))
eigVals存放特征值,行向量。
eigVects存放特征向量,每一列带别一个特征向量。
特征值和特征向量是一一对应的 - 保留主要的成分[即保留值比较大的前n个特征
第三步得到了特征值向量eigVals,假设里面有m个特征值,我们可以对其排序,排在前面的n个特征值所对应的特征向量就是我们要保留的,它们组成了新的特征空间的一组基n_eigVect。将零均值化后的数据乘以n_eigVect就可以得到降维后的数据
eigValIndice=np.argsort(eigVals) #对特征值从小到大排序
n_eigValIndice=eigValIndice[-1:-(n+1):-1] #最大的n个特征值的下标
n_eigVect=eigVects[:,n_eigValIndice] #最大的n个特征值对应的特征向量
lowDDataMat=newDatan_eigVect #低维特征空间的数据
reconMat=(lowDDataMatn_eigVect.T)+meanVal #重构数据
return lowDDataMat,reconMat - 完整code
# 零均值化
def zeroMean(dataMat):
meanVal = np.mean(dataMat, axis=0) # 按列求均值,即求各个特征的均值
newData = dataMat - meanVal
return newData, meanVal
def pca(dataMat, n):
newData, meanVal = zeroMean(dataMat)
covMat = np.cov(newData, rowvar=0) # 求协方差矩阵,return ndarray;若rowvar非0,一列代表一个样本,为0,一行代表一个样本
eigVals, eigVects = np.linalg.eig(np.mat(covMat)) # 求特征值和特征向量,特征向量是按列放的,即一列代表一个特征向量
eigValIndice = np.argsort(eigVals) # 对特征值从小到大排序
n_eigValIndice = eigValIndice[-1:-(n + 1):-1] # 最大的n个特征值的下标
n_eigVect = eigVects[:, n_eigValIndice] # 最大的n个特征值对应的特征向量
lowDDataMat = newData * n_eigVect # 低维特征空间的数据
reconMat = (lowDDataMat * n_eigVect.T) + meanVal # 重构数据
return lowDDataMat, reconMat
Relevant Link:
http://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html
http://blog.codinglabs.org/articles/pca-tutorial.html
对图像数据应用PCA算法
为使PCA算法能有效工作,通常我们希望所有的特征都有相似的取值范围(并且均值接近于0)。我们有必要单独对每个特征做预处理,即通过估算每个特征的均值和方差,而后将其取值范围规整化为零均值和单位方差。
但是,对于大部分图像类型,我们却不需要进行这样的预处理。在实践中我们发现,大多数特征学习算法对训练图片的确切类型并不敏感,所以大多数用普通照相机拍摄的图片,只要不是特别的模糊或带有非常奇怪的人工痕迹,都可以使用。在自然图像上进行训练时,对每一个像素单独估计均值和方差意义不大,因为(理论上)图像任一部分的统计性质都应该和其它部分相同,图像的这种特性被称作平稳性(stationarity)。
具体而言,为使PCA算法正常工作,我们通常需要满足以下要求
- 特征的均值大致为0
- 不同特征的方差值彼此相似
对于自然图片,即使不进行方差归一化操作,条件(2)也自然满足,故而我们不再进行任何方差归一化操作(对音频数据,如声谱,或文本数据,如词袋向量,我们通常也不进行方差归一化)
实际上,PCA算法对输入数据具有缩放不变性,无论输入数据的值被如何放大(或缩小),返回的特征向量都不改变。更正式的说:如果将每个特征向量x 都乘以某个正数(即所有特征量被放大或缩小相同的倍数),PCA的输出特征向量都将不会发生变化
既然我们不做方差归一化,唯一还需进行的规整化操作就是均值规整化,其目的是保证所有特征的均值都在0附近。根据应用场景,在大多数情况下,我们并不关注所输入图像的整体明亮程度。比如在对象识别任务中,图像的整体明亮程度并不会影响图像中存在的是什么物体。
更为正式地说,我们对图像块的平均亮度值不感兴趣,所以可以减去这个值来进行均值规整化。
需要注意的是,如果你处理的图像并非自然图像(比如,手写文字,或者白背景正中摆放单独物体),其他规整化操作就值得考虑了,而哪种做法最合适也取决于具体应用场合。但对自然图像而言,对每幅图像进行上述的零均值规整化,是默认而合理的处理 - 利用PCA进行人脸识别
接下来我们尝试对一个图像进行PCA处理,这里我们对一张图像进行PCA降维处理,进而基于降维后的低维度像素图进行人脸相似度检测。
大致思路是,收集一个基准样本集(标准人像),然后通过PCA降维提高运算效率,之后的测试过程就是拿待测试样本图像和基准样本集中的所有图片依次计算"欧式距离",最后的判定结果以离基准样本集欧式距离最近的那张图像为"人脸"

# -*- coding: utf-8 -*-
import numpy as np
import scipy.linalg as linA # 为了激活线性代数库mkl
from PIL import Image
from resizeimage import resizeimage
import os,glob
imageWidth = 230
imageHigth = 300
imageSize = imageWidth * imageHigth
def sim_distance(train,test):
'''
计算欧氏距离相似度
:param train: 二维训练集
:param test: 一维测试集
:return: 该测试集到每一个训练集的欧氏距离
'''
return [np.linalg.norm(i - test) for i in train]
def resizeImage(filepath):
img = Image.open(filepath)
img = img.resize((imageWidth, imageHigth), Image.BILINEAR)
img.save(filepath)
def resizeImages():
picture_path = os.getcwd() + '/images/'
for name in glob.glob(picture_path + '*.jpeg'):
print name
resizeImage(name)
def calcVector(arr1, arr2):
distance1, distance2 = 0, 0
for i in arr1:
distance1 += i * i
distance1 = distance1 / len(arr1)
for i in arr2:
distance2 += i * i
distance2 = distance2 / len(arr2)
return distance1 < distance2
def main():
picture_path = os.getcwd() + '/images/'
print "picture_path: ", picture_path
array_list = []
for name in glob.glob(picture_path + '*.jpeg'):
print name
# 读取每张图片并生成灰度(0-255)的一维序列 1*120000
img = Image.open(name)
# img_binary = img.convert('1') 二值化
img_grey = img.convert('L') # 灰度化
array_list.append(np.array(img_grey).reshape((1, imageSize))) # 拉长为1维
mat = np.vstack((array_list)) # 将上述多个一维序列(每个序列代表一张图片)合并成矩阵 3*69000
P = np.dot(mat, mat.transpose()) # 计算P
v, d = np.linalg.eig(P) # 计算P的特征值和特征向量
print 'P Eigenvalues'
print v
print "Feature vector"
print d
d = np.dot(mat.transpose(), d) # 计算Sigma的特征向量 69000 * 3
train = np.dot(d.transpose(), mat.transpose()) # 计算训练集的主成分值 3*3
print '训练集pca降维后的向量数组'
print train
# 开始测试
# 用于测试的图片也需要resize为和训练基准样本集相同的size
resizeImage('images/test_1.jpg')
test_pic = np.array(Image.open('images/test_1.jpg').convert('L')).reshape((1, imageSize))
# 计算测试集到每一个训练集的欧氏距离
result1 = sim_distance(train.transpose(), np.dot(test_pic, d))
print 'test_1.jpg 降维后的向量'
print result1
resizeImage('images/test_2.jpg')
test_pic = np.array(Image.open('images/test_2.jpg').convert('L')).reshape((1, imageSize))
result2 = sim_distance(train.transpose(), np.dot(test_pic, d))
print 'test_2.jpg 降维后的向量'
print result2
# 欧式距离最小的即为最接近训练样本集的测试样本
if calcVector(result1, result2):
print 'test_1.jpg is a human'
else:
print 'test_2.jpg is a human'
if __name__ == '__main__':
resizeImages()
main()
训练集的计算结果为
/System/Library/Frameworks/Python.framework/Versions/2.7/bin/python /Users/zhenghan/PycharmProjects/littlehann/just4fun.py
/Users/zhenghan/PycharmProjects/littlehann/images/train_2.jpeg
/Users/zhenghan/PycharmProjects/littlehann/images/train_3.jpeg
/Users/zhenghan/PycharmProjects/littlehann/images/train_1.jpeg
picture_path: /Users/zhenghan/PycharmProjects/littlehann/images/
/Users/zhenghan/PycharmProjects/littlehann/images/train_2.jpeg
/Users/zhenghan/PycharmProjects/littlehann/images/train_3.jpeg
/Users/zhenghan/PycharmProjects/littlehann/images/train_1.jpeg
P Eigenvalues
[ 444.76007266 -199.2827456 -8.47732705]
Feature vector
[[-0.557454 -0.7252759 0.40400484]
[-0.69022539 0.1344664 -0.71099065]
[-0.46133931 0.67519898 0.57556266]]
pca
[[ -2.94130809e+09 -2.81400683e+09 -2.27967171e+09]
[ -4.53920521e+08 2.41231868e+07 4.49796574e+07]
[ 5.06334430e+08 1.43429000e+08 2.56660545e+08]]
test_1.jpg
[859150941.34167683, 507130780.35877681, 98296821.771007225]
test_2.jpg
[921097812.32432926, 784122768.95719075, 323861431.46721846]
test_1.jpg is a human
Process finished with exit code 0
利用如下图片进行识别测试,首先右乘得到各自在三个主轴上的值(对测试样本也同样进行PCA化),然后计算出该图片到训练样本中的三张图片的欧式距离

test_1.jpg
[859150941.34167683, 507130780.35877681, 98296821.771007225]
test_2.jpg
[921097812.32432926, 784122768.95719075, 323861431.46721846]
test_1.jpg is a human
再用别的测试集类来测试

上述的代码中我们自己实现了PCA的代码,实际上这个逻辑可以用sklearn来完成
sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False)
1. n_components: PCA算法中所要保留的主成分个数n,也即保留下来的特征个数n
1) 缺省时默认为None,所有成分被保留
2) 赋值为int,比如n_components=1,将把原始数据降到一个维度
3) 赋值为string,比如n_components='mle',将自动选取特征个数n,使得满足所要求的方差百分比。
2. copy: 表示是否在运行算法时,将原始训练数据复制一份。若为True,则运行PCA算法后,原始训练数据的值不会有任何改变,因为是在原始数据的副本上进行运算;若为False,则运行PCA算法后,原始训练数据的值会改,因为是在原始数据上进行降维计算
1) 缺省时默认为True
3. whiten: 白化,使得每个特征具有相同的方差(即去均值化)
1) 缺省时默认为False
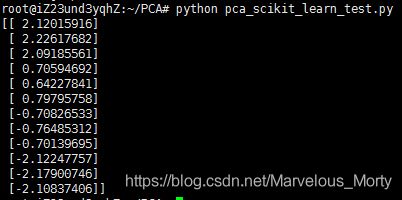
# -*- coding: utf-8 -*-
from sklearn.decomposition import PCA
data = [[ 1. , 1. ],
[ 0.9 , 0.95],
[ 1.01, 1.03],
[ 2. , 2. ],
[ 2.03, 2.06],
[ 1.98, 1.89],
[ 3. , 3. ],
[ 3.03, 3.05],
[ 2.89, 3.1 ],
[ 4. , 4. ],
[ 4.06, 4.02],
[ 3.97, 4.01]]
if __name__ == '__main__':
pca = PCA(n_components=1)
newData = pca.fit_transform(data)
print newData