Kafka+Eclipse开发环境搭建
使用的电脑系统和安装包
PC:Ubuntu16.04 64bit
JDK版本:openjdk-8-jdk
Kafka:kafka_2.12-2.2.0.tgz
Eclipse:eclipse-jee-oxygen-R-linux-gtk-x86_64.tar.gz
Scala:scala-2.12.8.tgz
Eclipse Scala 插件:scala-SDK-4.7.0-vfinal-2.12-linux.gtk.x86_64.tar.gz
zookeeper:zookeeper-3.4.14.tar.gz
1.安装JDK
sudo add-apt-repository ppa:openjdk-r/ppasudo apt-get updatesudo apt-get install openjdk-8-jdk设置环境,就可以了.
2.安装Scala,zookeeper和Kafka更简单,解压缩文件,设置环境,不再罗嗦。
3.设置Zookeeper
在Zookeeper安装目录下,创建两个文件夹,data和logs
然后,在data目录下创建一个myid,在myid中填写这个broker的id,比如1
需要保证Zookeeper集群的各个broker.id唯一就可以了,一般都是安传顺序来,1,2,3...
复制conf/zoo_sample.cfg为zoo.cfg,增加如下修改
server.1=192.168.1.100:2888:3888 #1就是myid中的数值
地址为本机IP
启动Zookeeper:
zkServer.sh start
然后,打开一个窗口,输入jps
1555 QuorumPeerMain
说明启动成功
4. 安装Kafka
解压缩Kafka后,在Kafka安装目录下创建data和logs两个文件夹,然后配置Kafka,修改config/server.properties
增加以下修改:
delete.topic.enable=true
broker.id=1 #zookeeper的myid
log.dirs=/home/xxxx/kafka_2.12-2.2.0/logs
启动Kafka
cd /home/xxxx/kafka_2.12-2.2.0/bin
./zookeeper-server-start.sh -daemon ../config/server.properties
打开窗口,输入jps
1938 Kafka
注意:
a.Kafka使用的Scala版本必须与当前系统安装的Scala一致,才能正常启动
b.server.properties中,log,dirs必须设置正确
5.安装Eclipse和Scala插件
解压缩Eclipse和Scala插件,在eclipse的dropins文件夹下创建Scala,然后把Scala插件解压缩后的features和plugins
两个文件夹,拷贝到Scala文件夹下,重新启动eclipse即可。
6.在Eclipse中创建Kafka producer和consumer
Producer代码如下:
package test.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class Producertest {
// Topic
private static final String topic = "kafkaTopic";
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092");
props.put("acks", "0"); props.put("group.id", "1111"); props.put("retries", "0");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(props);
int i = 1;
// 发送业务消息 // 读取文件 读取内存数据库 读socket端口
while (true) {
Thread.sleep(1000);
producer.send(new ProducerRecord
System.out.println("key:" + i + " " + "value:" + i);
i++;
if(i>200) {
producer.close();
break;
}
}
}
}
消费者代码如下
package com.test1;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerTest {
private static final Logger logger = LoggerFactory.getLogger(ConsumerTest.class);
private static final String topic = "kafkaTopic";
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092");
props.put("group.id", "1111");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "earliest");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer
consumer.subscribe(Arrays.asList(topic));
int i=0;
while (true) {
ConsumerRecords
for (ConsumerRecord
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
i++;
}
if(i>200) {
System.out.println("receive enough message");
break;
}
}
consumer.close();
consumer = null;
}
}
这两份拷贝自网上一位工程师的代码,特此致谢!
引用的包,参考下图:
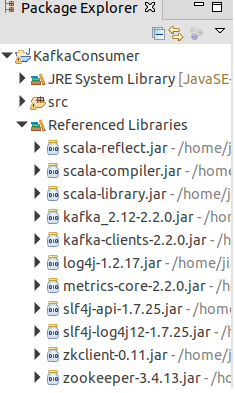
这些包有两个来源
第一个,kafka安装包下的libs
第二个,scala安装包下的lib文件夹
从这两个文件夹引入外部包就可以了。
本文使用的工具,请到如下地址获取
链接:https://pan.baidu.com/s/1MedytVpaXjOufJclC7NTqw
提取码:3nol