Pandas入门
文章目录
- 1 Pandas介绍
- 2 为什么使用Pandas
- 3 DataFrame
- 3.1 属性
- 3.2 方法
- 4 DataFrame索引的设置
- 4.1 修改行列索引值
- 4.2 设置新索引
- 5 Series
- 6 使用索引和切片
- 6.1 对Series
- 6.2 切片
- 6.3 按照字段和数字索引
- 7 赋值操作
- 8 排序
- 8.1 对内容排序
- 8.2 对索引改变为从小到大
- 8.3 对Series排序
- 9 DataFrame运算与统计
- 9.1 使用describe完成综合统计
- 9.2 使用idxmin、idxmax完成最大值最小值的索引
- 9.3 使用cumsum等实现累计分析
- 9.4 算术运算
- 9.5 逻辑运算函数 query() isin()
- 9.6 布尔索引
- 9.7 min max
1 Pandas介绍
- 专门用于数据挖掘的开源python库
- 以Numpy为基础,借力Numpy模块在计算方面性能优势
- 基于matplotlib,能够简便的画图
- 独特的数据结构
Pandas 是一种数据处理工具,它是以下面三组词汇组成
panel + data + analysis
panel:面板数据是计量经济学中常用,一般表示三维数据
2 为什么使用Pandas
- 便捷的数据处理能力
- 读取文件方便
- 封装了Matplotlib、Numpy的画图和计算
3 DataFrame

从图中可以看到DataFrame由三部分组成
- column label即列标签
- index label即行标签
- data即数据
那么标记轴axis表示什么呢,axis有两种取值,分别是1和0,其中1表示横轴,方向从左到右;0表示纵轴,方向从上到下。
import numpy as np
#创建一个符合正态分布的10个股票5天的涨跌幅数据
stock_change =np.random.normal(0,1,(10,5))
stock_change
array([[ 0.55780125, 0.47366431, 0.58266456, -0.29946146, -0.03390217],
[-0.24385523, 0.08817049, 1.38707642, -0.57688673, -0.34760394],
[ 0.95549368, 0.9414475 , -1.25056314, 0.18178455, -0.29557978],
[ 1.61507705, 1.99202826, 2.80758189, 0.03192688, -0.57838353],
[ 1.4956878 , -1.23262134, 2.50024192, -0.58850329, 0.7102027 ],
[-0.662319 , 1.76285879, 1.51286286, -0.53192944, -0.47949495],
[ 0.73735599, 0.48964047, -1.32854508, -0.07826431, 0.36766669],
[ 0.79199457, -1.74662017, -0.334844 , -1.47935611, -0.12609656],
[-1.77942406, -1.67284383, -0.90279781, 0.06015451, 0.66952752],
[-1.93908274, -1.93232172, 0.8559445 , 1.13113002, 1.33307564]])
import pandas as pd
pd.DataFrame(stock_change)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0.557801 | 0.473664 | 0.582665 | -0.299461 | -0.033902 |
| 1 | -0.243855 | 0.088170 | 1.387076 | -0.576887 | -0.347604 |
| 2 | 0.955494 | 0.941448 | -1.250563 | 0.181785 | -0.295580 |
| 3 | 1.615077 | 1.992028 | 2.807582 | 0.031927 | -0.578384 |
| 4 | 1.495688 | -1.232621 | 2.500242 | -0.588503 | 0.710203 |
| 5 | -0.662319 | 1.762859 | 1.512863 | -0.531929 | -0.479495 |
| 6 | 0.737356 | 0.489640 | -1.328545 | -0.078264 | 0.367667 |
| 7 | 0.791995 | -1.746620 | -0.334844 | -1.479356 | -0.126097 |
| 8 | -1.779424 | -1.672844 | -0.902798 | 0.060155 | 0.669528 |
| 9 | -1.939083 | -1.932322 | 0.855944 | 1.131130 | 1.333076 |
给股票数据增加行列索引
pd.DataFrame(stock_change,行索引,列索引)
# 添加行索引 列表解析
stock = ["股票{}".format(i) for i in range(10)]
pd.DataFrame(stock_change,stock)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 股票0 | 0.557801 | 0.473664 | 0.582665 | -0.299461 | -0.033902 |
| 股票1 | -0.243855 | 0.088170 | 1.387076 | -0.576887 | -0.347604 |
| 股票2 | 0.955494 | 0.941448 | -1.250563 | 0.181785 | -0.295580 |
| 股票3 | 1.615077 | 1.992028 | 2.807582 | 0.031927 | -0.578384 |
| 股票4 | 1.495688 | -1.232621 | 2.500242 | -0.588503 | 0.710203 |
| 股票5 | -0.662319 | 1.762859 | 1.512863 | -0.531929 | -0.479495 |
| 股票6 | 0.737356 | 0.489640 | -1.328545 | -0.078264 | 0.367667 |
| 股票7 | 0.791995 | -1.746620 | -0.334844 | -1.479356 | -0.126097 |
| 股票8 | -1.779424 | -1.672844 | -0.902798 | 0.060155 | 0.669528 |
| 股票9 | -1.939083 | -1.932322 | 0.855944 | 1.131130 | 1.333076 |
#添加列索引(先行后列)
date = pd.date_range(start ="20180101",periods=5,freq="B")
data =pd.DataFrame(stock_change,stock,date)
结构:既有行索引,又有列索引的二维数组
| 2018-01-01 00:00:00 | 2018-01-02 00:00:00 | 2018-01-03 00:00:00 | 2018-01-04 00:00:00 | 2018-01-05 00:00:00 | |
|---|---|---|---|---|---|
| 股票0 | 0.557801 | 0.473664 | 0.582665 | -0.299461 | -0.033902 |
| 股票1 | -0.243855 | 0.088170 | 1.387076 | -0.576887 | -0.347604 |
| 股票2 | 0.955494 | 0.941448 | -1.250563 | 0.181785 | -0.295580 |
| 股票3 | 1.615077 | 1.992028 | 2.807582 | 0.031927 | -0.578384 |
| 股票4 | 1.495688 | -1.232621 | 2.500242 | -0.588503 | 0.710203 |
| 股票5 | -0.662319 | 1.762859 | 1.512863 | -0.531929 | -0.479495 |
| 股票6 | 0.737356 | 0.489640 | -1.328545 | -0.078264 | 0.367667 |
| 股票7 | 0.791995 | -1.746620 | -0.334844 | -1.479356 | -0.126097 |
| 股票8 | -1.779424 | -1.672844 | -0.902798 | 0.060155 | 0.669528 |
| 股票9 | -1.939083 | -1.932322 | 0.855944 | 1.131130 | 1.333076 |
3.1 属性
- shape 形状
- index 行索引
- columns 列索引
- values NDARRAY数据
- T 转置
data.shape
(10, 5)
data.index
Index(['股票0', '股票1', '股票2', '股票3', '股票4', '股票5', '股票6', '股票7', '股票8', '股票9'], dtype='object')
data.values
array([[ 0.55780125, 0.47366431, 0.58266456, -0.29946146, -0.03390217],
[-0.24385523, 0.08817049, 1.38707642, -0.57688673, -0.34760394],
[ 0.95549368, 0.9414475 , -1.25056314, 0.18178455, -0.29557978],
[ 1.61507705, 1.99202826, 2.80758189, 0.03192688, -0.57838353],
[ 1.4956878 , -1.23262134, 2.50024192, -0.58850329, 0.7102027 ],
[-0.662319 , 1.76285879, 1.51286286, -0.53192944, -0.47949495],
[ 0.73735599, 0.48964047, -1.32854508, -0.07826431, 0.36766669],
[ 0.79199457, -1.74662017, -0.334844 , -1.47935611, -0.12609656],
[-1.77942406, -1.67284383, -0.90279781, 0.06015451, 0.66952752],
[-1.93908274, -1.93232172, 0.8559445 , 1.13113002, 1.33307564]])
data.T
| 股票0 | 股票1 | 股票2 | 股票3 | 股票4 | 股票5 | 股票6 | 股票7 | 股票8 | 股票9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2018-01-01 | 0.557801 | -0.243855 | 0.955494 | 1.615077 | 1.495688 | -0.662319 | 0.737356 | 0.791995 | -1.779424 | -1.939083 |
| 2018-01-02 | 0.473664 | 0.088170 | 0.941448 | 1.992028 | -1.232621 | 1.762859 | 0.489640 | -1.746620 | -1.672844 | -1.932322 |
| 2018-01-03 | 0.582665 | 1.387076 | -1.250563 | 2.807582 | 2.500242 | 1.512863 | -1.328545 | -0.334844 | -0.902798 | 0.855944 |
| 2018-01-04 | -0.299461 | -0.576887 | 0.181785 | 0.031927 | -0.588503 | -0.531929 | -0.078264 | -1.479356 | 0.060155 | 1.131130 |
| 2018-01-05 | -0.033902 | -0.347604 | -0.295580 | -0.578384 | 0.710203 | -0.479495 | 0.367667 | -0.126097 | 0.669528 | 1.333076 |
3.2 方法
- head() 数据量过大时,取前五行数据查看
- tail()数据量过大时,取最后五行数据
data.head()
| 2018-01-01 00:00:00 | 2018-01-02 00:00:00 | 2018-01-03 00:00:00 | 2018-01-04 00:00:00 | 2018-01-05 00:00:00 | |
|---|---|---|---|---|---|
| 股票0 | 0.557801 | 0.473664 | 0.582665 | -0.299461 | -0.033902 |
| 股票1 | -0.243855 | 0.088170 | 1.387076 | -0.576887 | -0.347604 |
| 股票2 | 0.955494 | 0.941448 | -1.250563 | 0.181785 | -0.295580 |
| 股票3 | 1.615077 | 1.992028 | 2.807582 | 0.031927 | -0.578384 |
| 股票4 | 1.495688 | -1.232621 | 2.500242 | -0.588503 | 0.710203 |
data.tail()
| 2018-01-01 00:00:00 | 2018-01-02 00:00:00 | 2018-01-03 00:00:00 | 2018-01-04 00:00:00 | 2018-01-05 00:00:00 | |
|---|---|---|---|---|---|
| 股票5 | -0.662319 | 1.762859 | 1.512863 | -0.531929 | -0.479495 |
| 股票6 | 0.737356 | 0.489640 | -1.328545 | -0.078264 | 0.367667 |
| 股票7 | 0.791995 | -1.746620 | -0.334844 | -1.479356 | -0.126097 |
| 股票8 | -1.779424 | -1.672844 | -0.902798 | 0.060155 | 0.669528 |
| 股票9 | -1.939083 | -1.932322 | 0.855944 | 1.131130 | 1.333076 |
4 DataFrame索引的设置
4.1 修改行列索引值
data.index
Index(['股票0', '股票1', '股票2', '股票3', '股票4', '股票5', '股票6', '股票7', '股票8', '股票9'], dtype='object')
data.index[2] = "22"
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
----> 1 data.index[2] = "22"
D:\ANACONDA\lib\site-packages\pandas\core\indexes\base.py in __setitem__(self, key, value)
3936
3937 def __setitem__(self, key, value):
-> 3938 raise TypeError("Index does not support mutable operations")
3939
3940 def __getitem__(self, key):
TypeError: Index does not support mutable operations
由结果可以看出,报错了,这是因为不能直接使用数字索引修改个别索引字段,在pandas中必须全部重新设定索引
# 索引只能全部重新设定
new_index = ["股票_{}".format(n)for n in range(10,20)]
new_index
data.index = new_index
data
| 2018-01-01 00:00:00 | 2018-01-02 00:00:00 | 2018-01-03 00:00:00 | 2018-01-04 00:00:00 | 2018-01-05 00:00:00 | |
|---|---|---|---|---|---|
| 股票_10 | 0.557801 | 0.473664 | 0.582665 | -0.299461 | -0.033902 |
| 股票_11 | -0.243855 | 0.088170 | 1.387076 | -0.576887 | -0.347604 |
| 股票_12 | 0.955494 | 0.941448 | -1.250563 | 0.181785 | -0.295580 |
| 股票_13 | 1.615077 | 1.992028 | 2.807582 | 0.031927 | -0.578384 |
| 股票_14 | 1.495688 | -1.232621 | 2.500242 | -0.588503 | 0.710203 |
| 股票_15 | -0.662319 | 1.762859 | 1.512863 | -0.531929 | -0.479495 |
| 股票_16 | 0.737356 | 0.489640 | -1.328545 | -0.078264 | 0.367667 |
| 股票_17 | 0.791995 | -1.746620 | -0.334844 | -1.479356 | -0.126097 |
| 股票_18 | -1.779424 | -1.672844 | -0.902798 | 0.060155 | 0.669528 |
| 股票_19 | -1.939083 | -1.932322 | 0.855944 | 1.131130 | 1.333076 |
4.2 设置新索引
#设新索引
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
| month | year | sale | |
|---|---|---|---|
| 0 | 1 | 2012 | 55 |
| 1 | 4 | 2014 | 40 |
| 2 | 7 | 2013 | 84 |
| 3 | 10 | 2014 | 31 |
# 将列索引设为行索引,并且抛弃原来的列
df.set_index("month",drop=True)
| year | sale | |
|---|---|---|
| month | ||
| 1 | 2012 | 55 |
| 4 | 2014 | 40 |
| 7 | 2013 | 84 |
| 10 | 2014 | 31 |
5 Series
Series是一维对象,包含数组数据(任何numpy类型的数据)和与数组关联的索引,与list结构差不多,但是我们可以自定义索引
s1 = pd.Series([100,24,"asd",np.nan])
s1
0 100
1 24
2 asd
3 NaN
dtype: object
#添加索引需要index传递一个包含index的数组name表示这个索引的统称
s2 = pd.Series([20,30,50],index = ['2015','2016','23321'],name = 'product')
s2
2015 20
2016 30
23321 50
Name: product, dtype: int64
我们也可以将DataFrame理解为Series的容器,或者说DataFrame相当于用胶水把一堆series给粘了起来
-
pd.date_range函数:
这个函数用于生成一个固定频率的时间索引,在调用构造方法时,必须指定start、end、periods中的任两个参数值,否则会报错
下面用pd.date_range函数生成以周为频率的时间索引
time = pd.date_range('20190606',periods=6,freq='W')
time
DatetimeIndex(['2019-06-09', '2019-06-16', '2019-06-23', '2019-06-30',
'2019-07-07', '2019-07-14'],
dtype='datetime64[ns]', freq='W-SUN')
给freq参数传递值 W 表示频率为周,freq也可以取M,H,S,分别表示频率为月,小时,秒
6 使用索引和切片
6.1 对Series
对Series的处理比较简单
s2 = pd.Series([30,35,40],["2015",'2016','2017'],name = "product")
s2
2015 30
2016 35
2017 40
Name: product, dtype: int64
s2[0:2]
2015 30
2016 35
Name: product, dtype: int64
s2['2015':'2017']
#用字段索引能取到最后一位
2015 30
2016 35
2017 40
Name: product, dtype: int64
也可以实用布尔索引
s2[s2>10]
2015 30
2016 35
2017 40
Name: product, dtype: int64
6.2 切片
#只能对行标签切片
data['股票_10':"股票_16"]
| 2018-01-01 00:00:00 | 2018-01-02 00:00:00 | 2018-01-03 00:00:00 | 2018-01-04 00:00:00 | 2018-01-05 00:00:00 | |
|---|---|---|---|---|---|
| 股票_10 | 0.557801 | 0.473664 | 0.582665 | -0.299461 | -0.033902 |
| 股票_11 | -0.243855 | 0.088170 | 1.387076 | -0.576887 | -0.347604 |
| 股票_12 | 0.955494 | 0.941448 | -1.250563 | 0.181785 | -0.295580 |
| 股票_13 | 1.615077 | 1.992028 | 2.807582 | 0.031927 | -0.578384 |
| 股票_14 | 1.495688 | -1.232621 | 2.500242 | -0.588503 | 0.710203 |
| 股票_15 | -0.662319 | 1.762859 | 1.512863 | -0.531929 | -0.479495 |
| 股票_16 | 0.737356 | 0.489640 | -1.328545 | -0.078264 | 0.367667 |
#对位置切片也是对行切片等价
data[0:3]
| 2018-01-01 00:00:00 | 2018-01-02 00:00:00 | 2018-01-03 00:00:00 | 2018-01-04 00:00:00 | 2018-01-05 00:00:00 | |
|---|---|---|---|---|---|
| 股票_10 | 0.557801 | 0.473664 | 0.582665 | -0.299461 | -0.033902 |
| 股票_11 | -0.243855 | 0.088170 | 1.387076 | -0.576887 | -0.347604 |
| 股票_12 | 0.955494 | 0.941448 | -1.250563 | 0.181785 | -0.295580 |
# len返回多少行
data[0:len(data)-1]
| 2018-01-01 00:00:00 | 2018-01-02 00:00:00 | 2018-01-03 00:00:00 | 2018-01-04 00:00:00 | 2018-01-05 00:00:00 | |
|---|---|---|---|---|---|
| 股票_10 | 0.557801 | 0.473664 | 0.582665 | -0.299461 | -0.033902 |
| 股票_11 | -0.243855 | 0.088170 | 1.387076 | -0.576887 | -0.347604 |
| 股票_12 | 0.955494 | 0.941448 | -1.250563 | 0.181785 | -0.295580 |
| 股票_13 | 1.615077 | 1.992028 | 2.807582 | 0.031927 | -0.578384 |
| 股票_14 | 1.495688 | -1.232621 | 2.500242 | -0.588503 | 0.710203 |
| 股票_15 | -0.662319 | 1.762859 | 1.512863 | -0.531929 | -0.479495 |
| 股票_16 | 0.737356 | 0.489640 | -1.328545 | -0.078264 | 0.367667 |
| 股票_17 | 0.791995 | -1.746620 | -0.334844 | -1.479356 | -0.126097 |
| 股票_18 | -1.779424 | -1.672844 | -0.902798 | 0.060155 | 0.669528 |
6.3 按照字段和数字索引
上面的方法是有很大的局限,使用起来并不方便,那么pandas库有没有更加简便的方法对DataFrame和Series进行选择和索引呢?
下面介绍两种方法:
-
.loc 字段索引
-
.iloc 数字索引
-
ix 数字 字段混合索引ix方法,不过此方法已经过期,在未来会被移除,如果使用的话会出现warning
还是实用前面的df进行操作
| month | year | sale | |
|---|---|---|---|
| 0 | 1 | 2012 | 55 |
| 1 | 4 | 2014 | 40 |
| 2 | 7 | 2013 | 84 |
| 3 | 10 | 2014 | 31 |
df.loc[0,'year']
2012
df.loc[1,'sale']
40
df.loc[0:2]
| month | year | sale | |
|---|---|---|---|
| 0 | 1 | 2012 | 55 |
| 1 | 4 | 2014 | 40 |
| 2 | 7 | 2013 | 84 |
#列索引
df.loc[:,'month':'year']
| month | year | |
|---|---|---|
| 0 | 1 | 2012 |
| 1 | 4 | 2014 |
| 2 | 7 | 2013 |
| 3 | 10 | 2014 |
stock_data = pd.read_csv("./stock_day.csv")
stock_data
总结:
直接索引必须先列后行进行索引
new_data['open']['2018-02-26']
用loc索引既可先行后列,但必须按照名字索引
new_data.loc['2018-02-26','open']
一定要数字索引 使用iloc
new_data.iloc[1,0]
7 赋值操作
将open列数据全部赋值改变
new_data.open =100
new_data.iloc[1,0]=233
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 100 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 2.39 |
| 2018-02-26 | 233 | 23.78 | 23.53 | 22.80 | 60985.11 | 0.69 | 3.02 | 1.53 |
| 2018-02-23 | 100 | 23.37 | 22.82 | 22.71 | 52914.01 | 0.54 | 2.42 | 1.32 |
8 排序
排序有对内容排序和对索引排序
8.1 对内容排序
使用df.sort_values(key=,ascending=)对内容进行排序
-
单个键或者多个键进行排序,默认升序
-
ascending=False:降序
-
ascending=True:升序
new_data.sort_values("high",ascending=False)
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2015-06-10 | 100 | 36.35 | 33.85 | 32.23 | 269033.12 | 0.51 | 1.53 | 9.21 |
| 2015-06-12 | 100 | 35.98 | 35.21 | 34.01 | 159825.88 | 0.82 | 2.38 | 5.47 |
| 2017-10-31 | 100 | 35.22 | 34.44 | 32.20 | 361660.88 | 2.38 | 7.42 | 9.05 |
| 2015-06-15 | 100 | 34.99 | 31.69 | 31.69 | 199369.53 | -3.52 | -10.00 | 6.82 |
| 2015-06-11 | 100 | 34.98 | 34.39 | 32.51 | 173075.73 | 0.54 | 1.59 | 5.92 |
| 2017-10-30 | 100 | 34.40 | 32.06 | 31.85 | 337772.31 | -1.05 | -3.17 | 8.45 |
| 2017-11-01 | 100 | 34.34 | 33.83 | 33.10 | 232325.30 | -0.61 | -1.77 | 5.81 |
| 2015-06-16 | 100 | 33.48 | 32.35 | 29.61 | 153130.61 | 0.66 | 2.08 | 5.24 |
| 2015-06-09 | 100 | 33.34 | 33.34 | 30.46 | 204438.47 | 3.03 | 10.00 | 7.00 |
| 2017-10-27 | 100 | 33.20 | 33.11 | 31.45 | 333824.31 | 0.70 | 2.16 | 8.35 |
| 2015-06-18 | 100 | 32.89 | 31.20 | 30.38 | 86382.05 | -0.12 | -0.38 | 2.96 |
| 2017-10-26 | 100 | 32.70 | 32.41 | 28.92 | 501915.41 | 2.68 | 9.01 | 12.56 |
| 2015-06-17 | 100 | 32.20 | 31.33 | 29.80 | 90811.36 | -1.03 | -3.18 | 3.11 |
| 2017-11-02 | 100 | 31.80 | 30.45 | 30.45 | 312481.06 | -3.38 | -9.99 | 7.82 |
| 2017-10-23 | 100 | 31.16 | 29.79 | 28.90 | 466494.47 | 1.46 | 5.15 | 11.68 |
| 2015-05-22 | 100 | 30.99 | 29.54 | 28.53 | 209382.62 | 1.32 | 4.68 | 7.17 |
| 2015-06-19 | 100 | 30.98 | 28.07 | 28.07 | 76310.31 | -3.12 | -10.00 | 2.61 |
| 2015-06-08 | 100 | 30.90 | 30.31 | 28.40 | 179868.05 | 2.12 | 7.52 | 6.16 |
| 2017-10-25 | 100 | 30.45 | 29.73 | 27.54 | 328947.31 | 1.68 | 5.99 | 8.23 |
| 2015-05-25 | 100 | 30.30 | 29.92 | 28.10 | 151819.52 | 0.38 | 1.29 | 5.20 |
| 2015-05-26 | 100 | 30.30 | 29.66 | 28.70 | 198210.12 | -0.26 | -0.87 | 6.78 |
| 2017-11-14 | 100 | 29.89 | 29.34 | 27.68 | 243773.23 | 1.10 | 3.90 | 6.10 |
| 2017-10-20 | 100 | 29.83 | 28.33 | 27.85 | 411570.12 | 1.17 | 4.31 | 10.30 |
当遇到有多个数据相同不好排序的时候,同时给两个条件这样当遇到相同时候看第二个索引比大小
new_data.sort_values(by=["high","p_change"],ascending=False)
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2015-06-10 | 100 | 36.35 | 33.85 | 32.23 | 269033.12 | 0.51 | 1.53 | 9.21 |
| 2015-06-12 | 100 | 35.98 | 35.21 | 34.01 | 159825.88 | 0.82 | 2.38 | 5.47 |
| 2017-10-31 | 100 | 35.22 | 34.44 | 32.20 | 361660.88 | 2.38 | 7.42 | 9.05 |
| 2015-06-15 | 100 | 34.99 | 31.69 | 31.69 | 199369.53 | -3.52 | -10.00 | 6.82 |
| 2015-06-11 | 100 | 34.98 | 34.39 | 32.51 | 173075.73 | 0.54 | 1.59 | 5.92 |
| 2017-10-30 | 100 | 34.40 | 32.06 | 31.85 | 337772.31 | -1.05 | -3.17 | 8.45 |
| 2017-11-01 | 100 | 34.34 | 33.83 | 33.10 | 232325.30 | -0.61 | -1.77 | 5.81 |
| 2015-06-16 | 100 | 33.48 | 32.35 | 29.61 | 153130.61 | 0.66 | 2.08 | 5.24 |
| 2015-06-09 | 100 | 33.34 | 33.34 | 30.46 | 204438.47 | 3.03 | 10.00 | 7.00 |
| 2017-10-27 | 100 | 33.20 | 33.11 | 31.45 | 333824.31 | 0.70 | 2.16 | 8.35 |
| 2015-06-18 | 100 | 32.89 | 31.20 | 30.38 | 86382.05 | -0.12 | -0.38 | 2.96 |
| 2017-10-26 | 100 | 32.70 | 32.41 | 28.92 | 501915.41 | 2.68 | 9.01 | 12.56 |
| 2015-06-17 | 100 | 32.20 | 31.33 | 29.80 | 90811.36 | -1.03 | -3.18 | 3.11 |
| 2017-11-02 | 100 | 31.80 | 30.45 | 30.45 | 312481.06 | -3.38 | -9.99 | 7.82 |
| 2017-10-23 | 100 | 31.16 | 29.79 | 28.90 | 466494.47 | 1.46 | 5.15 | 11.68 |
| 2015-05-22 | 100 | 30.99 | 29.54 | 28.53 | 209382.62 | 1.32 | 4.68 | 7.17 |
| 2015-06-19 | 100 | 30.98 | 28.07 | 28.07 | 76310.31 | -3.12 | -10.00 | 2.61 |
| 2015-06-08 | 100 | 30.90 | 30.31 | 28.40 | 179868.05 | 2.12 | 7.52 | 6.16 |
| 2017-10-25 | 100 | 30.45 | 29.73 | 27.54 | 328947.31 | 1.68 | 5.99 | 8.23 |
| 2015-05-25 | 100 | 30.30 | 29.92 | 28.10 | 151819.52 | 0.38 | 1.29 | 5.20 |
| 2015-05-26 | 100 | 30.30 | 29.66 | 28.70 | 198210.12 | -0.26 | -0.87 | 6.78 |
| 2017-11-14 | 100 | 29.89 | 29.34 | 27.68 | 243773.23 | 1.10 | 3.90 | 6.10 |
| 2017-10-20 | 100 | 29.83 | 28.33 | 27.85 | 411570.12 | 1.17 | 4.31 | 10.30 |
8.2 对索引改变为从小到大
new_data.sort_index().head()
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2015-03-02 | 100 | 12.67 | 12.52 | 12.20 | 96291.73 | 0.32 | 2.62 | 3.30 |
| 2015-03-03 | 100 | 13.06 | 12.70 | 12.52 | 139071.61 | 0.18 | 1.44 | 4.76 |
| 2015-03-04 | 100 | 12.92 | 12.90 | 12.61 | 67075.44 | 0.20 | 1.57 | 2.30 |
| 2015-03-05 | 100 | 13.45 | 13.16 | 12.87 | 93180.39 | 0.26 | 2.02 | 3.19 |
| 2015-03-06 | 100 | 14.48 | 14.28 | 13.13 | 179831.72 | 1.12 | 8.51 | 6.16 |
8.3 对Series排序
取其中一列
s2 =new_data["price_change"]
s2
简单一点,因为直接就只有一values
s2.sort_values(ascending=False)
s2.sort_index()
9 DataFrame运算与统计
9.1 使用describe完成综合统计
new_data.describe()
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| count | 643.000000 | 643.000000 | 643.000000 | 643.000000 | 643.000000 | 643.000000 | 643.000000 | 643.000000 |
| mean | 100.206843 | 21.900513 | 21.336267 | 20.771835 | 99905.519114 | 0.018802 | 0.190280 | 2.936190 |
| std | 5.245008 | 4.077578 | 3.942806 | 3.791968 | 73879.119354 | 0.898476 | 4.079698 | 2.079375 |
| min | 100.000000 | 12.670000 | 12.360000 | 12.200000 | 1158.120000 | -3.520000 | -10.030000 | 0.040000 |
| 25% | 100.000000 | 19.500000 | 19.045000 | 18.525000 | 48533.210000 | -0.390000 | -1.850000 | 1.360000 |
| 50% | 100.000000 | 21.970000 | 21.450000 | 20.980000 | 83175.930000 | 0.050000 | 0.260000 | 2.500000 |
| 75% | 100.000000 | 24.065000 | 23.415000 | 22.850000 | 127580.055000 | 0.455000 | 2.305000 | 3.915000 |
| max | 233.000000 | 36.350000 | 35.210000 | 34.010000 | 501915.410000 | 3.030000 | 10.030000 | 12.560000 |
9.2 使用idxmin、idxmax完成最大值最小值的索引
返回最大值和最小值位置
new_data.idxmax()
open 2018-02-26
high 2015-06-10
close 2015-06-12
low 2015-06-12
volume 2017-10-26
price_change 2015-06-09
p_change 2015-08-28
turnover 2017-10-26
dtype: object
9.3 使用cumsum等实现累计分析
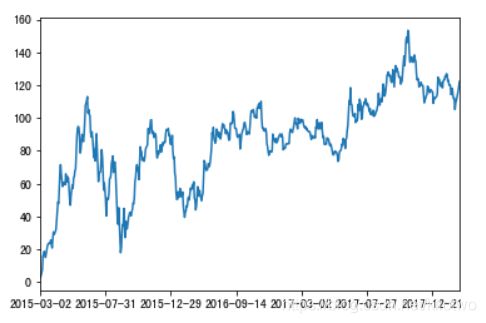
#累计统计函数 计算前面几行累加结果
new_data["p_change"].sort_index().cumsum().plot()
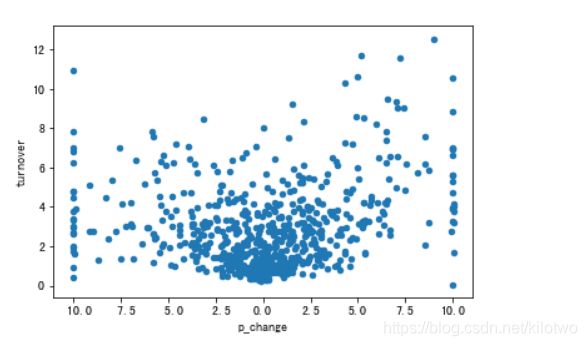
new_data.plot("p_change","turnover","scatter")

9.4 算术运算
new_data["open"]+10
2018-02-27 110
2018-02-26 243
2018-02-23 110
2018-02-22 110
2018-02-14 110
2018-02-13 110
2018-02-12 110
2018-02-09 110
2018-02-08 110
2018-02-07 110
2018-02-06 110
9.5 逻辑运算函数 query() isin()
应用query实现数据的筛选
应用isin实现数据的筛选
- query() 查找满足条件的元素
- isin() 判断某元素是否在数列中
#直接输入条件字符串
new_data.query("high>24")
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 100 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 2.39 |
| 2018-01-30 | 100 | 24.08 | 23.83 | 23.70 | 32420.43 | 0.05 | 0.21 | 0.81 |
| 2018-01-29 | 100 | 24.63 | 23.77 | 23.72 | 65469.81 | -0.73 | -2.98 | 1.64 |
| 2018-01-26 | 100 | 24.74 | 24.49 | 24.22 | 50601.83 | 0.11 | 0.45 | 1.27 |
| 2018-01-25 | 100 | 24.99 | 24.37 | 24.23 | 104097.59 | -0.93 | -3.68 | 2.61 |
new_data["turnover"].isin([4.19])
2018-02-27 False
2018-02-26 False
2018-02-23 False
2018-02-22 False
2018-02-14 False
2018-02-13 False
2018-02-12 False
2018-02-09 False
2018-02-08 False
2018-02-07 False
2018-02-06 False
9.6 布尔索引
应用逻辑运算符号实现数据的逻辑筛选
布尔索引
new_data[new_data["open"]>100]
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-26 | 233 | 23.78 | 23.53 | 22.8 | 60985.11 | 0.69 | 3.02 | 1.53 |
9.7 min max
- 使用max完成最大值计算
#按列
new_data.max()
open 233.00
high 36.35
close 35.21
low 34.01
volume 501915.41
price_change 3.03
p_change 10.03
turnover 12.56
dtype: float64
2-09 False
2018-02-08 False
2018-02-07 False
2018-02-06 False
### 9.6 布尔索引
应用逻辑运算符号实现数据的逻辑筛选
布尔索引
`new_data[new_data["open"]>100]`
| | open | high | close | low | volume | price_change | p_change | turnover |
| ---------: | ---: | ----: | ----: | ---: | -------: | -----------: | -------: | -------: |
| 2018-02-26 | 233 | 23.78 | 23.53 | 22.8 | 60985.11 | 0.69 | 3.02 | 1.53 |
### 9.7 min max
1. 使用max完成最大值计算
#按列
new_data.max()
open 233.00
high 36.35
close 35.21
low 34.01
volume 501915.41
price_change 3.03
p_change 10.03
turnover 12.56
dtype: float64