Pandas 学习笔记基础知识汇总
一、pandas读取和存储excel、csv文件
1、df1 = pd.read_excel( file_path ,index_col = ‘col2’ ) 设置索引列为col2,读取出来的数据是dataframe格式
2、df2 = pd.read_csv( serprator =’::’,engine = python) 设置分隔符和读取引擎
3、dataframe.to_excel( file_path ) dataframe.to_csv( )
4、pd.read_excel(filepath,skiprows=2) 跳过前2行
二、pandas loc定位的使用
1、df.loc[] 可以查询,可以赋值,按单个label查询,使用条件查询,切片区间查询(行列可以同时设定区间),可以跟函数
2、df.loc[].str.replace() 可以跟str相关函数str.startwith , str.endwith
3、df.loc[lambda df: (df[‘age’] > 18) & (df[‘age’] < 35) , : ] 筛选年龄介于18到35的行,列不筛选所以冒号梁板没有内容
df.loc[df[‘age’] < 18 , ‘type’] = ‘少年’ 新增一个列,对小于18岁的,类型是少年
4、一维的数据是series,二维是数据是dataframe
5、pandas的与是& python的与是and
6、df.iloc[] df.where() df.query()
三、pandas新增或修改数据列
1、直接赋值
2、df.apply()方法,沿着series的某个轴逐个数据应用函数。
3、df.assign()可以同时添加多个列
四、pandas的统计函数
1、通过df.describe() 可以发现,有mean min max std quantile等
2、df.[‘name’].unique() 去重后返回一个数组
3、df.[‘class’].value_counts() 统计不同值出现过几次
4、df.cov() 协方差矩阵,为正是通向变化
5、df.corr() 相关系数矩阵,-1~1 相关性大小和方向
6、使用方法df[‘age’].cov(df[‘class’]) ,也可以查看整改表的相关系数 df.corr()
五、pandas对缺失值的处理(数据清洗)
1、isnull和notnull,判断是否空值,可以用于dataframe和series,可以判断某一列,或者某个范围
2、df.dropna() 删除空行参数可以指定行数和列,axis=columns(index) , how=any(all) ,inplace=True(False)
3、df.fillna(‘分数’,0) 填充空值 , df.fillna(‘姓名’,method=“ffill”) 使用前面的姓名填充缺失的姓名(适用于excel中姓名列相同姓名被合并了单元格的情况)
4、df.to_excel(new_filepath,index=False) 把df存到新的excel文件中
5、pd.read_csv() 参数engine=python的意义
六、pandas处理copy报警
1、settingwithcopywarning,视图view的修改会影响原df,copy是一个副本不会影响原df
2、df.loc[condition,‘总分’] =df[’'数学] + df[‘语文’] 通过直接赋值的方式避开警告
3、也可以先创建一个copy,对copy进行整理后再赋值给原df
七、pandas数据排序
1、series.sort_values(acending=False,inplace=True) 对series进行降序排序,替换原数据
2、dataframe.sort_values(by[‘col1’,‘col2’], ascending=[False , True], inplace = True) 对dataframe的col1和col2列进行降序排序,替换原数据,可以单独设置每个列的升降序
八、pandas对字符串的处理
1、只能对series操作,并且只能对string类型操作
2、df[‘name’].str.strip() 删除name中的空格
3、其他函数:df.loc[].str.replace() 可以跟str相关函数str.startwith() , str.endwith(),str.contains(),str.isnumeric() , str.len() , str.split() , str.slice() 切片 , 多个函数可以连续操作str.func1().str.func2() , str都要写
4、正则表达式的语法方式:str.loc[‘日期’].str.replace([‘年月日’],’’) 把日期中的年 月 日都替换成空
九、pandas的axis参数
1、axis=0或者index是对行操作,axis=1或者columns是对列操作
2、df.drop(‘A’,axis=1) 删除列名为A的这一列, df.drop(‘A’,axis=0) 删除行名为A的这一行
3、df.mean(axis=0) 对每一列的数据相加并求平均数,因为axis=0那么每一行 的数据都要动起来,参与求和和求平均的操作
4、df.mean(axis=1) 对每一行的数据求和再求平均,因为axis=1 那么 每一列 的数据要横向动起来,参与求和 求平均操作
十、pandas的索引 index的用处
1、df.set_index(‘name’,inplace=True,drop=False) 把name设置成df的index,保留原来的name列
2、查询name=‘张三’ 的所有行就可以简化成: df[‘张三’] 原来查询需要:df.loc[df['name']=='张三'] 或者 df[df['name']=='张三']
3、合理设置index提高查询效率。如果index是唯一的,pandas用哈希表优化查找
4、合理设置index提高查询效率。如果index是有序的,pandas采用二分查找
5、 % timeit 返回程序运行时间
6、df_shuffle.loc[‘name’] 打乱姓名排序
7、index有自动对齐功能,两个series相加,如果index相同,该行直接相加,如果不同则无法相加
8、使用index更多更强大的数据结构支持,如groupby , datetimeindex
十一、pandas的merge语法
1、相当于sql的join,将不同的表按key关联到一个表
2、pd.merge(left_df,right_df,how,on,sort,suffixes)
on:列名,join用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名
how:数据融合的方法, inner交集 outer并集 left完全保留左边 right完全保留右边
sort:根据dataframe合并的keys按字典顺序排序,默认是,如果置false可以提高表现。
suffixes:如果非key列名重复,通过这个参数加后缀
十二、pandas的数据合并concat 、 append 、join语法
1、concat可以给df添加行 或 列
2、pd.concat([df1,series1…] , axis=0 , join = ‘outer’ , ignore_index = False)
合并方式:inner 或 outer
合并方向:axis =1 或 0
ignore_index :是否忽略掉原来的索引,重新从0开始添加索引
4、df1.append(df2 , ignore_index = False) 只能按行合并,可以是series 可以是list
5、通过类似列表推导式给空series添加元素:
pd.concat(
[pd.dataframe( [i]) , columns=['A'] ) for i in range (5) ] ,
ignore_index = True
)
6、df1.join(df2) 可用于df间列方向的拼接操作,默认左列拼接,how=’left’
十三、merge、concat合并方法的区别
1、merge没有join、axis、ignore_index 参数 , concat没有on 、how 、suffixes 、sort参数
2、merge只能有左 右两个df或series,concat可以有多个df或series放在列表中
3、merge的参数how可以是[ right \ left \ outer \ inner]
4、concat通过join和axis来控制合并方式和方向:join可以是 [outer 或 inner] axis可以是 [ 0 或 1](index 或 columns)
十四、pandas 拆分、合并excel
1、os.mkdir() 新建文件夹
2、split_dir = f"{ work_dir}/splits" 这里的f是什么意思,还有一种u r ?
3、拆分步骤:通过iloc获取部分数据形成新的小dataframe - 通过to_excel写入新的excel表
4、for index , name in enumerate(user_name ) enumerate枚举的用法 ?
5、os.listdir(dir) 遍历文件夹下面的子文件夹或文件名 ?
十五、pandas分组统计groupby
1、df1.groupby([col1,col2] ,as_index = False ).mean() 对df1按col1 col2两列进行两个维度分组,对每个分组求平均值,如果某列不是数字类型,则不会参与求均值
2、as_index:表示是否合并col1
3、df1.groupby([col1,col2] ,as_index = False ).agg( np.sum , np.std , np.mean) 同时进行多个指标计算,类似的还有apply()
4、df1.groupby(‘col1’ ).agg({ ‘C’ : np.sum , ‘B’ : np.std }) 对分组后的C列求和,B列求标准差
5、可以通过for遍历分组后的结果 A 是列名
g = df1.groupby('A')
for name , group in g:
print(name)
print(group)
g.get_group('name1') # 获取某个分组,name1是列数据
6、pandas自带plot画图工具,默认是折线图,用法df.plot()
十六、pandas的分层索引multiindex
1、df.groupby([‘col1’,'col2]) 按多个列分组,获得的结果的索引就是多层索引
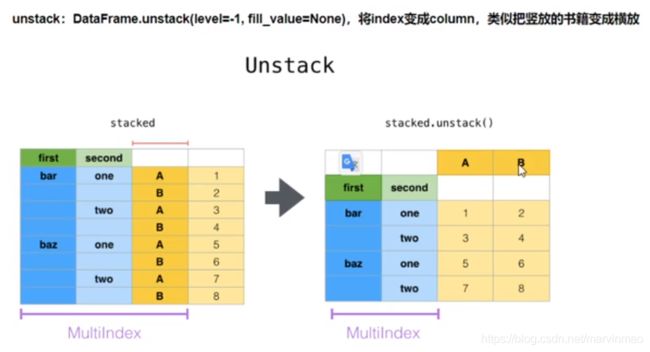
2、ser.unstack() 把第二层索引编程columns
3、df.set_index([‘col1’,'col2]) 设置分层索引,为col1 col2 两列
4、df.sort_index() 按索引排序,默认升序
5、设置索引后查询效率提高
6、同时查询多层索引: df.loc[ (‘col1’, ‘col2’) ] col1和col2在这里合并在一起作为一个复合索引,col1和col2不是一个列,比如一个是姓名张三,另一个是性别男。元组内的每个值都可以是列表或者单个值
7、同时查询同级索引的多个值: df.loc[ [‘index1’,‘index2’ ] ] 这里的index1和index2是并列的一级索引,比如都是name列的值,张三和李四。这是一个并列筛选
8、slice(none) 表示筛选全部值
十七、pandas的数据转换函数map、apply 、applymap
1、map : 只用于series,实现每个 值 —> 值 的映射
2、apply: 用于series时实现 每个 值 —> 值 的映射,用于dataframe时实现某个轴(列向 或 行向)的series的处理
3、applymap:只用于dataframe,用于处理df的每个元素
4、map 可以series.map(dict ) 也可以 series.map(function)
5、apply(function) 用于series时,function接受的参数是series的每个值,
6、df.applymap(lambda x : int(x) ) 把df里面的值都转换成整数
7、函数可以其他参数
十八、pandas怎样对每个分组应用apply函数
1、数据归一化概念,提高机器学习效率
2、df.head(5) df的前5行, df.tail(5) df的后5行
3、遵从split 、 apply 、combain
十九、pandas的stack和pivot实现数据透视
1、注意与crosstab交叉表的区别
2、df[‘datetime’] = pd.to_datetime(df[‘time’] , unit=‘s’) unit时间单位,将time时间戳列格式化成时间格式
3、df[‘datetime’].dt.year 获取事件的年份,month月份,days 日期
4、df_group.unstack() 把分组数据转换成二维透视,便于用来画图,把指定的columns变成索引
5、unstack的逆操作是stack,把最内侧的index变成columns
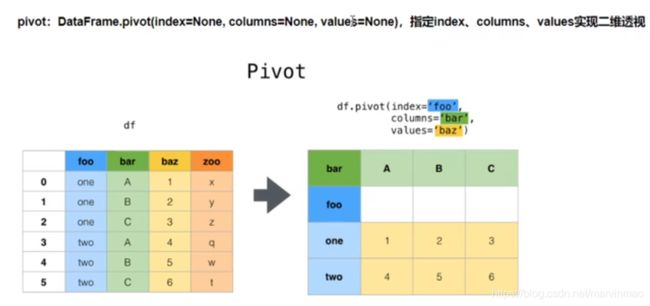
6、df.pivot( ‘col1’ ,‘col2’, ‘col3’) 对三列建立透视表

7、crosstab交叉表pd.croosstab(data.col1,data.col2).plot.bar() 通过col1,col2两列两个维度进行分别统计,并绘制柱状图
8、交叉表是用于统计分组频率的特殊透视表
二十、pandas对日期进行快速处理
1、将各种日期格式,统一映射成pandas的统一日期格式对象
2、核心方法:pd.to_datetime() 转换后的格式是pandas.timestamp对象
3、df[‘col2’].astype(‘int’) 把col2列的数据转换成 int64 格式
4、df.set_index(pd.to_datetime(df[‘日期’])) 把 日期 列转换成pandas日期对象,并设置成index索引datetimeindex
5、转换成日期对象的好处:通过loc[ ]索引快速查找,dt.month()等方法快速获取月份、年份、天数
6、通过loc[ ]切片查询时,传入的切片可以是一个时间区间,可以是年份或者月份
7、如果设置成了索引,可以通过 df.index.month 获取索引的月份
8、日期对象的相关属性:
time = pd.Timestamp('now')
# Timestamp('2020-06-09 16:30:54.813664')
time.asm8 # 返回 numpy datetime64格式(以纳秒为单位)。
# numpy.datetime64('2020-06-09T16:30:54.813664000')
time.year # 2020
time.month # 6
time.week # 24 当年第几周
time.day # 9 日
time.hour # 16
time.minute # 46
time.second # 59
time.dayofweek # 1 周几,周一为0
time.dayofyear # 161, 一年的第几天
time.weekofyear # 24 同上
time.quarter # 2 当前季度数
time.days_in_month # 30 当月有多少天
time.daysinmonth # 30 同上
time.is_leap_year # True 是否闰年,公历的
time.is_month_end # False 是否当月最后一天
time.is_month_start # False 是否当月第一天
time.is_quarter_end # False 是否当季最后一天
time.is_quarter_start # False 是否当季第一天
time.is_year_end # 是否当年最后一天
time.is_year_start # 是否当年第一天
# 如指定会返回类似 9、对于时间序列数据,可以使用 s.dt.xxx 的形式来访问它们的属性和调用它们的方法,例如:time.dt.date = time.day
10、日期对象常用的函数:
# 转换为指定时区
time.astimezone('UTC')
# Timestamp('2020-06-09 08:55:58.027896+0000', tz='UTC')
# 转换单位,向上舍入
time.ceil('s') # 转为以秒为单位
# Timestamp('2020-06-09 16:55:59+0800', tz='Asia/Shanghai')
time.ceil('ns') # 转为以纳秒为单位
time.ceil('d') # 保留日
time.ceil('h') # 保留时
# 转换单位, 为向下舍入
time.floor('h') # 保留时
# Timestamp('2020-06-09 17:00:00+0800', tz='Asia/Shanghai')
# 类似四舍五入
time.round('h') # 保留时
# 返回星期名
time.day_name() # 'Tuesday'
# 月份名称
time.month_name() # 'June'
# 将时间戳规范化为午夜,保留时区信息。
time.normalize()
# Timestamp('2020-06-09 00:00:00+0800', tz='Asia/Shanghai')
# 时间元素替换 datetime.replace,可处理纳秒。
time.replace(year=2019) # 年份换为2019年
# Timestamp('2019-06-09 17:14:44.126817+0800', tz='Asia/Shanghai')
time.replace(month=8) # 月份换为8月
# Timestamp('2020-08-09 17:14:44.126817+0800', tz='Asia/Shanghai')
# 转为周期类型,将丢失时区
time.to_period(freq='h') # 周期为小时
# Period('2020-06-09 17:00', 'H')
# 转为指定时区
time.tz_convert('UTC') # 转为 utc 时间
# Timestamp('2020-06-09 09:14:44.126817+0000', tz='UTC')
# 本地化时区转换
time = pd.Timestamp('now')
time.tz_localize('Asia/Shanghai')
# Timestamp('2020-06-09 17:32:47.388726+0800', tz='Asia/Shanghai')
time.tz_localize(None) # 删除时区
二十一、pandas处理日期索引的缺失
-
方法一
1、df_date = df.set_index( df[‘日期’] ) 把日期列设置成索引,把新的dataframe赋值给df_date
2、把日期转换成日期对象:df_date = df_date.set_index( pd.to_datetime( df_date.index ))
3、创建连续的日期序列:pdates = pd.date_range( start = ‘2020-1-1’ , end = ‘2020-12-31’ ) 创建2020年一整年的日期序列
4、df_date_new = df_date.reindex( pdates , fill_value =0 ) # 设置新的日期索引为pdates序列
-
方法二
1、df_new= df.set_index( pd.to_datetime( df[‘日期’] )).drop(“日期” , axis = 1) 把dataframe的索引变成日期对象的索引
2、df_new = df_new.resample(‘D’).mean().fillna(0) 按天采样 参数可以是Y M D H,按每天的平均值采样,填充空值为0
3、如果是2D,表示两天采样一次
二十二、pandas实现excel的vlookup
1、表1有学号、语文成绩、数学成绩3列,表2有学号、姓名、性别3列。合并到表3有学号、姓名、性别、语文成绩、数学成绩5列。
表1:
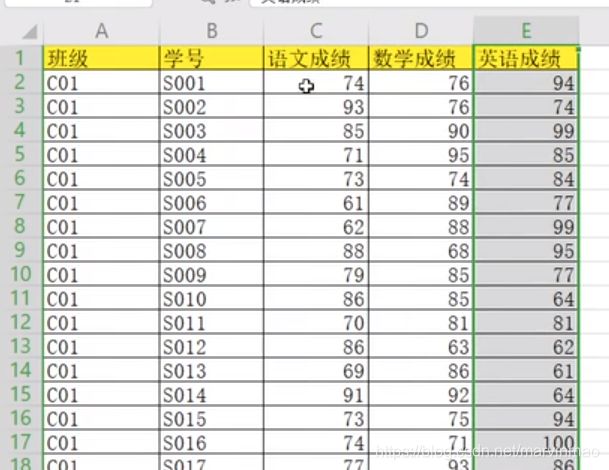
表2:
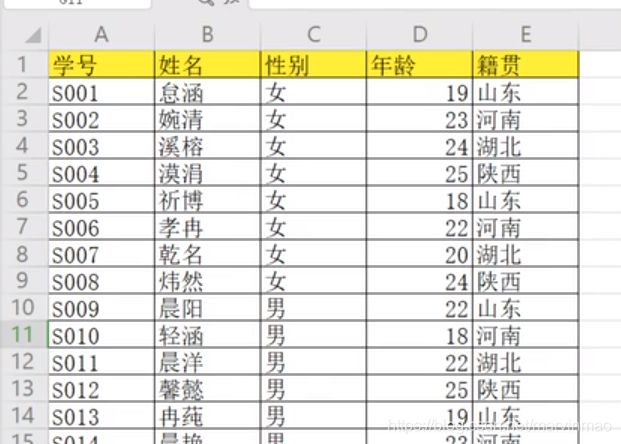
表3:

2、pd.read_excel() 读取成绩信息score_df,学生信息stu_df
3、df_merge = pd.merge(left = score_df , right = stu_df , left_on = ‘学号’, right = ‘学号’)
4、df_merge.columns.to_list() 把合并的df 列名转成list
5、修改df的列顺序?
6、df_merge.to_excel(file_path , index = False) 重新存到excel表
二十三、python读取excel绘制折线图
1、使用pyecharts,安装和引入pyecharts
2、实例化折线图对象:line = Line()
3、添加X轴:line.add_xaxis( df.index.to_list() )
4、添加Y轴:
line.add_yaxis("开盘价" , df['open'] .round(2).to_list() ) # 第一个折线名称是 开盘价 ,引用的数据是df['open'] 保留两位小数
line.add_yaxis("收盘价" , df['close'] .round(2).to_list() ) # 第一个折线名称是 收盘价 ,引用的数据是df['close'] 保留两位小数
5、配置图标:
line.set_global_opts(
title_opts = opts.TitleOpts( title = '百度股票2019年' ),
tooltip_opts = opts.TooltipOpts(trigger = "axis" , axis_pointer_type = "cross" )
)
6、绘制图像:
line.render_notebook( )
二十四、Pandas结合Sklearn机器学习
-
案例:泰坦尼生存预测
-
历史训练数据:
1、输入乘客信息:性别、年龄、是否有父母兄弟、仓位情况、票务信息
2、输出信息:是否存活
3、数据样式:

-
机器学习模型:
1、输入不知道是否存活的乘客信息
2、输出这个人存活的概率
-
代码如下:
#!/usr/bin/env python # coding: utf-8 # ## 步骤1:获取数据 import pandas as pd df_train = pd.read_csv( "titanic_train.csv" ) df_train # 挑两列作为是否存活的特征 feature_cols = ['Pclass','Parch'] X = df_train.loc[:,feature_cols] # 选取特征列的数据 X.head() # 提取是否存活的列,作为预测的目标 y = df_train.Survived y.head() # ## 步骤2:训练模型 from sklearn.linear_model import LogisticRegression # 创建模型对象 logreg = LogisticRegression() # 实现模型训练 logreg.fit(X , y) # ## 步骤3:对于未知数据使用模型 # 找一个历史数据中心不存在的数据 X.drop_duplicates().sort_values(by=['Pclass','Parch']) # 预测这个数据存活的概率,结果为1表示存活 logreg.predict([[2,4]]) # 存活的概率为0.65021763 logreg.predict_proba([[2,4]])