关系型数据库主要考点
附上某网的对应的教学视频,希望可以帮到大家:链接:https://pan.baidu.com/s/1dHitliqfADxMmcr2BEznBQ
提取码:584f
关系型数据库主要考点
为什么要使用索引?
1. 快速查询数据。
什么样的信息可以成为索引
1. 主键,唯一键以及普通键等
数据结构
1. 生成索引,建立二叉查找树进行二分查找
2. 生成索引,建立B-Tree结构进行查找
3. 生成索引,建立B+ -Tree结构进行查找
4. 生成索引,建立hash结构进行查找
二叉数(左:平衡二叉树(左节点比右节点的高度小于等于1),右:线性二叉树):

B-Tree:

定义:
1. 根节点至少包括两个孩子。
2. 数中每个节点最多含有m个孩子(m>2)
3. 除根节点和叶节点外,其他每个节点至少有ceil(m/2)个孩子
4. 所有叶子节点都位于同一层
5. 假设每个非终端结点中包含有n个关键字信息,其中:
1. Ki(i=1…n)为关键字,且关键字按顺序升序排列K(i-1) < ki
2. 关键字的个数n必须满足:[ceil(m/2)-1]<=n<=m-1
3. 非叶子结点的指针:P[1],P[2],…P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其他P[i]指向关键字属于(K[i-1],K[i])的子树
B+ -Tree
结构图如下:

定义:

结论:B+ -Tree更适合用来做储存索引
1. B+ 树的磁盘读写代价更低
2. B+ 树的查询效率更加稳定
3. B+ 树更有利于对数据库的扫描
密集索引和稀疏索引的区别
1. 密集索引文件中的每一个搜索码值都对应一个索引值
2. 稀疏索引文件只为索引码的某些值建立索引项

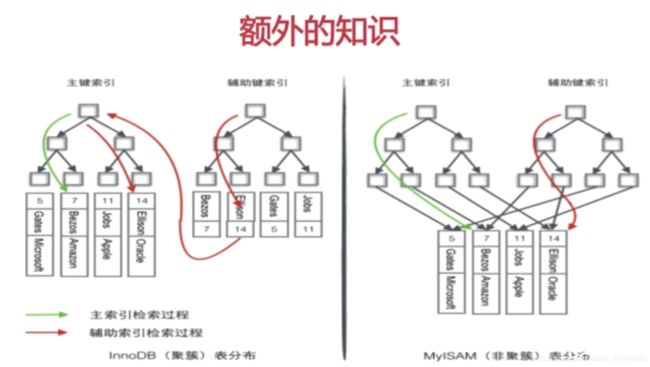
InnoDB
- 若一个主键被定义,该主键则作为密集索引。
- 若没有主键被定义,则该表的第一个唯一非空索引则作为密集索引
- 若以上条件都不满足,innoDB内部会生成一个隐藏主键(密集索引)
- 非主键索引存储相关键位和对应的主键值,包含两次查找
如何定位并优化慢sql
1. 根据慢日志定位慢查询sql
2. 使用explain等工具分析sql
3. 修改sql或者尽量让sql走索引
查询变量展示:show variables like '%quer%';
打开慢日志查询记录:set global slow_query_log = on;
设置慢查询时间为超过1秒:set global long_query_time = 1;(需重新连接数据库)
查看已经记录下来的慢查询:show status like '%slow_queries%';
使用explain,分析:explain select merchant_id from sxw_pos_pay order by merchant_id desc;
###explain关键字段分析:

type:

extra:

1. 最左前缀匹配原则,非常重要的原则,MySQL会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
2. =和in可以乱序,MySQL的查询优化器会帮你优化成索引可以识别的形式。
联合索引的最左匹配原则的成因
对于联合索引,默认会对第一个字段进行绝对排序,再对后面字段进行排序
索引是建立的越多越好吗
1. 数据量小的表不需要建立索引,建立会增加额外的索引开销
2. 数据变更需要维护索引,因此更多的索引意味着更多的维护成本
3. 更多的索引意味着也需要更多的空间
myisam
加读锁:lock tables sxw_pos_pay read;
加写锁:lock tables sxw_pos_pay write;
释放锁:unlock tables;
innoDB
是否自动提交:show variables like 'autocommit';
关闭自动提交:set autocommit = 0;
加共享锁:select * from table lock in share mode;
MyISAM与InnoDB关于锁方面的区别是什么
myisam默认用的是表级锁,不支持行级锁。
innodb不走索引时整张表会被锁住,查询用的是表级锁,innodb再sql没有用到索引的时候用的是表级锁,sql用到索引的时候用的是行级锁及gap锁。
innodb支持事务的同时,相对于myisam有更大的开销。innodb有且仅有一个密集索引,是和索引绑在一起的,通过辅助索引需要查询两次,先查到主键,再由主键查到数据。
myisam是稀疏索引,数据、文件是分离的,索引保存的是数据文件的指针,主键索引和辅助索引是独立的,在纯检索的系统中性能较高。
MyIsam适合的场景
1:频繁执行全表count语句
2:对数据进行增删改的频率不高,查询非常频繁
3:没有事务
InnoDB适合的场景
1:数据增删改查都相当频繁
2:可靠性要求比较高,要求支持事务
数据库锁的分类
1:按锁的粒度划分,可分为表级锁,行级锁,页级锁
2:按锁级别划分,可分为共享锁,排它锁
3:按加锁方式分,可分为自动锁,显式锁
4:按操作划分,可分为DML锁,DDL锁
5:按使用方式分,可分为乐观锁,悲观锁
数据库事务的四大特性(ACID)
1:原子性(atomic)-->事务要么全部成功,要么全部失败,
2:一致性(consistency)-->保证数据从一个一致状态转变为另外一个一致状态,满足完整性约束
3:隔离性(isolation)--> 多个事务并发执行时,一个事务的执行,不应该影响另一个事务的执行
4:持久性(durability)-->一个事务对数据库进行了修改,那么这个修改应该一致保存在数据库中,当设备故障,保证已发生改变的事务不能丢失
事务隔离级别以及各级别下的并发访问问题
1:更新丢失(一个事务的更新覆盖了另一个事务的更新)--- MySQL所有事务隔离级别在数据库层面上均可避免
2:脏读(一个事务读到另一个事务,未提交的更新数据)---->read-committed事务隔离级别上可避免
3:不可重复读(事务A多次读取同一数据,事务B在事务A读取的过程中对数据进行了更新并提交,导致事务A多次读取的数据不一致)-->repeatable-read事务隔离级别以上可以避免
4:幻读(事务A读取与搜索条件相关的若干行,事务B修改事务A查出的结果集)---serializable事务隔离级别可避免
查询事务隔离级别:select @@tx_isolation;
设置事务隔离级别为:set session transaction isolation level read uncommitted;
set session transaction isolation level read committed;
start transaction;
回滚:rollback;
提交:commit;
| 事务隔离级别 | 更新丢失 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| 未提交读 | 避免 | 发生 | 发生 | 发生 |
| 已提交读 | 避免 | 避免 | 发生 | 发生 |
| 可重复读 | 避免 | 避免 | 避免 | 发生 |
| 串行化 | 避免 | 避免 | 避免 | 避免 |
InnoDB可重复读隔离(RR)级别如下如何避免幻读
1. 表象:快照读(非阻塞读)--伪MVCC
2. 内在:next-key锁(行锁+gap锁)
3. 在可重复读,串行化级别下都支持gap锁,
当前读和快照读
1. 当前读:select ...... lock in share mode,select .......for update
2. 当前读:update,delete,insert
3. 快照读:不加锁的非阻塞读,select
备注:读取的是当前事务的最新版本,读取之后要保证其他事务不能修改当前事务,对读取的事务加锁
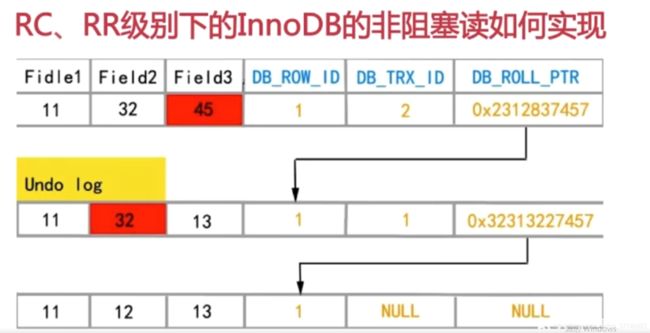
RC(READ-COMMITTED) 、RR(REPEATABLE-READ)级别下的InnoDB的非阻塞读如何实现
1. 数据行里的DB_TRX_ID,DB_ROLL_PTR,DB_ROW_ID字段
2. undo日志
3. read view(可见性判断当我们执行快照读时,针对我们查询的数据创建一个read view)
总结:
在RR级别下,在开启事务后的第一条快照读会创建一个快照,即read view.将当前活跃的事务记录起来,此后调用快照读的时候,使用的是同一个read view。在RC级别下,每次调用快照读时,都会创建一个新的快照。
innodb在rc,rr级别下支持非阻塞读,非阻塞就是所谓的mvcc,innodb非阻塞读,实现了仿照版的mvcc,读不加锁,读写不冲突,在读多写少。没有实现多版本共存,在undolog中,只是串行化实现,不属于多版本共存。
非阻塞读图示:
第一步:

第二步:
对主键索引或者唯一索引会用Gap锁吗
1:如果where条件全部命中,则不会用gap锁,只会加记录锁
2:如果where条件部分命中或者全不命中,则会加gap锁
Gap锁会用在非唯一索引或者不走做索引的当前读中
1:非唯一索引
2:不走索引
锁小结
- myIsam与innodb关于锁方面的区别是什么
- 数据库事务的四大特性
- 事务隔离级别以及各个级别下的并发访问问题
- innodb可重复读隔离级别下如何避免幻读
- rc,rr级别下的innodb的非阻塞读如何实现
语法部分:
a:group by
满足select子句中的列名必须为分组列或列函数
列函数对于group by子句定义的每个组个返回一个结果
b:having
通常与group by子句一起使用
where过滤行,having过滤组
出现在同一sql的顺序:where>group by >having