Python数据分析 - 机器学习笔记:第一章数据分析 - 1.3.2.索引和切片
前言:本文是学习网易微专业的《python全栈工程师》 中的《数据分析 - 机器学习工程师》专题的课程笔记,欢迎学习交流。
一、课程目标
- 掌握
Series的索引和切片操作方法 - 掌握
DataFrame的索引和切片操作方法
二、详情解读
2.1.Series对象
2.1.1.Series对象的索引
import numpy as np
import pandas as pd
g = np.array([
27466.15, 24899.3, 19610.9, 19492.4,
17885.39, 17558.76, 15475.09, 12170.2
])
gdp = pd.Series(g, index=['shanghai', 'beijing', 'guangzhou', 'shenzhen', 'tianjin', 'chongqing', 'suzhou', 'chengdu'])
gdp
运行结果:

# 根据标签索引取值,可以看做是字典的键
gdp['suzhou'] # 15475.09
# Series 对象具有类字典性
gdp['hanghaou'] = 11050.5 # 增加一项
# 另外一种访问方法
gdp.suzhou # 15475.09
# 下标可以是列表
gdp[['suzhou', 'shanghai', 'beijing']]
运行结果:

# 条件判断
gdp > 20000
运行结果:
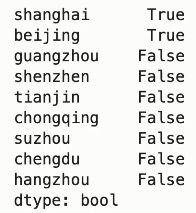
gdp[gdp>20000]
运行结果:

2.1.2.Series对象的切片
切片,注意:包含结束值
gdp['tianjin': 'suzhou']
运行结果:

尽管有标签,但是,依据位置索引,依然有效
gdp[2] # 19610.90
用标签索引切片,不包含结束
gdp[2: 6]
运行结果:

制造混乱:当标签索引是整数时,用数字下标切片会导致混乱
s = gd.Series(np.random.randn(4), index=[1, 3, 5, 7])
s
运行结果:

s[1] # 这里 1 是标签索引,2.444209
s[1: 3] # 这里1~3是位置索引
运行结果:

混乱的解决方案:s.iloc?表示位置索引,s.loc?表示标签索引
s.iloc[1] # 这里的 1 是位置索引 -0.495350
s.iloc[1: 3] # 这里也是位置索引
s.loc[3] # 这里的 3 是标签索引 -0.495350
2.2.DataFrame对象
population = pd.Series([2415.27, 2151.6, 1270.08], index=["shanghai", "beijing", "guangzhou"])
gdp = pd.Series([27466, 24899, 19611], index=["shanghai", "beijing", "guangzhou"])
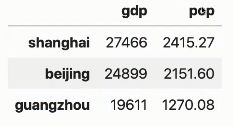
d = pd.DataFrame({
'gdp': gdp, 'pop': population})
d
运行结果:
2.2.1.DafaFrame对象的索引
# DataFrame对象的取值
d.values
运行结果:

# 获取 DataFrame 对象中某一特征的值
s = d['gdp']
s # type(s)是一个series对象类型:pandas.core.series.Series
运行结果:
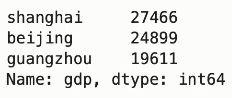
d[['gdp']] # 这里是 DataFrame 对象
运行结果:

对于DataFrame对象来说,下标是某一特征的值,如果想获取某样本的值,可以用loc
d['shanghai'] # 这里会报错,特征里只有 gdp,pop,没有shanghai
d.loc['shanghai'] # 这才是获取某样本的正确打开方式
运行结果:

获取指定值:
d.loc['shanghai', 'pop'] # 2415.27
2.2.2.DafaFrame对象的切片
注意:这里用的标签索引,是包含结束值的。
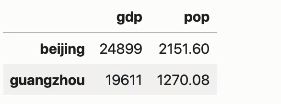
d.loc['beijing': 'guangzhou', 'pop']
运行结果:

d.loc["beijing": "guangzhou", "gdp":"pop"]
运行结果:
增加特征
d['weather'] = ['sunny', 'rain', 'rain']
d
运行结果:

# 下面两种方式得到一样的结果
d.loc[:, 'pop': 'weather']
d[['pop', 'weather']]
运行结果:
三、课程小结
- 01
Series索引、切片 - 02
DataFrame索引、切片