Pandas快速入门教程笔记
本文内容来自阿里云Pandas快速入门
本文所用代码。已经上传Github:代码下载点击此处
文章目录
- Pandas
-
- 4.1 Pandas 介绍
-
- 4.1.1 Pandas 介绍
- 4.1.2 为什么使用Pandas?
- 4.1.3 DataFrame
- 4.1.4 MultiIndex与Panel
-
- MultiIndex
- Panel
- 4.1.5 Series
- 4.2 基本数据操作
-
- 4.2.1 索引操作
- 4.2.2 赋值操作
- 4.2.3 排序操作
- 4.3 DataFrame运算
-
- 4.3.1 算术运算
- 4.3.2 逻辑运算
- 4.3.3 统计运算
- 4.3.4 累计统计函数
- 4.3.5 自定义运算
- 4.4 Pandas绘图
- 4.5 文件的读取与存储
-
- 4.5.1 CSV文件
- 4.5.2 HDF5文件
- 4.5.3 JSON文件
- 4.6 高级处理--缺失值处理
-
- 4.6.1 如何处理NaN
- 4.6.2 不是缺失值NaN,有默认标记的。
- 4.6.3 总结
- 4.7 高级处理-数据离散化
-
- 4.7.1 数据离散化
- 4.7.2为什么要离散化
- 4.7.3如何实现离散化
- 4.8 高级处理--合并
- 4.9 交叉表与透视表
-
- 4.9.1 交叉表与透视表的作用
- 4.9.2 使用crosstab(交叉表)实现
- 4.9.3 使用pivot_table(透视表)实现
- 4.10 高级处理--分组与聚合
-
- 4.10.1 什么是分组与聚合?
- 4.10.2 分组与聚合API
- 4.10.3 星巴克零售店铺数据案例
- 总结
Pandas
基础处理
- Pandas介绍
- 核心数据结构
- DataFrame
- Panel
- Series
- 基本操作
- 运算
- 绘图
- 文件的读取与存储
高级处理
- List item
4.1 Pandas 介绍
4.1.1 Pandas 介绍
- Pandas (panel data analysis)pannel 面板数据库,源自计量经济学,用来处理三维数据。
- 以NumPy为基础,借力NumPy在计算方面性能高的优势。
- 独特的数据结构。
4.1.2 为什么使用Pandas?
- 便捷的数据处理能力;例如处理缺失数据
- 读取文件方便;支持字符串等多种数据类型的读取
- 封装了 matplolib、NumPy的画图和计算
4.1.3 DataFrame
结构: DataFrame对象是既有行索引,又有列索引的二维数组。
- 行索引:表明不同行,横向索引,参数为index
- 列索引:表明不同列,纵向索引,参数为columns
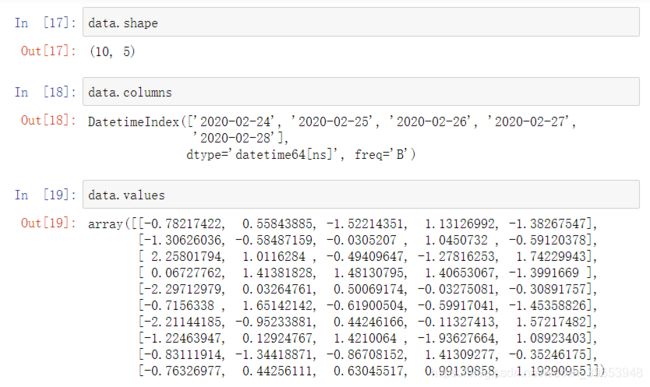
属性: - shape
- index
- columns
- values
- 转置.T
方法:# 可用来快速查看数据,当数据量比较大的时候。 - head() # 默认前五行
- tail() # 默认后五行
DataFrame索引的设置 - 1)修改行列索引
- 2)重设索引
- 3)设置新索引
2 Panel - 常把Panel看作是DataFrame的容器
3 Series - 带索引的一维数组,series结构只有行索引。
- 属性
- index
- values
总结:
- DataFrame是Series的容器
- Panel是DataFrame的容器
# 创建一个符合正态分布的十只股票五天的涨跌幅数据
stock_change = np.random.normal(0, 1, (10, 5))
# 查看numpy创建的stock_change
array([[-0.78217422, 0.55843885, -1.52214351, 1.13126992, -1.38267547],
[-1.30626036, -0.58487159, -0.0305207 , 1.0450732 , -0.59120378],
[ 2.25801794, 1.0116284 , -0.49409647, -1.27816253, 1.74229943],
[ 0.06727762, 1.41381828, 1.48130795, 1.40653067, -1.3991669 ],
[-2.29712979, 0.03264761, 0.50069174, -0.03275081, -0.30891757],
[-0.7156338 , 1.65142142, -0.61900504, -0.59917041, -1.45358826],
[-2.21144185, -0.95233881, 0.44246166, -0.11327413, 1.57217482],
[-1.22463947, 0.12924767, 1.4210064 , -1.93627664, 1.08923403],
[-0.83111914, -1.34418871, -0.86708152, 1.41309277, -0.35246175],
[-0.76326977, 0.44256111, 0.63045517, 0.99139858, 1.19290955]])
pandas DataFrame

给股票涨跌幅数据添加行索引

添加列索引

属性
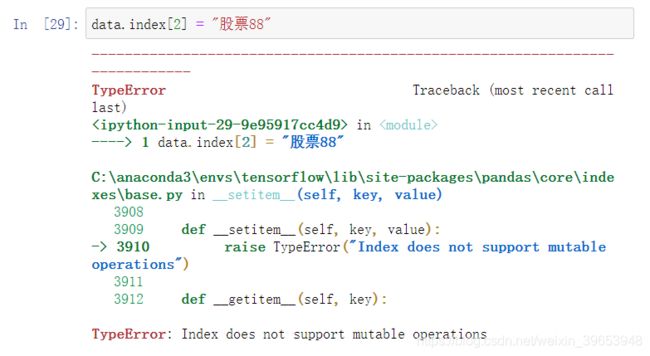
不能单独修改索引,需要重新构造新的索引。
正确修改索引值
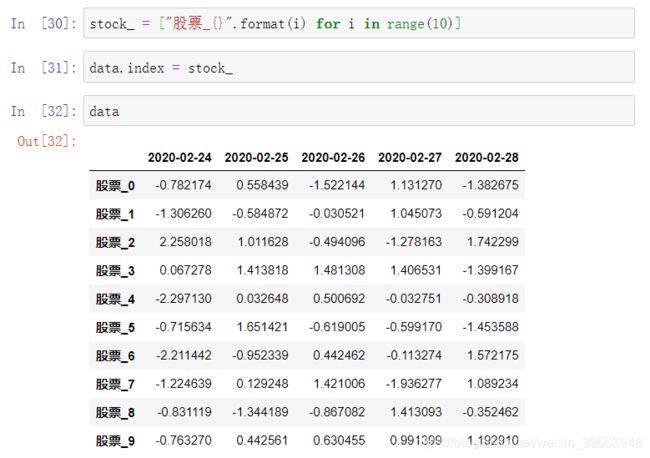
重设索引,原索引默认不丢弃
- set_index(keys, drop=True)
- keys:列索引名或者列索引名称的列表。
- drop:boole,default True。当作新的索引,删除原来的索引列。

丢弃原索引

使用字典生成DataFrame
设置新的索引

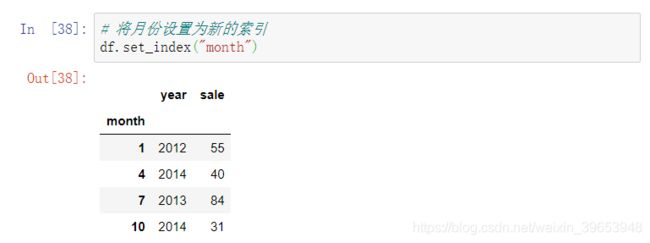
设置多个索引,以年和月份

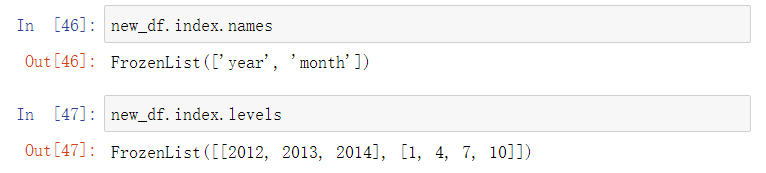
4.1.4 MultiIndex与Panel
MultiIndex
- index属性
- naems:levels的名称
- leves:每个level的元组值
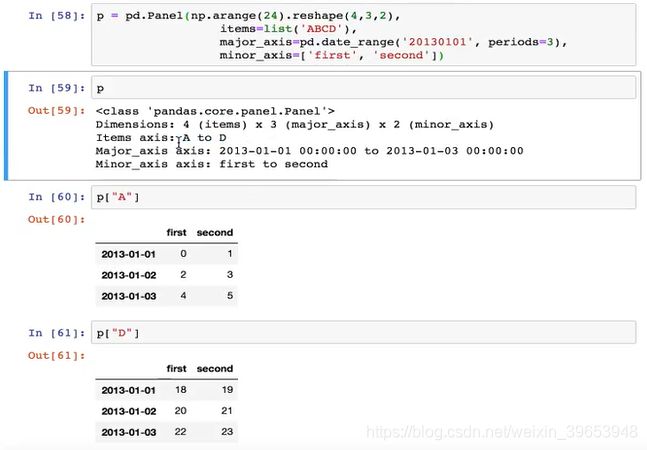
Panel
- class pandas.Panel(data=None, items=None, major_axis=None, minor_axis=None, copy=False, dtype=None)
- 存储三维数组的Panel结构
运行以下代码出现错误,因为Pandas从版本0.20.0开始弃用Panel,我安装的是pandas1.0.1,已经弃用。推荐使用DataFrame,截图来自课程。
TypeError: object() takes no parameters
p = pd.Panel(np.arange(24).reshape(4,3,2),items=list("ABCD"),
major_axis=pd.date_range("20130101", periods=3),
minor_axis=["first","second"])
# 从不同维度查看数据
p["A"]
p["D"]
p.major_xs("2013-01-01")
p.minor_xs("first")
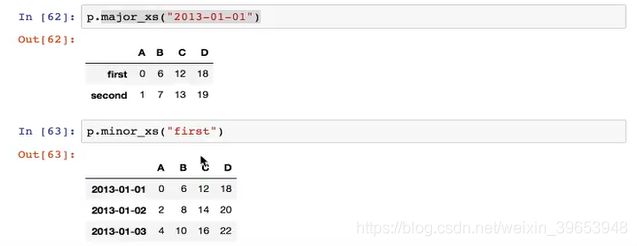
思考:如何获取dataframe中某只股票的不同时间的数据?这样的结构是什么?
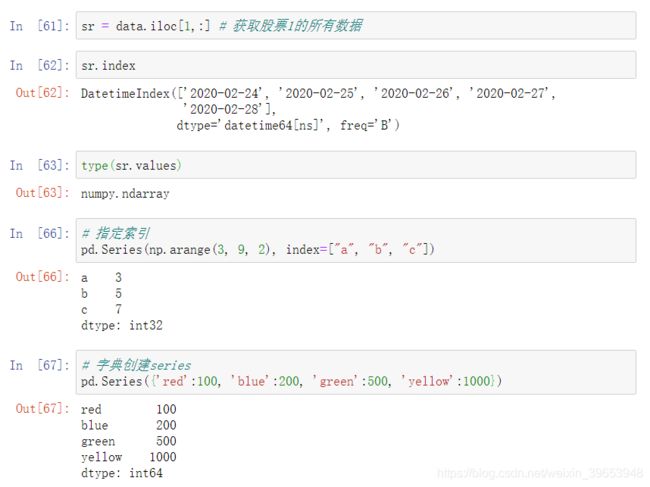
4.1.5 Series

4.2 基本数据操作
4.2.1 索引操作
- 1)直接索引
- 先列后行 - 2)按名字索引
- loc
- 3)按数字索引
- iloc
- 4)组合索引
- 数字、名字
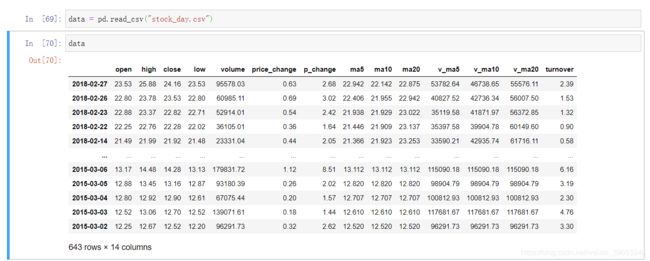
因为课程没有提供stock_day.csv等资料的下载,所以我从github上的其他工程里找到了这个股票数据,地址:stock_day.csv数据来源
只需要下载data文件夹即可,可以使用downgit下载。DownGit 链接 需要爬,你懂的!需要这个文件的,留邮箱,我发过去。



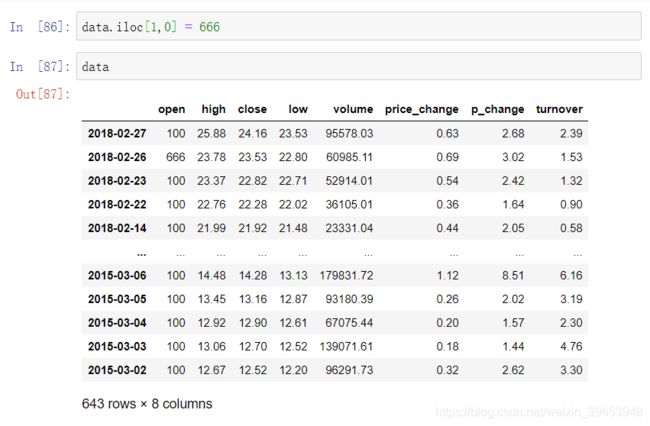
4.2.2 赋值操作

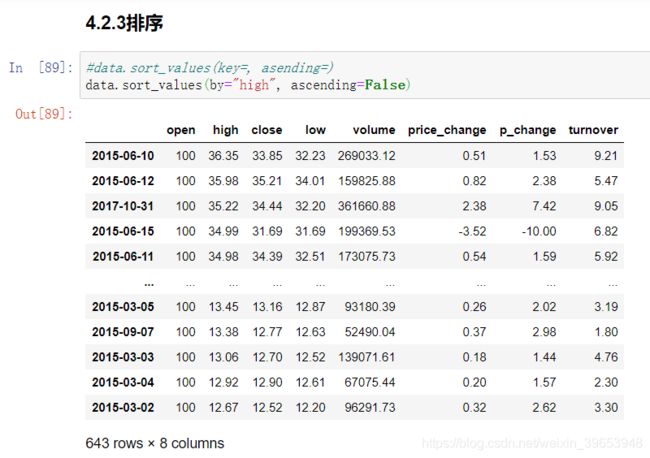
4.2.3 排序操作
- 对内容排序
- DataFrame
- Series
- 对索引排序
- DataFrame
- Series
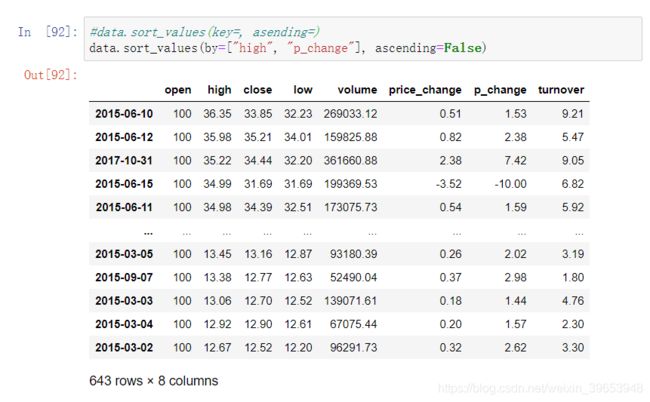
df.sort_values(key=, ascending=)
"""
key:单个键或者多个键进行排序,默认升序;
ascending = False:降序
ascending = True:升序
"""
单字段排序
多字段排序
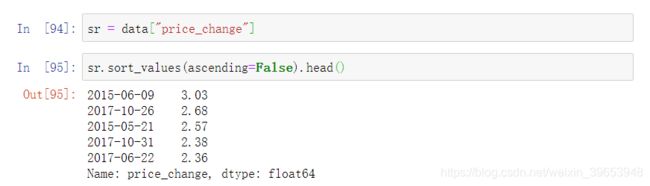
使用sort_index()方法进行排序

4.3 DataFrame运算
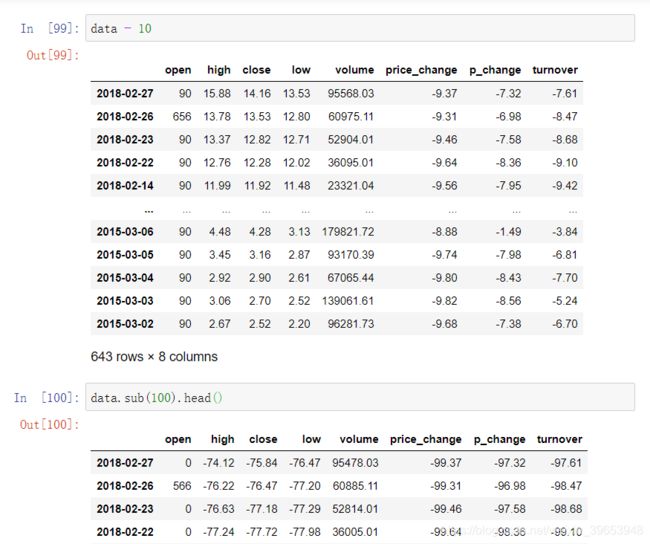
- 算数
- 加减乘除
- add()、sub()
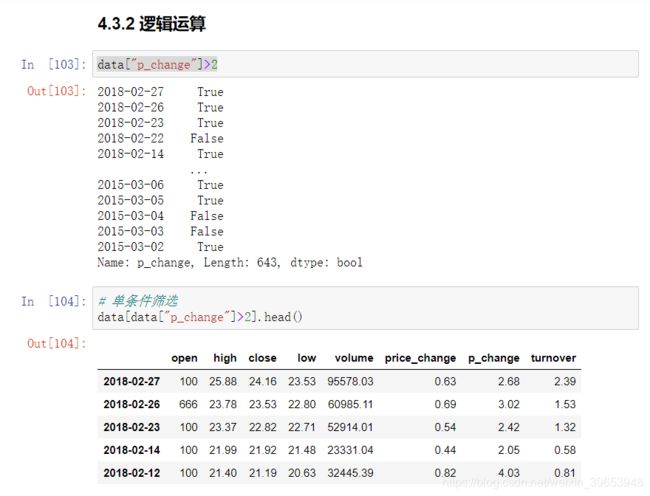
- 逻辑
- 逻辑运算符
- 可以进行布尔索引
- 逻辑运算函数
- query()
- isin()
- 逻辑运算符
- 统计
- sum mean median min max mode abs prod std var idxmax
- describe()
- idxmax()/idxmin()==np.argmax()/argmin()
- 累计统计函数
- 自定义
- apply(func, axis=0) func:自定义函数 axis:默认是列,axis=1为进行行运算。
4.3.1 算术运算

4.3.2 逻辑运算
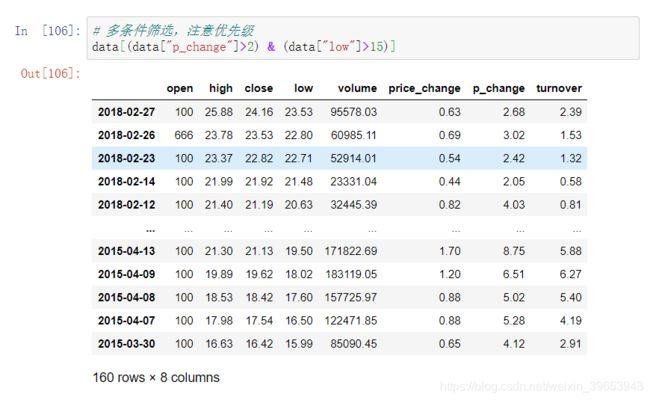

4.3.3 统计运算
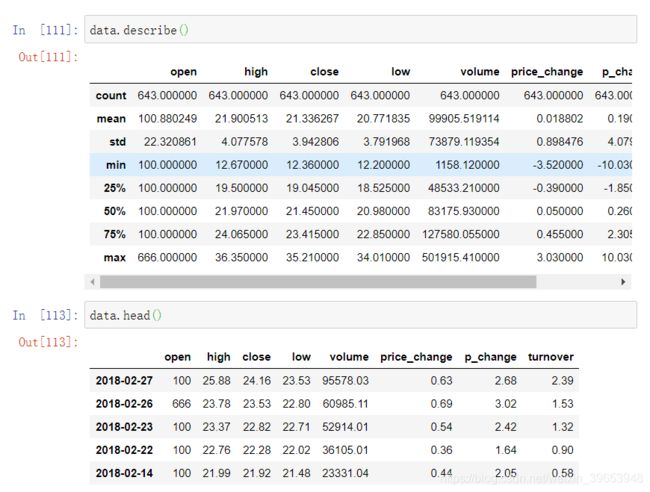

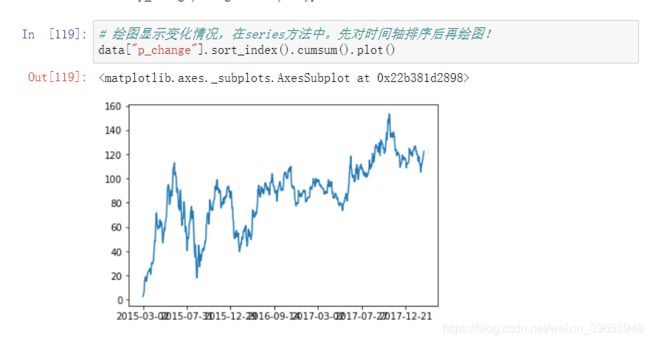
4.3.4 累计统计函数

4.3.5 自定义运算

4.4 Pandas绘图
- sr.plot()
- DataFrame.plot(x=None,y=None,kind="line)
DataFrame.plot(self, *args, **kwargs)[source]
Make plots of Series or DataFrame.
Uses the backend specified by the option plotting.backend. By default, matplotlib is used.
"""
Parameters
dataSeries or DataFrame
The object for which the method is called.
xlabel or position, default None
Only used if data is a DataFrame.
ylabel, position or list of label, positions, default None
Allows plotting of one column versus another. Only used if data is a DataFrame.
kindstr
The kind of plot to produce:
‘line’ : line plot (default)
‘bar’ : vertical bar plot
‘barh’ : horizontal bar plot
‘hist’ : histogram
‘box’ : boxplot
‘kde’ : Kernel Density Estimation plot
‘density’ : same as ‘kde’
‘area’ : area plot
‘pie’ : pie plot
‘scatter’ : scatter plot
‘hexbin’ : hexbin plot.

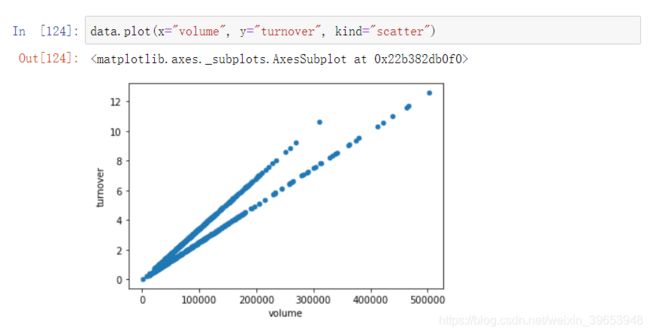
4.5 文件的读取与存储
4.5.1 CSV文件

-
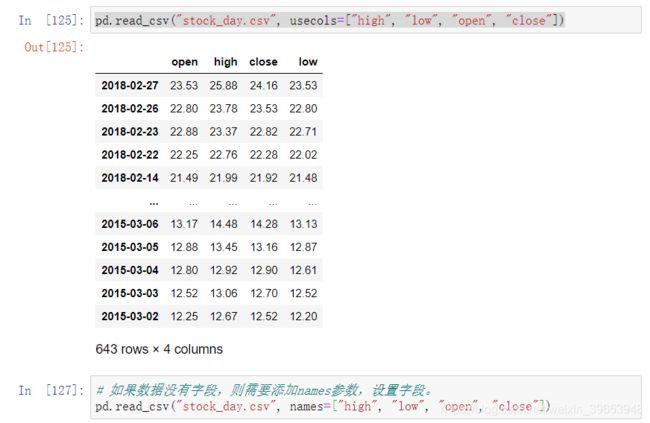
read_csv(path) --读取文件
- usecols
- names
-
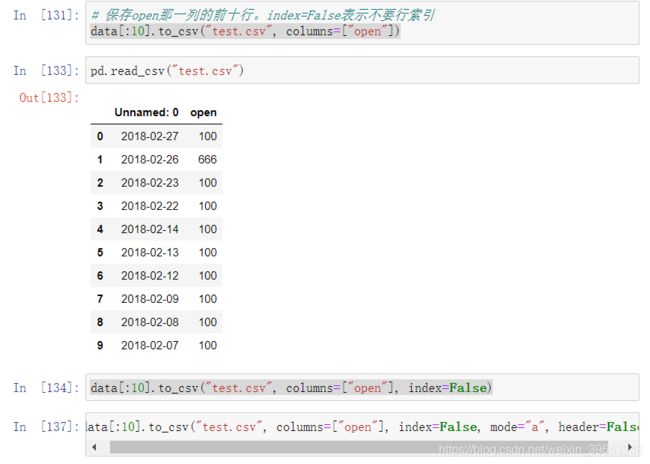
DataFrame.to_csv --写入文件
- columns
- index=False

4.5.2 HDF5文件
- 存储 三维数据的文件
- key1 DataFrame1二维数据
- key2 DataFrame2二维数据
- read_hdf(path, key=)
4.5.3 JSON文件
- pd.read_json(path)
- orient=“records”
- lines=True
- df.to_json
- orient=“records”
- lines=True

接上篇:
因为阿里云上的本课程并未提供代码和课程资料下载,所以我跟随授课老师,手敲了代码,并从github上找到了入门进阶篇用的两个csv文件,为了方便下载,本文所用数据和代码已经上传Github:有需要的同学点击此处下载代码和数据
4.6 高级处理–缺失值处理
- 1)如何进行缺失值处理
- 两种思路:
- 1)删除含有缺失值的样本
- 2)替换/插补
- 4.6.1 如何处理NaN
- 1)判断数据中是否存在NaN
- pd.isnull(df)
- pd.notnull(df)
- 2)删除含有缺失值的样本
- df.dropna(inplace=False)
- 替换/插补
- df.fillna(value, inplace=False)
- 1)判断数据中是否存在NaN
- 两种思路:
- 2)缺失值处理实例
4.6.1 如何处理NaN
判断数据中是否存在NaN:pd.isnull(df)、pd.notnull(df)
处理方式:
- 若存在缺失值NaN,并且是np.nan
- 1 删除存在缺失值:dropna(axis=, inplace=False)
- inplace 默认为False,表示不会修改原数据,需要接受返回值。若设置为True,则修改原数据。
- 2 替换缺失值 fillna(value, inplace=True)
- value:替换为的值
- inplace:
- True:会修改原数据
- False:不替换修改元数据,生成新的对象。
- 1 删除存在缺失值:dropna(axis=, inplace=False)
4.6.2 不是缺失值NaN,有默认标记的。
例如?等标点符号
- 替换?-> np.nan
- df.replace(to_replace="?", value=np.nan)
- 处理np.nan缺失值的步骤
4.6.3 总结
- isnull、notnull判断是否存在缺失值
- dropna删除np.nan标记的缺失值
- fillna填充缺失值
- replace替换具体的某些值
4.7 高级处理-数据离散化
性别 年龄
A 1 23
B 2 30
C 1 18
物种 毛发
A 1
B 2
C 3
理想的分类设定,one-hot编码/哑编码
男 女 年龄
A 1 0 23
B 0 1 30
C 1 0 18
4.7.1 数据离散化
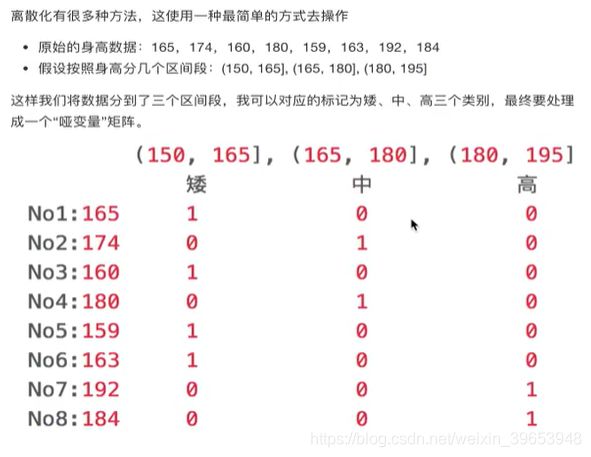
连续属性的离散化就是将连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间的属性值。
4.7.2为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值得个数。离散化方法经常作为数据挖掘的工具。
4.7.3如何实现离散化
- 1)分组
- 自动分组sr = pd.qcut(data, bins)
- data:被分组的数据
- bins:分成几组
- 自定义分组sr = pd.cut(data, [])
- 对数据进行分组将数据分组 一般会与value_counts搭配使用,统计每组的个数
- series.value_counts():统计分组次数
- 自动分组sr = pd.qcut(data, bins)
- 2)将分组好的结果转换成one-hot编码
- pandas.get_dummies(data, prefix=None)
- data:array-like、Series、DataFrame
- prefix:分组名字
- pandas.get_dummies(data, prefix=None)
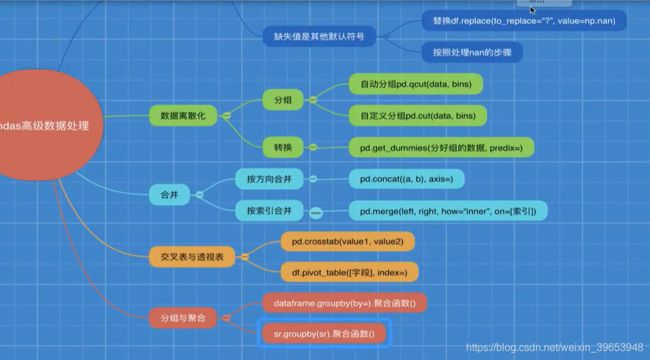
4.8 高级处理–合并
- numpy
- np.concatnate((a,b), axis=)
- 水平拼接
- np.hstack()
- 竖直拼接
- np.vstack()
- 水平拼接
- 1)按方向拼接
- pd.concat([data1, data2], axis=1)
- 2)按索引拼接
- pd.merge实现合并
- pd.merge(left,right,how=“inner”,on=[索引]) #内连接 保存共有字段
- pd.merge(left,right,how=“outer”,on=[索引]) #外连接 所有字段都保存,一方没有的填充为NaN
- np.concatnate((a,b), axis=)
4.9 交叉表与透视表
4.9.1 交叉表与透视表的作用
4.9.2 使用crosstab(交叉表)实现
交叉表:用于计算已列数据对于另外一列数据的分组个数(寻找两个列之间的关系)
- pd.crosstab(value1, value2)
4.9.3 使用pivot_table(透视表)实现
- DataFrame.pivot_table([], index=[])
4.10 高级处理–分组与聚合
4.10.1 什么是分组与聚合?
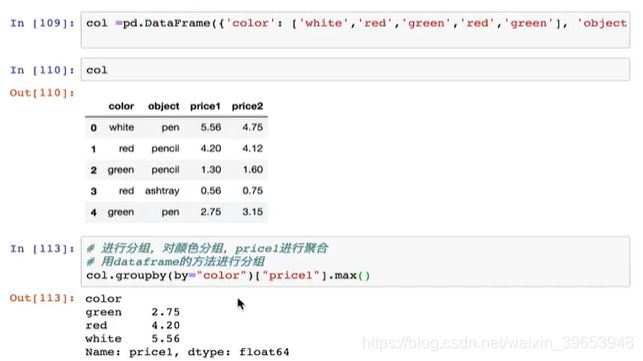
4.10.2 分组与聚合API
- DataFrame
- series
4.10.3 星巴克零售店铺数据案例
代码详见github。有需要的同学点击下载代码和数据
总结