JavaSE学习笔记-Day13
今天好不容易早起,想先整理一下Java写表格的一些方式,也是延续昨天晚上的一些思绪。
就以下面这个表格为例:
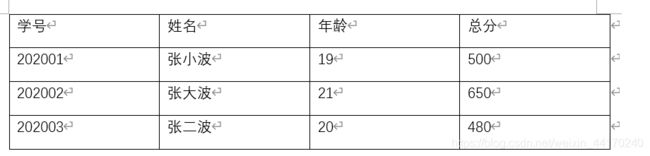
第一种方式: 纯数组实现
package cn.zjb.practice;
import java.util.Arrays;
/**
* 纯数组实现
* @author 张坚波
*
*/
public class Chart1 {
public static void main(String[] args) {
/*先将表格的每一行定义成一个Object[],
*再将每一行放进一个二维数组中。
*/
Object[] student1= {
"202001","张小波",19,500};
Object[] student2= {
"202002","张大波",21,650};
Object[] student3= {
"202003","张二波",20,480};
Object[][] chart1=new Object[3][];
chart1[0]=student1;
chart1[1]=student2;
chart1[2]=student3;
for(int i=0;i<3;i++)
System.out.println(Arrays.toString(chart1[i]));
System.out.println();
//当然,二维数组可以直接静态初始化。
Object[][] chart2={
student1,student2,student3};
for(int i=0;i<3;i++)
System.out.println(Arrays.toString(chart2[i]));
System.out.println();
//还可以直接点,直接上来就定义一个二维数组,放进去。
Object[][] chart3= {
{
"202001","张小波",19,500},{
"202002","张大波",21,650},{
"202003","张二波",20,480}};
for(int i=0;i<3;i++)
System.out.println(Arrays.toString(chart3[i]));
//这三种写法不一样而已,都是二维数组实现
}
}
运行结果如下:
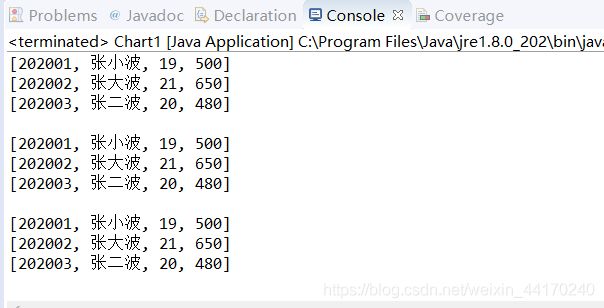
第二种方式:标准类加数组实现
package cn.zjb.practice;
import java.util.Arrays;
/**
* 定义一个标准类来存储表格的一行,
* 最后储存到Object数组里。
* @author 张坚波
*
*/
public class Chart2 {
public static void main(String[] args) {
//若是嫌弃太长了就分开写。
Object[] chart= {
new Student("202001","张小波",19,500),new Student("202002","张大波",21,650),new Student("202003","张二波",20,480)};
System.out.println(Arrays.toString(chart));
}
}
class Student{
//Fields
String sno;
String name;
Integer age;
Integer totalPoints;
//Constructor
public Student(){
}
public Student(String sno, String name, Integer age, Integer totalPoints) {
super();
this.sno = sno;
this.name = name;
this.age = age;
this.totalPoints = totalPoints;
}
//Method
public String getSno() {
return sno;
}
public void setSno(String sno) {
this.sno = sno;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Integer getTotalPoints() {
return totalPoints;
}
public void setTotalPoints(Integer totalPoints) {
this.totalPoints = totalPoints;
}
@Override
public String toString() {
return "学号:"+sno+" " +
"姓名:"+name+" "+
"年龄:"+age+" " +
"总分:"+totalPoints;
}
//代码除了重写toString方法都是自动生成,很方便。
}
运行结果如下:

第三种方式:运用容器实现(实质上和第一种一样)
package cn.zjb.practice;
import java.util.ArrayList;
/**
* 容器中嵌套着容器
* @author 张坚波
*
*/
public class Chart3 {
public static void main(String[] args) {
ArrayList stu1=new ArrayList();
stu1.add("202001");
stu1.add("张小波");
stu1.add(19);
stu1.add(500);
//其他两行也是这样,太长了。。。
ArrayList chart=new ArrayList();
chart.add(stu1);
System.out.println(chart);
}
}
运行结果如下:

为什么突然来这么一出呢,是因为我发现自己还没有从我的惯性思维中走出来。从上大学的第一天起,我就是在基于C语言的环境中成长的,我总是习惯性的把数据和方法完全隔离开看待,也就意味着我的编程思想还是限制在面向过程。到现在我还在想:嗯,不同数据类型的数据要放在一起,好像除了结构体也没有什么实现的了,可Java没有啊,怎么办?诶,有个Object数组,刚好有个包装类,还有多态性,这不正好是个另类的结构体吗!我总是纠结于此。不过这个想法错倒是没错,但是我忽略了一件更重要的事——Java中类就是一种超级强大的“集合”啊,它不光能存储不同类型的数据,更重要的是它还有与之相对应的方法,这是数据+方法的“超强集合”啊!以前总是把数据定义和数据操作分的死死的,现在不是了啊,这个“超强集合”本身就可以直接对内部数据进行操作!所以呢,所以呢,面向对象这个思想还是要再实践中多体会感悟啊。
继续学习吧!
一. LinkedList
java.util.LinkedList底层用双向链表实现的存储。其特点是:查询效率低,增删效率高,线程不安全。
LinkedList在JDK1.7之前的源码: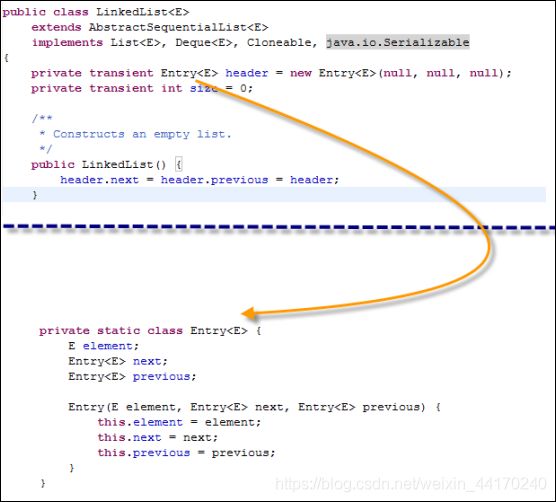
总的来说就是,1.7之前LinkedList底层实现是一个循环双链表,靠头节点header(数据域为空)作为移动指针遍历链表,图示:
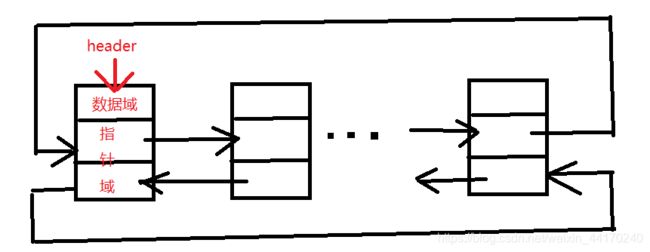
LinkedList从JDK1.7开始的源码:
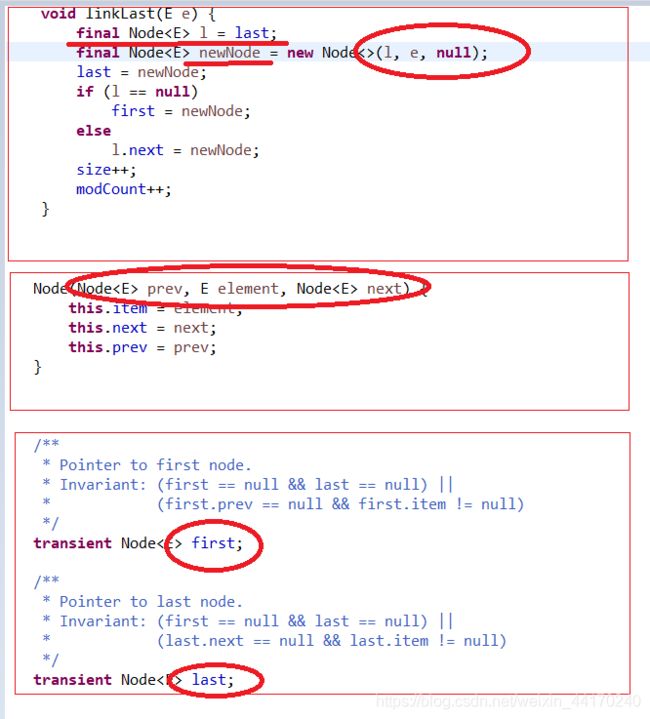
LinkedList的底层实现链表出现改动,变为双链表,删除了header(头节点),直接从首节点开始,并定义了头、尾指针来移动遍历链表。图示:

个人理解:头节点在链表中还是有一定地位的,因为这样我们就不用单独考虑首节点操作的特殊情况了,不知道为什么要改。
LinkedList的构造器:
还是那句话,1.7开始没有头节点,所以是个空链表。
LinkedList新增常用方法:
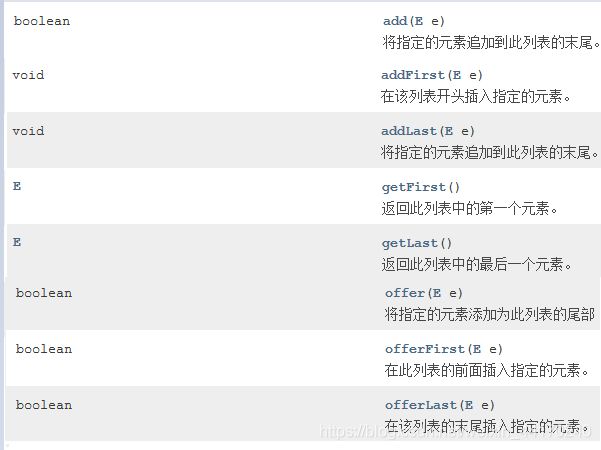
别的无所谓,只要记住默认add()是尾插法。
还是一样,自己来实现一下LinkedList吧:
package cn.zjb.practice;
/**
* MyLinkedList类是用来对数据进行存储和管理的容器类,存储数据的结构为双链表。
* 该类没有实现任何接口,并且是Object的直接子类。
* @author 张坚波
*
*/
public class MyLinkedList <E> {
//Inner
/**
* Node是MyLinkedList的内部类,
* 存储有关节点信息。
*
*/
private static class Node<E>{
/**
* 节点的数据存储域
*/
E element;
/**
* 指向下一节点的指针
*/
Node<E> next;
/**
* 指向上一节点的指针
*/
Node<E> previous;
/**
* Node内部类构造方法,创建一个新节点
* @参数 element:元素值
* @参数 next:指向下个节点
* @参数 previous:指向上个节点
*/
Node(E element,Node<E> next,Node<E> previous) {
this.element=element;
this.next=next;
this.previous=previous;
}
}
//Fields
/**
* 指向第一个节点的指针
*/
private Node<E> first;
/**
* 指向最后一个节点的指针
*/
private Node<E> last;
/**
* 存储当前列表的节点个数
*/
private int count;
//Constructor
/**
* 创建一个空链表
*/
public MyLinkedList(){
}
//Method
/**
* 求容器的大小
*/
public int size() {
return count;
}
/**
* 利用尾插法加入元素
* @参数 e表示元素
*/
public void add(E e) {
Node<E> newNode=new Node<>(e,null,last);
if(count==0)
first=newNode;
else {
last.next=newNode;
newNode.previous=last;
}
last=newNode;
count++;
}
/**
* 利用头插法加入元素
* @参数 e表示元素
*
*/
public void addFirst(E e) {
Node<E> newNode=new Node<>(e,first,null);
first.previous=newNode;
first=newNode;
count++;
}
/**
* 与方法add(...)一致。
*/
public void addLast(E e) {
add(e);
}
/**
* 从头开始遍历链表,找出相应元素。
* @参数 e元素。
* @返回值 从头开始的索引值。
*/
public int searchFromHead(E e){
Node<E> temp=first;
int counter=0;
if(temp==null)
return -1;
while(temp!=null) {
if(temp.element.equals(e))
return counter;
else {
counter++;
temp=temp.next;
}
}
return -1;
}
/**
* 从最后一个节点开始遍历链表,找出相应元素
* @参数 e元素。
* @返回值 从尾开始算的索引值。
*/
public int searchFromTail(E e) {
Node<E> temp=last;
int counter=0;
if(temp==null)
return -1;
while(temp!=null) {
if(temp.element.equals(e))
return counter;
else {
counter++;
temp=temp.previous;
}
}
return -1;
}
/**
* 找出相关元素的索引值,
* 若该元素不存在则返回-1。
*/
public int indexOf(E e) {
return searchFromHead(e);
}
/**
* 按区查找
* @参数 index
* @返回值 节点指针
*/
private Node<E> bestSearch(int index){
if(index<count&&index>=0) {
Node<E> temp=null;
if(index<=(count>>1)) {
temp=first;
for(int i=0;i<index;i++) {
temp=temp.next;
}
}else {
temp=last;
for(int i=count-1;i>index;i--) {
temp=temp.previous;
}
}
return temp;
}else {
throw new RuntimeException("输入的索引值异常");
}
}
/**
* 输出相应索引的值
* @参数 index:从头开始的索引值
* @返回值 E对象
*/
public E get(int index) {
if(index<count&&index>=0)
return bestSearch(index).element;
else
throw new RuntimeException("输入的索引值异常");
}
/**
* 在指定索引处放入一个值
*/
public void set(int index,E e) {
if(index<count&&index>0) {
Node<E> temp=bestSearch(index);
Node<E> newNode=new Node<>(e,temp,temp.previous);
if(temp.previous==null)
System.out.println(temp.element);
temp.previous.next=newNode;
temp.next.previous=newNode;
}else if(index==count) {
add(e);
}else if(index==0) {
addFirst(e);
}else
throw new RuntimeException("输入的索引值异常");
}
/**
* 删除指定索引处的元素
*/
public void remove(int index) {
if(index==0) {
first=first.next;
}else {
Node<E> temp=bestSearch(index);
temp.previous.next=temp.next;
temp.next.previous=temp.previous;
temp.next=null;
temp.previous=null; //这两行没有必要
}
}
/**
* 重写toString()方法
*/
@Override
public String toString() {
Node<E> temp=first;
if(temp==null)
return "[]";
StringBuilder sb=new StringBuilder();
sb.append('[');
while(temp!=null) {
sb.append(temp.element+",");
temp=temp.next;
}
sb.setCharAt(sb.length()-1, ']');
return sb.toString();
}
}
package cn.zjb.practice;
/**
* practice包中主方法所在的类
* @author 张坚波
*
*/
public class MainClass {
public static void main(String[] args) {
MyLinkedList<String> a=new MyLinkedList<>();
for(int i=0;i<5;i++)
a.add("zhang"+i);
System.out.println(a); //[zhang0,zhang1,zhang2,zhang3,zhang4]
a.addFirst("zhang");
System.out.println(a); //[zhang,zhang0,zhang1,zhang2,zhang3,zhang4]
System.out.println(a.get(4)); //zhang3
System.out.println(a.indexOf("zhang2")); //3
a.set(1, "zhang5");
System.out.println(a); //[zhang,zhang5,zhang0,zhang1,zhang2,zhang3,zhang4]
a.remove(0);
System.out.println(a); //[zhang5,zhang0,zhang1,zhang2,zhang3,zhang4]
}
}
可能还有错误,JDK1.7后删除了头节点,使得在编写无头节点链表代码的时候没有办法将所有情况一视同仁了。
二. Vector
Vector底层是用数组实现的List,相关的方法都加了同步检查(synchronized同步标记),因此“线程安全,效率低”。所以没啥好学的。
如何选用ArrayList、LinkedList、Vector?
- 需要线程安全时,用Vector。
- 不存在线程安全问题时,并且查找较多用ArrayList(一般使用它)。
- 不存在线程安全问题时,增加或删除元素较多用LinkedList。