哈希表的应用和哈希冲突解决方案分析
哈希
一般指哈希算法。英文Hash,一般翻译做"散列",也有直接音译为"哈希"的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
所以哈希算法一般情况下有两个重要特质:就是不可逆和无冲突。
所谓不可逆,就是当你知道x的HASH值,无法求出x;一般的哈希算法k=h(x),可以同时存在两个或多个值,经过哈希算法后所得的摘要值(结果)可能是一样的。因此当知道哈希值,是无法可逆的推算出原始值是哪个。
所谓无冲突,就是当两个HASH值不相同时,那么他们原始的值也必然不会相同。即如果h(x)≠h(y),那么x≠y。
在数学上,一个函数必然可逆,且由于HASH函数的值域有限,理论上会有无穷多个不同的原始值,它们的hash值都相同。例如常见的MD5和SHA算法。也就是也就是正向计算很容易,而反向计算则需要耗费大量的资源。使得算法的可逆求值变得几乎不可能。然而,在目前已知的情况下,人们还是可以采用各种手段去可逆求值,比如最常见也是比较有效的就有碰撞法,比如MD5的碰撞,当md5(a)=md5(b)=md5(c)...=md5(n)时,根据经验算法等还是可以大致的得到原始值。
常见哈希算法
1、MD5
MD5 即 Message-Digest Algorithm 5(信息-摘要算法5),常见的用于确保信息传输完整一致。是计算机广泛使用的杂凑算法之一。MD5将不定长度的数据(如汉字)运算为另一固定长度值,即128位字节,然后显示成32位长度的字符串。MD5算法基本方式为,求余、取余、调整长度、与链接变量进行循环运算,得出结果。
2. SHA-1
SHA-1(英语:Secure Hash Algorithm 1,中文名:安全散列算法1)是一种密码散列函数,SHA-1可以生成一个被称为消息摘要的160位(20字节)散列值,散列值通常的呈现形式为40个十六进制数。
哈希表
哈希表也称散列表,是哈希算法的一个主要应用。是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。比如java中常见的hashmap。使用散列表能够快速的按照关键字查找数据记录(注意:这里的关键字不一定是在加密中所生成的结果值,但它们都是用来"解锁"或者访问数据的)。
在日常开发中,可能大多数的程序员不会关注到哈希表的哈希值。
因为我们所说的哈希表可以对数据进行快速访问的情景,只有在数据量级比较大的时候才会受到重视。一般的当我们需要处理的数据量级非常大时,哈希寻址的优势才被放大。就像我们再计算100以内的加减乘除时,一般的我们口算速度可能大于用计算机计算的整个过程(手工输入值+计算机计算),但是当要计算的数很大时,如26543*98468时,我们是很难超过用计算机计算的。其中手工输入的耗时,其实有点类似哈希算法的耗时,这也就是为什么当数据量级很小时,利用哈希算法存储和寻址的优势无法显现的原因,因为当数据量级很小时,即便是采用完全遍历法,其耗时也是很快的。
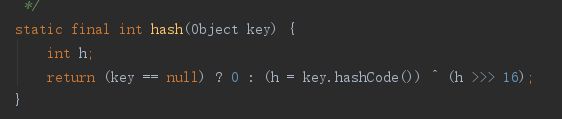
要想理解哈希表的应用,尤其是对于其能够快速寻址的方法,可能我们需要深入底层,弄清本质是什么才好理解。一般的我们希望哈希算法能够在查找数据时的时间复杂度是O(1),或者O(i),假设数据长度为n,i不大于n,越小越好。那么如何实现这样的理想情况呢?这就需要我们在存储数据时,根据数据的“关键字”进行一种哈希运算,而运算的结果可以和存储的链表索引直接关联,甚至直接作为链表的索引,那么在访问数据时,我们就可以通过A[h(x)]的方式直接寻址到存储的数据,如果数据对比正确,就是我们需要的内容。
生活中一个经典的例子就是我们的身份证号的使用。
18位身份证号码各位的含义:
1-2位省、自治区、直辖市代码; 如湖北省|42
3-4位地级市、盟、自治州代码;
5-6位县、县级市、区代码;
7-14位出生年月日,比如19950822代表1995年8月22日;
15-17位为顺序号,其中17位男为单数,女为双数;
18位为校验码,根据前面十七位数字码,按照ISO 7064:1983.MOD 11-2校验码计算出来的检验码。如果计算结果是10,就用X表示。
显然在中国14亿的人中找到具体的一个人是何种不容易。而身份证号赋予了我们唯一的身份标识,如果通过身份证号找一个人,效率就得到了很大的提升,所以身份证号也可以看作是生活中一种实际的经过哈希运算后的关键字。
从上面例子中可以看出哈希运算函数包括很多种。一般我们在实际应用中自己来实现某种哈希运算时,常用的方式可以有:.直接定址法、数字分析法、平方取中法、折叠法、除留余数法和随机函数法等。
直接定址法:取关键字的线性函数值作为哈希地址。
数字分析法:取关键字的中的若干位作为哈希地址。
平方取中法:取关键字平方后的中间几位作为哈希地址。
折叠法:将关键字分割成位数相同的几部分(最后一部分可以不同),然后取这几部分的叠加和作为哈希地址。
除留余数法:也叫取模,H(key) = key MOD p ,p<=m ,m为不大于哈希表的数。
哈希冲突
数据在存储时利用哈希表的形式,并且将数据的索引和关键字key进行某种函数运算关联,从而在通过关键字访问数据时,可以直接寻址获取数据。然而在实际情况中,由于数据量级大,存储成本高,且存储空间是有限的,所以我们常见的互联网公司在应对并发时的方案通常是限流、削峰、缓存、预加载等。哈希冲突常见于解决分布式系统计算、利用缓存等手段来应对高并发。因此散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,这样就出现了哈希冲突。也就是说由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,因此总会存在不同的数据经过计算后得到的值相同,这就是哈希冲突。
举个例子。生活中常见的停车场,假设停车场容量为10000个车位(定义的存储链表长度为10000),编号为0-9999(对应链表的索引值key)。有一天,你去商场购物,将车停在了停车场,假设车不是你亲自停的,而为你停车的人也没告诉你车停在哪,你也找不到那个人,那当你购物后来停车场找车就麻烦大了。想一想,这时你会怎么找车,通常情况下我们可能会从0号车位找起,按照顺序号找下去,直到找到自己的车(计算机中链表的遍历查找法)。如果运气好,可能前几辆就是你的车,如果运气很差,可能最后一个才找到你自己的车,这时你手里还拎着重重的东西,很着急的想回家,不难想象你的心情会是多么美妙。同样的,互联网应用中,如果你在找自己的信息时,或者购物时,你等了很久还没找到自己想要的信息,那你的心情肯定也是很不美妙。既然存在这样的问题,那该怎么解决呢?
首先我们去停车的时候,停车场根据你的车牌号除以10000取模作为你的车停放的编号位(链表中的索引值),假设你的车牌后四位为0273,那么你的车就停放在273号,当你来取车时,你就可以直接到273号找到你的车了。这样一来皆大欢喜。但是实际情况中还有可能别人的车牌号后四位和你的一样,如果别人的车已经占了273号,那你怎么办呢?此时停车场会采取其他手段来保证你能顺利停车,还可以快速的找到你的车。1、假设274号或者272号是空位,你可以将车停在274号位或者272号位,如果不是空号位,继续向下寻找,直到找到空车位(哈希中对应线性探测方法);2、停车场使用另一种计算车牌的方法,将你的车位算成736位,如果736位没有车,你可以停,如果有车,那就再使用一种算法,将车牌号计算成车位,直到找到空车位(哈希中对应再哈希法);3、停车场在273号位上搭建的有立体车库,你可以停在上面空的一层(链地址法,也叫拉链法或开链法);;4、停车场还准备了一个额外的停车场,你可以将车停在另一个停车场(哈希中指建立公共溢出区)。所以停车场仍然是可以有其他方法来解决的,而不会束手无策。
哈希冲突解决方案
上面的例子结合开发中使用到的情况进行了类比。开发中,常见的哈希冲突解决方案也是基于以上例子。我们暂且可以将其分为两大类:开放寻址法(open addressing)和链表法(chaining)
1、开放寻址法
定义:将散列函数扩展定义成探查序列,即每个关键字有一个探查序列h0(k)、h1(k)、…、h(m-1)(k),这个探查序列一定是0….m-1的一个排列(一定要包含散列表全部的下标,不然可能会发生虽然散列表没满,但是元素不能插入的情况),如果给定一个关键字k,首先会看h0(k)是否为空,如果为空,则插入;如果不为空,则看h1(k)是否为空,以此类推。
开放寻址法是一种解决碰撞的方法,对于开放寻址冲突解决方法,比较经典的有线性探测方法(Linear Probing)、平方探查法(Quadratic probing)和 双重散列(Double hashing)等方法。
线性探测方法:当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次向前或往后查找,看是否有空闲位置,直到找到为止。
这种方式有一种弊端,当存储空间内容越来越小时,数据越难以插入,因为经过散列函数散列后的位置更容易被占用,且其相邻位置也极有可能被占用,这样最差的情况下,可能导致查询时间复杂度为O(n)。
平方探查法:当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次向前或往后查找步长的平方数位,知道找到空闲位置为止。
在实际操作中,平方探查法不能探查到全部剩余的单元格。不过在实际应用中,能探查到一半单元也就可以了。若探查到一半单元仍找不到一个空闲单元,表明此散列表太满,应该重新建立。
双重散列:意思就是不仅要使用一个散列函数,而是使用一组散列函数h0(k)、h1(k)、…、h(m-1)(k)。先用第一个散列函数,如果计算得到的存储位置已经被占用,再用第二个散列函数,依次类推,直到找到空闲的存储位置。
双重散列法也有可能会出现和线性探测方法同样的问题。导致查询的时间复杂度增加。
事实上,不管采用哪种探测方法,只要当散列表中空闲位置不多的时候,散列冲突的概率就会大大提高。为了尽可能保证散列表的操作效率,一般情况下,需要尽可能保证散列表中有一定比例的空闲槽位。一般使用加载因子α(load factor)来表示空位的多少。加载因子是表示 Hsah 表中元素的填满的程度,若加载因子越大,则填满的元素越多,表明空间的利用率高,但冲突的机会也会加大。反之,加载因子越小,填满的元素越少,冲突的机会减小了,但空间浪费多了。一般情况下当加载因子达到一定比例后,也就意味着我们的空间不足了,需要额外编程,创建一个溢出表。
2、链表法
定义:也叫拉链法或开链法。思路是将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第i个单元中,查找、插入和删除主要在同义词链表中进行。链表法适用于经常进行插入和删除的情况。
如下一组数字,(31、43、37、54、16、48、71、25、46、28、49、67)哈希表长度为10,哈希函数为H(key)=key%10,则链表法结果如下:
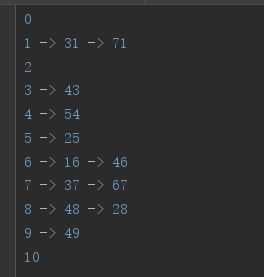
在java中,链接地址法也是HashMap解决哈希冲突的方法之一。
链表法相对于开放寻址法有如下几个优点:
1、拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
2、由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
3、开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
4、在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放定址法构造的散列表,删除结点不能简单地将被删结 点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放定址法中,空地址单元(即开放定址)都是查找失败的条件。因此在用开放定址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
拉链法的缺点是:指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间。将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
参考:
1、百科 哈希算法
2、https://blog.csdn.net/zhangvalue/article/details/83784716
3、https://blog.csdn.net/qingxindai/article/details/88994224