Orcal 数据库
目录
一、数据库
1. 数据库概念
2. SQL 语言
3. Oracle结构
4. 表(Table)
5. 三范式
6. SELECT 语句
二、Orcal 基本操作
1. 查询列(字段)
2. 查询行(记录)
2.1 比较条件
2.2 且或非
2.3 null:
2.4 集合操作
2.5 模糊匹配:like
2.6 in与exists
2.7 获取所有行的记录
3. 排序
4. 单行函数
4.1 日期函数
4.2 转换函数
4.3 其他函数 (保证类型兼容)
5. 聚合函数
5.1 count 计数
5.2 sum 求和
5.3 max min:最大值 最小值
5.4 avg:取平均数
6. 分组函数
6.1 组成
6.2 现 select 语句结构
6.3 执行顺序
6.4 示范
7. 行转列
8. 连表查询
8.1 rowid
8.2 rownum
8.3 表连接(92)
8.4 表连接(99)
一、数据库
1. 数据库概念
数据库管理系统 (Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称 DBMS。
当前主流的关系型数据库有 Oracle、DB2、Microsoft SQL Server、MicrosoftAccess、MySQL 等。
2. SQL 语言
SQL(Structured Query Language)为数据库的语言,它包含三部分:
DDL:数据定义语言
create:创建;drop:删除;alter:修改;rename:重命名;truncate:截断DML:数据管理语言
insert:插入;delete:删除;update:更新;select:查询DCL:数据库控制语言
grant:授权;revoke:回收权利;commit:提交事务;rollback:回滚事务
3. Oracle结构
完整的Oracle数据库通常由两部分组成:Oracle数据库和数据库实例。
(1)创建流程
Oracle(数据库管理系统)---> xe(实例/数据库) |表空间 (多个)---> 用户(多个) ---> 表(多张)
(2)常用命令
1)创建表空间:
create tablespace 表空间名称
DataFile 表空间数据文件路径\名字.dbf’
Size 表空间初始大小
Autoextend on

2)创建新用户
CREATE USER 用户名 (scott)
IDENTIFIED BY 密码 (tiger)
DEFAULT TABLESPACE 表空间(默认USERS)
TEMPORARY TABLESPACE 临时表空间(默认TEMP)
3)解锁账户
alter user scott account unlock;
4)授权
GRANT <权限列表> to
;
4. 表(Table)
(1)介绍
表是从属于用户的 ,查询表(用户名.表名),当前用户查询自己的表时,用户名.可以省略,其他用户查询 别的用户表 ,不能省略,同时必须存在权限。
(2)表结构
表由表名、字段(名称+类型+约束)、记录 组成。
与 java 相对应:
| DB | JAVA |
|---|---|
| 表名 | 属性名 |
| 字段名 | 属性名 |
| 字段类型:
|
属性类型
|
| 字段约束:约制行为 --> 创建表结构加入, 操作数据 才生效
|
方法检查条件 |
| 记录:数据 | 对象:new |
5. 三范式
(1)概念
在设计数据库时,存在行业的标准,这个标准也称为条件,即范式 NormalForm。一般遵循三个条件即可,也就是”三范式”(3NF)。
(2)分类
1 NF:是指数据库表的 每一列都是不可分割的基本数据项
2 NF:必须先满足第一范式(1NF)。第二范式就是非主属性非部分依赖于主键。
3 NF:必须先满足第二范式(2NF)。3NF 要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。即第三范式就是属性不依赖于其它非主属性。
(3)区别进程
1NF:列不可再分,最小原子 (避免重复) ---> 2NF:主键依赖 (确定唯一) ---> 3NF:消除传递依赖(建立主外键关联 拆分表)
6. SELECT 语句
注意:命令不区分大小写
(1)查询列(字段)
- select distinct *|字段|表达式 as 别名 from 表 表别名
- SELECT * FROM 表名; ---> 查询某个表中所有的记录的所有字段信息
- SELECT 列名 FROM 表名; ---> 查询某个表中所有的记录的指定字段信息
- SELECT 列名1,列名2 FROM 表名; ---> 查询某个表中所有的记录的字段1 字段2
- SELECT distinct 列名 FROM 表名; ---> 去除重复记录
- SELECT 表达式 FROM 表名; ---> 查询表达式
- SELECT xxx as 别名 FROM 表名 表别名 ---> 使用别名
1) 部分列
查询部分字段,指定的字段名:
--1) 、检索单个列
select ename from emp; -- 查询雇员姓名
--2) 、检索多个列
select deptno,dname,loc from dept; -- 查询部门表的 deptno,dname, loc 字段
的数据。
-- 以下查询的数据顺序不同 ( 查询的字段顺序代表数据顺序 )
select loc,dname,deptno from dept;
select deptno,dname,loc from dept;2)所有列
查询所有的字段 通配符 *( 书写方便、可以检索未知列;但是降低检索的性能 ) ,数据的顺序跟定义表结构的顺序一致:
--1) 、检索所有列 1
select * from dept; -- 查询部门的所有信息
--2) 、检索所有列 2
select deptno,dname,loc from dept; -- 查询部门的所有信息3)去处重复
使用distinct去重,确保查询结果的唯一性 :
select distinct deptno from emp; -- 去重4)别名
使用别名便于操作识别 、隐藏底层信息。存在字段别名和表别名:
select ename as "雇员 姓名" from emp;
select ename "雇员姓名" from emp;
select ename 雇员姓名 from emp;
select ename as 雇员姓名 from emp;
select ename as " Ename" from emp;注意:
as:字段别名可以使用as;表别名不能使用as
"":原样输出,可以存在 空格与区分大小写
5)字符串
使用’’表示字符串( 注意区分”” ) ,拼接使用 ||
select 'my' from emp;
select ename||'a'||'-->' info from emp;6)伪列
不存在的列,构建虚拟的列
select empno, 1*2 as count,'cmj' as name,deptno from emp;7)虚表
用于计算表达式,显示单条记录的值
select 1+1 from dual;8)null
null 遇到数字参与运算的结果为 null,遇到字符串为空串
select 1+null from dual;
select '1'||null from dual;
select 1||'2'||to_char(null) from dual;
select ename,sal*12+comm from emp;
--nvl 内置函数,判断是否为 null, 如果为空,取默认值 0 ,否则取字段实际值
select ename,sal*12+nvl(comm,0) from emp;
二、Orcal 基本操作
1. 查询列(字段)
上一篇已做详细陈述,此处不再说明。
2. 查询行(记录)
where 过滤行记录条件,条件有
a)、= 、 >、 <、 >=、 <=、 !=、 <>、 between and
b)、and 、or、 not、 union、 union all、 intersect 、minus
c)、null :is null、 is not null、 not is null
d)、like :模糊查询 % _ escape('单个字符')
f)、in 、 exists(难点) 及子查询
2.1 比较条件
= 、>、 <、 >=、 <=、 !=、 <>、between and
-- 比较条件 = != <> 可以比较数字也可以比较字符串 > < 适合用在数字
-- 查询20部门所有员工的信息
-- 数据:员工信息 *
-- 来源: emp
-- 条件: 20部门 deptno=20
select * from emp where deptno = 20;
-- 查询 SMITH 的信息
-- 数据: *
-- 来源:emp
-- 条件:ename ='SMITH'
select * from emp where ename='SMITH';
-- 查询工资为800的员工信息
select * from emp where sal=800;
-- 查询除了'SMITH'之外的所有人信息
select * from emp where ename != 'SMITH';
select * from emp where ename <> 'SMITH';
-- 查询工资大于1500的员工的 工种和姓名
select job,ename,sal from emp where sal >= 1500;
-- 查询工资在1500~2500之间的员工工种和姓名和工资
select job, ename, sal from emp where sal between 1500 and 2450;
-- 执行顺序|过程
-- from
-- where
-- select2.2 且或非
and、or、not
-- 查询工资在1500~2500之间的员工工种和姓名和工资
select job, ename, sal from emp where sal>=1500 and sal<=2500;
--查询 岗位 为 CLERK 且部门编号为 20的员工名称 部门编号,工资,工种
select ename,deptno, sal, job from emp where job='CLERK' and deptno=20;
--查询 岗位 为 CLERK 或部门编号为 20的员工名称 部门编号,工资,工种
select ename,deptno, sal, job from emp where job='CLERK' or deptno=20;
--查询 岗位 不是 CLERK 员工名称 部门编号,工资
select ename, deptno, sal, job from emp where job!='CLERK';
select ename, deptno, sal, job from emp where not job='CLERK';
--查询 岗位 不是 CLERK 并且也不在20部门的 员工名称 部门编号,工资
select ename, deptno, sal , job from emp where job!='CLERK' and deptno!=20;
select ename, deptno, sal , job from emp where not ( job='CLERK' or deptno=20);
select ename, deptno, sal , job from emp where not job='CLERK' and not deptno=20;2.3 null:
is null、 is not null、 not is null
-- 查询所有可以领奖金的员工信息
select * from emp where comm is not null;
select * from emp where not comm is null;
-- 查询所有不可以领奖金的员工信息
select * from emp where comm is null;
--查询工资大于1500 或 含有佣金的人员姓名
select ename, sal , comm from emp where sal>1500 or comm is not null;2.4 集合操作
Union、Union All、Intersect、Minus
- Union:并集(去重) 对两个结果集进行并集操作,不包括重复行同时进行默认规则的排序;
- Union All:全集(不去重) 对两个结果集进行并集操作,包括重复行,不进行排序 ;
- Intersect:交集(找出重复) 对两个结果集进行交集操作,不包括重复行,同时进行默认规则的排序;
- Minus:差集( 减去重复 ) 对两个结果集进行差操作,不包括重复行,同时进行默认规则的排序。
-- 利用集合操作实现
-- 先找出满足任意一方的集合 求并集
-- 工资大于1500
select ename, sal, comm from emp where sal>1500;
-- 含有佣金
select ename,sal, comm from emp where comm is not null;
select ename, sal, comm from emp where sal>1500
union
select ename,sal, comm from emp where comm is not null;
select ename, sal, comm from emp where sal>1500
union all
select ename,sal, comm from emp where comm is not null;
-- 查询所有存在员工的部门编号
select distinct deptno from emp;
--查询显示不存在雇员的所有部门号
select deptno from dept
minus
select distinct deptno from emp;
--查询工资大于1500 且 含有佣金的人员姓名
select * from emp where sal > 1500
intersect
select * from emp where comm is not null;2.5 模糊匹配:like
模糊查询,使用通配符
- %:零个及以上(任意个数的)的字符
- _:一个字符
- 遇到内容中包含 % _ 使用escape('单个字符')指定转义符
-- 查询姓名以‘A’开头的员工信息
select * from emp where ename like 'A%';
-- 查询姓名里边有‘A’的员工信息
select * from emp where ename like '%A%';
-- 查询名称中第二个字母为‘A’的员工信息
select * from emp where ename like '_A%';
-- 查询名称以'H'结尾的员工信息
select * from emp where ename like '%H';
select * from emp;
--插入
insert into emp(empno,ename,sal) values(1000,'t_%test',8989);
insert into emp(empno,ename,sal) values(1200,'t_tes%t',8000);
--回滚
rollback;
--提交
commit;
--查询姓名中含有%的员工信息
select * from emp where ename like '%A%%' escape('A');2.6 in与exists
- in相当于使用or的多个等值,定值集合 ,如果存在 子查询,确保 类型相同、字段数为1,如果记录多,效率不高,用于 一些 少量定值判断上;
- exists条件为true,存在记录则返回结果,后续不再继续 比较查询,与查询的字段无关,与记录有关。
-- 查询工资为i 1500, 2000, 2500, 5000的员工的信息
select * from emp where sal = 1500 or sal = 2000 or sal =2500 or sal = 5000;
-- 当我们查询的条件为若干个定值的时候我们可以使用in
select * from emp where sal in (1500,2000,2500,5000);
--部门名称为 SALES 或 ACCOUNTING 的雇员信息
-- 数据: 雇员信息
-- 来源:emp
-- 条件: 部门名称为 SALES 或 ACCOUNTING
-- 提取中间结果
-- 查询SALES 或 ACCOUNTING的部门编号
select deptno from dept where dname='SALES' or dname ='ACCOUNTING';
select deptno from dept where dname in ('SALES','ACCOUNTING' );
-- 查询10 部门和30部门的员工信息
select * from emp where deptno =10 or deptno=30;
select * from emp where deptno in(10,30);
select *
from emp
where deptno in (select deptno
from dept
where dname = 'SALES'
or dname = 'ACCOUNTING');
--部门名称为 SALES 的雇员信息
-- 查询需要的部门编号
select deptno from dept where dname in( 'ACCOUNTING','SALES' );
select *
from emp
where deptno in
(select deptno from dept where dname in ('ACCOUNTING', 'SALES'));
-- 使用exists查询'SALES'或者'ACCOUNTING'部门的员工信息
select *
from emp
where deptno in (select deptno from dept where dname = 'SALES');
select *
from emp e
where exists (select *
from dept d
where dname in ('SALES', 'ACCOUNTING')
and e.deptno = d.deptno);
--此处的not相当于取反,使用exists查询不属于'SALES'或者'ACCOUNTING'部门的员工信息
select *
from emp e
where not exists (select deptno, dname
from dept d
where dname in ('SALES', 'ACCOUNTING')
and e.deptno = d.deptno);
-- 查询有可以领奖金的部门的所有员工信息
-- 数据:empno, ename,sal
-- 来源: emp
-- 条件:奖金不为null
select empno, ename, sal,comm
from emp e1
where exists (select *
from emp e2
where comm is not null
and e1.empno = e2.empno);2.7 获取所有行的记录
- select * from emp;
- select * from emp where 1=1 ;
- select * from emp where ename like '%';
3. 排序
使用 order by 排序,排序不是真实改变存储结构的顺序,而是获取的集合的顺序。
- 顺序:升序 asc(默认) 降序 desc
- 多字段:在前面字段相等时,使用后面的字段排序
- 空排序:null 在升序时默认放在后面,降序时放在前面,可以通过 first 和 last 设置 null 的在表中排序的位置
-- select 数据 from 数据源 where 条件 order by 排序字段
-- 查询30部门的员工信息, 并且按工资降序排序
select * from emp where deptno=30 order by sal desc;
-- 查询30部门的员工信息, 并且按工资降序排序如果工资相同,则按照员工编号降序排序
select * from emp where deptno = 30 order by sal asc,empno desc;
--null在升序时默认放在后面,降序时放在前面
-- 查询所有员工信息, 按照奖金升序排序 null在前面
select * from emp order by comm nulls first;
-- select 字段|表达式 别名 from 表名|结果集 where 行记录条件 order by 排序字段 asc|desc;
-- from -> where ->select -> order4. 单行函数
单行函数:一条记录返回一个结果。
4.1 日期函数
日期函数:注意区分 db 数据库时间与 java 应用服务器的时间,以一方为准。oracle以内部数字格式存储日期:年,月,日,小时,分钟,秒。
- sysdate/current_date:以date类型返回当前的日期
- add_months(d,x):返回加上x月后的日期d的值
- last_day(d):返回的所在月份的最后一天
- months_between(date1,date2):返回date1和date2之间月的数目
- next_day(sysdate,'星期一'):下周星期一
(1)当前时间
-- 当前时间
select sysdate from dual ;
select current_date from dual;(2)修改日期(天数加减)
-- 2天以后是几号
select sysdate+2 from dual;
-- 所有员工入职的3天后是几号
select ename, hiredate,hiredate-3 from emp;
-- 查询所有员工的试用期期到期(转正的日期) 3个月试用期
select ename, hiredate,hiredate+30*3 转正日期 from emp;(3)修改月份
-- 当前 5 个月后的时间
select add_months(sysdate,5) from dual;
-- 查询所有员工的试用期期到期(转正的日期) 3个月试用期
select ename, hiredate,add_months(hiredate,3) 转正日期 from emp;
(4)月份之差
-- 查询所有员工到目前为止一共工作了几个月
select months_between(sysdate,hiredate) 工作的月份, hiredate, sysdate from emp;(5)最后一天
-- 查询当前月的最后一天
select last_day(hiredate) from emp;
-- 利用伪列
select last_day(sysdate) from dual;(6)下一个星期的时间
-- 下一周星期三是几号
select next_day(sysdate,'星期四') from dual;4.2 转换函数
(1)to_date(c,m) :字符串以指定格式转换为日期。
-- 设定一个特定的时间(用一个特定的时间字符串转换为日期)
-- 设定一个时间 就是今天 '2018-9-5 16:18:25'
select to_date('2018/9/5 16:18:25','yyyy/mm/dd hh24:mi:ss')+2 时间 from dual;
select to_date('2018年9月5日 16:18:25','yyyy"年"mm"月"dd"日" hh24:mi:ss')+2 时间 from dual;(2)to_char(d,m) :日期以指定格式转换为字符串。
-- 将日期转为特定格式的字符串 to_cahr
select to_char(sysdate,'yyyy"年"mm"月"dd"日" hh24:mi:ss') 时间 from dual;
(3)注意中文的问题:
中文格式需要使用双引号括起来。
4.3 其他函数 (保证类型兼容)
(1)nvl nvl (string1,string2)
如果string1为null,则结果为string2的值。
-- 查询 82 的员工信息
select * from emp where to_char(hiredate,'yyyy')='1982';
select *
from emp
where hiredate between to_date('1982-01-01', 'yyyy-mm-dd') andto_date('1982-12-31', 'yyyy-mm-dd');
(2)判断 decode (判定字段,校验字段值1,结果1,校验字段2,结果2。。)
decode decode(condition,case1,express1,case2 , express2,….casen , expressn, expressionm)
-- 10部门涨薪10%, 20涨薪20%,30降薪1% , 40部门翻倍3倍
--方法一:使用 decode
select ename,
deptno,
sal,
decode(deptno,
10,
sal * 1.1,
20,
sal * 1.2,
30,
sal * 0.99,
40,
sal * 3) 新工资
from emp;(3)case when then else end
-- 10部门涨薪10%, 20涨薪20%,30降薪1% , 40部门翻倍3倍
--方法二:使用 case when then else end
select ename,
deptno,
sal,
(case deptno
when 10 then
sal * 1.1
when 20 then
sal * 1.2
when 30 then
sal * 0.99
when 40 then
sal * 3
else
sal
end) 新工资
from emp;5. 聚合函数
即多条记录 返回一个结果。
- count:统计记录数 count ( ) --> * 或一个列名
- max min:最大值 最小值
- sum:求和
- avg:平均值
注意
- 组信息与单条记录不能同时查询。
- 组函数不能用在 where 中,能使用的地方 select having 。
- null 不参与运算。
5.1 count 计数
(1)count 统计所有的员工数,推荐使用第三种
--1) 、 *
select count(*) from emp;
--2) 、主键
select count(empno) from emp;
--3) 、使用数字 1 创建伪列
select count(1) from emp where 1=1;(2)null 不参与运算
-- 存在佣金的员工数
-- 不推荐 / 不需要
select count(comm) from emp where comm is not null;
-- 推荐
select count(comm) from emp;5.2 sum 求和
-- 计算本公司每个月一共要在工资上花费多少钱
select sum(sal) from emp;
-- 计算20部门每个月的工资花销
select sum(sal) from emp where deptno=20;5.3 max min:最大值 最小值
-- 查询本公司的最高工资和最低工资
select max(sal) from emp;
select min(sal) from emp;
select max(sal) 最高工资, min(sal) 最低工资 from emp;
select max(sal) , min(sal) from emp where deptno=30;
--查询 最高薪水的员工姓名, 及薪水
select ename, max(sal) from emp;
-- 数据: ename, sal
-- 来源: emp
-- 条件:sal = 最高薪水值
select max(sal) from emp;
select ename, sal from emp where sal = (select max(sal) from emp);5.4 avg:取平均数
-- avg 平均工资
select avg(sal) from emp;
-- 请查询出 20部门的平均工资, 部门编号
select max(sal), avg(sal),min(sal) from emp where deptno=20;
-- 查询工资低于平均工资的员工编号,姓名及工资
-- 数据:empno , ename, sal
-- 来源:emp
-- 条件: sal<平均工资的值 (select avg(sal) from emp)
select empno , ename, sal from emp where sal<(select avg(sal) from emp);
--查看 高于本部门平均薪水员工姓名
select ename from emp e1 where sal>(select avg(sal) from emp e2 where e2.deptno=e1.deptno)6. 分组函数
6.1 组成
(1)分组关键字:group by ,,将符合条件的记录 进一步的分组。
- select 出现分组函数,就不能使用 非分组信息,可以使用 group by 字段。
- group by字段 可以不出现 select 中 ,反之select 除组函数外的,其他字段必须出现在group by 中。
(2)过滤组关键字:having , 过滤组信息 ,表达式 同 where 一致。
- where :过滤行记录,不能使用组函数, having:过滤组 可以使用组函数。
6.2 现 select 语句结构
select distinct * | 字段 | 表达式 | 函数 as 别名
from 表 表别名
where 过滤行记录条件
group by 分组字段列表
having 过滤组
order by 字段列表 asc | desc6.3 执行顺序
1)、from 2)、where 3)、group 4)、having 5)、select 6)、order by6.4 示范
-- 组信息过滤, 过滤组信息条件
-- 找出20部门和30部门的最高工资
select max(sal) , deptno from emp group by deptno having deptno=20 or deptno=30;
-- 求出每个部门的平均工资
select avg(sal) from emp group by deptno;
-- 求出每个部门员工工资高于1000的的平均工资
select avg(sal) from emp where sal>1000 group by deptno;
---- 求出10和20部门部门的哪些工资高于1000的员工的平均工资
select avg(sal) from emp where sal>1000 group by deptno having deptno in(10,20);
-- 在 where 当中不能使用 字段别名 按照执行顺序
select ename e EN from emp where e ='SMITH';
--查看 高于本部门平均薪水员工姓名
--1、按部门求出平均薪水
--2、关联子查询
select *
from emp e
where exists
(select deptno
from (select deptno, avg(sal) avgsal from emp group by
deptno) e2
where e.deptno = e2.deptno
and e.sal > avgsal);
--另外一种 (推荐)
select *
from emp e1
where sal > (select avg(sal) from emp e2 where e2.deptno =
e1.deptno);
-- 使用一条 sql 语句,查询每门课都大于 80 分的学生姓名
--准备数据
create table tb_student(
id number(4) ,
name varchar2(20),
course varchar2(20),
score number(5,2)
);
insert into tb_student values(1,'张三','语文',81);
insert into tb_student values(2,'张三','数学',75);
insert into tb_student values(3,'李四','语文',81);
insert into tb_student values(4,'李四','数学',90);
insert into tb_student values(5,'王五','语文',81);
insert into tb_student values(6,'王五','数学',100);
insert into tb_student values(7,'王五','英语',90);
commit;
--1) 、每门课 --> 统计课程数 3
select count(distinct(course)) from tb_student ;
--2) 、按学生查看每门课都大于 80 分 最低分大于 80
select name from tb_student group by name having min(score)>80;
-- 综合
select name
from tb_student
group by name
having min(score) > 80 and count(1) = (select
count(distinct(course)) from tb_student);7. 行转列
用于解耦,相同行字段的值合并。
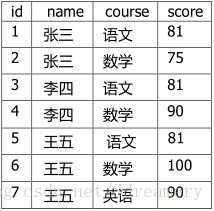

-- 找出课程名 ( 表头 )
select distinct course from tb_student;
-- 数据 ( 行记录 ) 分组(学生 + 行转列 decode )
select * from tb_student;
--1 、行转列 decode
select name,decode(course,'语文',score) 语文,decode(course,'数学',score) 数学,
decode(course,'英语',score) 英语 from tb_student;
--2 、分组
select name,
min(decode(course, '语文', score)) 语文,
min(decode(course, '数学', score)) 数学,
min(decode(course, '英语', score)) 英语
from tb_student
group by name;8. 连表查询
8.1 rowid
(1)特点
- 实现重复记录的删除。
- 唯一标识每一条记录,在记录插入时就已经确定,看做每条记录的地址。
(2)示范
--准备插入数据
insert into tb_student values(1,'张三','语文',81);
insert into tb_student values(2,'张三','数学',75);
insert into tb_student values(3,'李四','语文',81);
insert into tb_student values(4,'李四','数学',90);
insert into tb_student values(5,'王五','语文',81);
insert into tb_student values(6,'王五','数学',100);
insert into tb_student values(7,'王五','英语',90);
--提交事务
commit;
-- 将所有的记录只留下唯一一条, 删除重复的
-- 将数据按照某种规律进行分组, 每组只留下一条
-- 按照名字分组
select name from tb_student group by name;
-- 先按名字分组, 再按课程分组
select name, course,score from tb_student group by name, course,score;
-- 找出要保留的记录
select name, course,score,min(rowid) from tb_student group by name, course,score;
-- 找出要删除的记录
select *
from tb_student
where not rowid in
(select min(rowid) from tb_student group by name, course, score);
--删除
delete from tb_student where rowid not in (select min(rowid) from tb_student group by name, course, score);8.2 rownum
(1)特点
- 必须排序。
- 不能直接取大于 1 的数。
(2)示范
--最底层 rownum 数据库默认顺序号 -->没有用的
select emp.*, rownum from emp;
select emp.*, rownum from emp order by sal ;
--自己 排序后结果集的顺序号
select e.*, rownum from (select * from emp order by sal desc) e;
--取出工资前5名
select e.*, rownum
from (select * from emp order by sal desc) e
where rownum <= 5;
--取出 工资 3-5 名
select e.*, rownum
from (select * from emp order by sal desc) e
where rownum <= 5
and rownum >= 3;
--三层模板 (分页)
-- 按照工资排序, 找第三页的数据
select empno, ename, job, sal, n2, rownum
from (select empno, ename, job, sal, rownum n2
from (select empno, ename, job, sal from emp order by sal desc))
where n2 > (3 - 1) * 3
and n2 <= 3 * 3;
8.3 表连接(92)
当我们获取的数据不是来自于同一张表而是来自于多张表时就需要使用到表连接。
(1)笛卡尔积
非* 必须区分 使用表名 或别名.区分。
select * from emp , dept;
select ename , dname from emp , dept;
select ename, dname, e.deptno from emp e, dept d;(2)等值连接
在笛卡尔积的基础上取条件列相同的值。
--员工名称及部门名称
select ename, dname, e.deptno from emp e, dept d where
e.deptno=d.deptno;
--找出30部门的员工名称及部门名称:先关联后过滤
select ename, dname, e.deptno from emp e, dept d where
e.deptno=d.deptno and e.deptno=30;
--记录很多时 :先过滤后关联
-- 数据来源: emp (select * from emp where deptno=30) e ,
dept(select * from dept where deptno=30) d
select * from emp where deptno=30;
select * from dept where deptno=30;
-- 查询的字段:ename, dname, e.deptno
-- 条件:e.deptno=d.deptno , deptno=30
select ename, dname, e.deptno from
(select * from emp where deptno=30) e ,(select *
from dept where deptno=30) d
where e.deptno=d.deptno;(3)非等值连接 > < != <> between and
--查询员工姓名,工资及等级
--900 属于哪个等级
select grade from salgrade where 900 >losal and 900(4)自连接
特殊的等值连接 (来自于同一张表,但是当做两张表来看)。
--找出 存在上级的员工姓名 及上级名称
-- 数据来源: emp e, emp m
-- 字段: e.ename, m.ename
-- 条件: e.mgr=m.empno
select e.ename, m.ename from emp e, emp m where
e.mgr=m.empno;(5)外连接
-- 找出所有有员工的部门名称以及员工数
--数据:部门名称 dname , 员工数 count(1), 按部门编号分组
--来源:dept d, emp e
--条件:e.deptno=d.deptno
-- select dname, count(1) from dept d, emp e where e.deptno=d.deptno group by e.deptno; 不对
select deptno, count(1) 员工数 from emp group by deptno;
select dname, 员工数
from dept d, (select deptno, count(1) 员工数 from emp group by deptno) e
where d.deptno = e.deptno;主表连接,主表中所有的信息必须至少显示一次(主表就是不加+的表)。
主表在逗号的左边就叫左外连接 主表在逗号的右边叫右连接(不重要)。
--找出 所有部门的员工数 及部门名称
--数据:部门名称 dname , 员工数 count(1), 按部门编号分组
--来源:dept d, emp e
--条件:e.deptno=d.deptno dept为主表
select dname, nvl(en, 0)
from dept d, (select deptno, count(1) en from emp group by deptno) e
where d.deptno = e.deptno(+);8.4 表连接(99)
- 交叉连接 cross join --->笛卡尔积
- 自然连接(主外键、同名列) natural join -->等值连接
- join using连接(同名列) -->等值连接
- [inner]join on 连接 -->等值连接 非等值 自连接 (解决一切) 关系列必须区分
- left|right [outer] join on|using -->外连接
- full join on|using -->全连接 满足直接匹配,不满足 相互补充null ,确保 所有表的记录 都至少出现一次
(1)交叉连接
使用于两个表之间,相当于 92 中的逗号。
select *form emp cross join dept;(2)自然连接(naural join)
自然连接属于一种等值连接,它可以自动找同名列,自动做等值连接,同名列不能加限定词。
-- 找出每个员工信息和所在部门信息
--自然连接(等值连接,自己找同名列) naural join
-- emp dept deptno
select dname, empno, ename,deptno from emp natural join dept;(3)using 连接
using 连接也属于一种等值连接,在 using 连接中必须存在同名列,指定同名列,自动做等值连接。
-- using连接,必须存在同名列,指定同名列,自动做等值连接
select * from emp join dept using(deptno) ;(4)on 连接
on 连接(如果是同名列,必须加限定词),可以做等值|非等值,任何列都可以进行关联。
-- on 连接(如果是同名列,必须加限定词) 可以做等值|非等值 任何列都可以进行关联
select * from emp e join dept d on e.deptno=d.deptno;-- 查询30部门的员工信息和部门信息
--数据:ename, empno, sal, deptno, dname, loc
--来源:emp e, dept d
--条件:连接条件:员工所在的部门编号=部门信息的部门编号, 需求条件:30部门
select ename, empno, sal, e.deptno, dname, loc
from dept d
join emp e
on e.deptno = d.deptno
where d.deptno = 30;
-- 查询每个员工的工资,姓名,工种, 工资等级
--数据: sal, ename, job, grade
--来源:emp, salgrade
--条件:连接条件(sal between losal and hisal)
select sal, ename, job, grade from emp e join salgrade s on e.sal between s.losal and s.hisal;
-- 查询20部门工资大于1500员工的工资,姓名,工种, 工资等级
-- 数据: sal, ename, job, grade
-- 来源:emp e, salgrade s
-- 条件:连接条件(sal between losal and hisal) 需求条件(e.deptno=20 and e.sal>1500)
select sal, ename, job, grade, deptno
from emp e
join salgrade s
on e.sal between s.losal and s.hisal
where e.deptno = 20
and e.sal > 1500;
--部门编号为30的员工 员工名称 部门名称 工资等级 上级名称
--数据: e.ename, d.dname, s.grade, m.ename
--来源:emp e, dept d, salgrade s,emp m
--条件:
-- 连接条件: e.deptno=d.deptno and (e.sal between s.losal and s.hisal) ande.mgr=m.empno
-- 需求条件: e.deptno=30
select e.ename 员工名称, d.dname, s.grade, m.ename 上级名称,e.deptno
from emp e
join dept d
on e.deptno = d.deptno
join salgrade s
on e.sal between s.losal and s.hisal
join emp m
on e.mgr = m.empno
where e.deptno = 30;(5)外连接
- 当是主表时以主表的字段为依据进行查询。
- 在99语法中主表看 left 和 right,当使用 left 时左边是主表,使用 right 时右边是主表。
-- 外连接
-- left join rigth join
--所有部门的 部门名称,员工数
-- 数据: d.dname,e.en
-- 来源: dept d, (select deptno, count(1) en from emp group by deptno) e
-- 条件:连接条件 d.deptno=e.deptno 以部门表为主表
select d.dname, nvl(e.en,0), d.deptno
from dept d
left join (select deptno, count(1) en from emp group by deptno) e
on d.deptno = e.deptno;
select d.dname, nvl(e.en,0), d.deptno
from
(select deptno, count(1) en from emp group by deptno) e right join dept d
on d.deptno = e.deptno;
-- 所有有员工的部门名称和员工数
-- 数据: d.dname,e.en
-- 来源: dept d, (select deptno, count(1) en from emp group by deptno) e
-- 条件:连接条件 d.deptno=e.deptno
-- on连接
select d.dname, e.en, d.deptno
from dept d
join (select deptno, count(1) en from emp group by deptno) e
on d.deptno = e.deptno;(6)全连接
所有的表都为主表,所有字段都要显示。
-- 准备数据1(伪列+集合操作)
select 1 no , 'a' name from dual
union
select 2 no , 'b' name from dual;
-- 准备数据2
select 1 no , 'c' name from dual
union
select 3 no , 'd' name from dual;
-- 内连接
select * from (select 1 no, 'a' name
from dual
union
select 2 no, 'b' name
from dual) t1
join (select 1 no, 'c' name
from dual
union
select 3 no, 'd' name
from dual) t2
on t1.no = t2.no;
-- 左外连接
select * from (select 1 no, 'a' name
from dual
union
select 2 no, 'b' name
from dual) t1
left join (select 1 no, 'c' name
from dual
union
select 3 no, 'd' name
from dual) t2
on t1.no = t2.no;
--右外连接
select * from (select 1 no, 'a' name
from dual
union
select 2 no, 'b' name
from dual) t1
right join (select 1 no, 'c' name
from dual
union
select 3 no, 'd' name
from dual) t2
on t1.no = t2.no;
-- 全连接
select * from (select 1 no, 'a' name
from dual
union
select 2 no, 'b' name
from dual) t1
full join (select 1 no, 'c' name
from dual
union
select 3 no, 'd' name
from dual) t2
on t1.no = t2.no;