Oracle 分组求和函数(rollup、cube、grouping sets)
文章目录
- 1 场景
- 1.1 概念
- 1.2 思维导图
- 1.3 数据准备
- 2 知识点小结
- 2.1 group by
- 2.2 grouping sets:单独分组
- 2.3 rollup:累计累加
- 2.4 cube(交叉列表)
- 2.6 grouping
- 2.7 grouping_id
1 场景
内容修改中,请稍等…
1.1 概念
rollup,cube,grouping sets函数可以理解为group by分组函数封装后的精简用法,相当于多个union all的组合显示效果,但是要比 多个union all的效率要高。
1.2 思维导图
1.3 数据准备
-- 人员信息表
CREATE TABLE person_info (
person_no NUMBER(5),
person_name VARCHAR2(30),
sex VARCHAR2(3),
money NUMBER(8),
work_location VARCHAR2(10)
);
-- 测试数据
insert into person_info (PERSON_NO, PERSON_NAME, SEX, MONEY, WORK_LOCATION)
values (1, '瑶瑶', '女', 100000, '深圳');
insert into person_info (PERSON_NO, PERSON_NAME, SEX, MONEY, WORK_LOCATION)
values (2, '倩倩', '女', 200000, '深圳');
insert into person_info (PERSON_NO, PERSON_NAME, SEX, MONEY, WORK_LOCATION)
values (3, '优优', '男', 300000, '深圳');
insert into person_info (PERSON_NO, PERSON_NAME, SEX, MONEY, WORK_LOCATION)
values (4, '丽丽', '女', 200000, '武汉');
insert into person_info (PERSON_NO, PERSON_NAME, SEX, MONEY, WORK_LOCATION)
values (5, '萌萌', '女', 100000, '武汉');
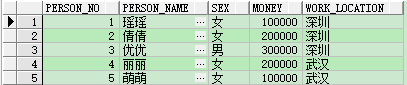
数据截图如下:
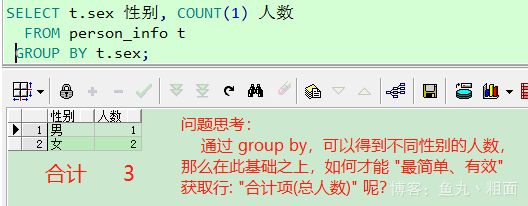
- 为了简洁说明情况,下列求和均用
count(1) - 自测时,也可用
sum(money), 效果是一样的。
2 知识点小结
2.1 group by
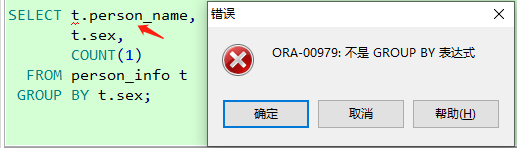
group by表达式为以下两种情况- 聚合函数,如:
sum() 、max()、min()、avg()、count() - 存在
group by + 具体列(如下图的sex)
- 聚合函数,如:
- 筛选只能
having,不能是where.
SELECT t.sex, COUNT(1)
FROM person_info t
-- WHERE COUNT(1) >= 2 -- 报错
GROUP BY t.sex
HAVING COUNT(1) > = 2;
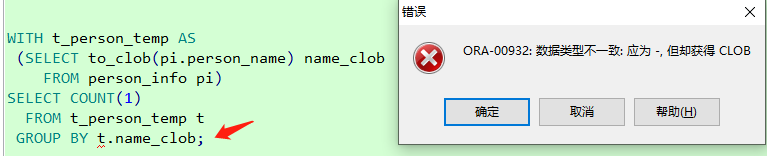
- 不能对
clob类型项目进行group by
WITH t_person_temp AS
(SELECT to_clob(pi.person_name) name_clob
FROM person_info pi)
SELECT COUNT(1)
FROM t_person_temp t
GROUP BY t.name_clob;
2.2 grouping sets:单独分组
group by (A, B)是 对 A,B 共同 进行分组group by grouping sets(A, B)是对 A,B 单独 进行分组

等价 sql 语句:
SELECT t.person_name,
t.sex,
COUNT(1)
FROM person_info t
GROUP BY GROUPING SETS(t.person_name, t.sex);
等同于下列
SELECT t.person_name,
NULL,
COUNT(1)
FROM person_info t
GROUP BY t.person_name
UNION ALL
SELECT NULL,
t.sex,
COUNT(1)
FROM person_info t
GROUP BY t.sex;
2.3 rollup:累计累加
group by rollup(A, B, C),首先对A,B,C进行group by,然后对A,B进行group by,然后对A进行group by,最后对全表进行group by.- 若有
N列,则group by N + 1次 - 有默认排序哦
SELECT A, B, C, SUM(D) FROM table_name GROUP BY ROLLUP(A, B, C);
等同于
SELECT * from (
SELECT A, B, C, SUM(D) FROM table_name GROUP BY(A, B, C)
UNION ALL
SELECT A, B, null, SUM(D) FROM table_name GROUP BY(A, B, null)
UNION ALL
SELECT A, null, null, SUM(D) FROM table_name GROUP BY (A, null, null)
UNION ALL
SELECT null, null, null, SUM(D) From table_name group by (null, null, null)
) order by 1, 2, 3

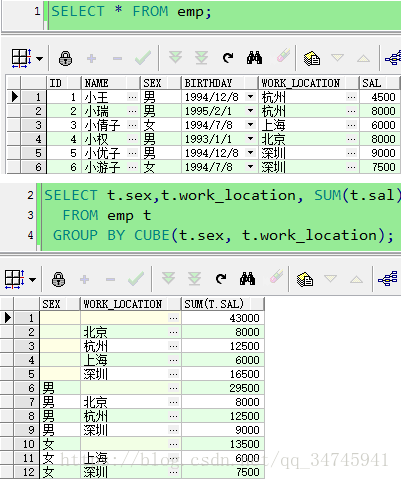
2.4 cube(交叉列表)
- 交叉组合,与顺序无关(rollup 则与顺序有关)
- 若有 N 列,则 group by 2^N 次
它比 rollup 扩展更加精细,组合类型更多,对于 cube 来说,列的名字只要一样,那么顺序无所谓,结果都是一样的,因为 cube 是各种可能情况的组合,只不过统计的结果顺序不同而已。但是对于 rollup 来说,列的顺序不同,则结果不同。
如果是GROUP BY CUBE(A, B, C),GROUP BY顺序:
(A、B、C)
(A、B)
(A、C)
(A),
(B、C)
(B)
(C),
最后对全表进行GROUPBY操作。
2.6 grouping
用于区分 原有值 和 统计项
- 參数仅仅有一个,并且必须为group by中出现的某一列
- grouping = 0 : 数据库中本来的值
- grouping = 1 : 统计的结果

2.7 grouping_id
区分 小计项 和 合计项。Grouping_id()的返回值事实上就是參数中的每列的grouping()值的二进制向量。假设grouping(a)=1,grouping(b)=1,则grouping_id(A,B)的返回值就是二进制的11。转成10进制就是3。
- 參数能够是多个,但必须为group by中出现的列。
- grouping 用于判断 小计项(grouping(A) = 1)
- grouping_id 用于判断 合计项(grouping(A, B) = 1 + 1 = 3;小计 + 小计 = 合计)

##2.8 group_id
GROUP_ID()唯一标识反复组,能够通过group_id去除反复组
- group_id()函数,无参数
- 0表示第一次,1表示重复。
