Nat. Rev. Neurol. | 机器学习在神经退行性疾病诊断和治疗中的应用
作者 | 朱玉磊
审稿 | 李芬

今天为大家介绍的是2020年6月谢菲尔德大学Laura Ferraiuolo教授课题组和BenevolentAI公司合作发表在Nature Reviews Neurology上的一篇有关神经退行性疾病诊断和治疗中的机器学习应用的综述。在这篇综述中,作者重点介绍了机器学习如何帮助人们早期诊断疾病、解释医学图像以及发现和开发新的疗法,有助于增进科学家们对疾病进程的了解。
1
介绍
近年来,机器学习算法在医学和科学研究中的应用得到了广泛的讨论。高维的疾病数据集通常是稀疏的、有噪声的、横截面的和缺乏统计能力的,这使得使用传统的数据分析方法(寻找单个变量的变化或执行简单的相关性)从这些数据中获得生物学见解变得极其困难。数据分析中的这些问题由于对理解疾病机制所必需的各种数据类型(例如,成像、基因组学和临床数据)的集成而进一步复杂化。为了应对这些挑战,先进的机器学习模型越来越多地应用于生物医学和医疗保健数据。
传统的计算机科学通过应用预定义的规则从输入数据中获得结果,而机器学习则直接从输入数据中学习规则和洞察力,从而允许应用这些规则在新的情况下从数据中做出预测。机器学习方法可以在最少变量的情况下通过减少分析的特征数量帮助克服高维数据的挑战。
2
机器学习方法
机器学习方法被广泛地分为监督、非监督和强化学习方法。
监督机器学习算法是目前最常用的方法,用于神经退行性疾病相关数据,并需要一个标记数据集从中学习。通常,这些标签需要人工管理或专家评估。一旦这个“基准”数据集被标记出来,机器学习算法就会建立一个输入特征和标签之间的关系模型。然后,该算法可以将该模型应用于新的未标记数据集,根据新的输入特征预测标签。监督机器学习分为分类算法和回归算法。分类算法,预测每个数据样本的分类输出。相比之下,回归算法为每个数据样本预测一个实值变量(例如,连续尺度上测量的功能损害程度)。当应用于医疗保健数据时,分类和回归算法都可以通过识别数据内的模式和相似的聚类区域来定义患者内型——疾病群体中具有相同功能和病理特征的一群个体。回归方法的一个实际例子是在模拟运动功能下降、疾病持续时间或进展斜率的算法基础上,将患者分型为进展内型,以形成进展时间序列的细微表征。
与有监督的机器学习相反,无监督机器学习算法不需要带标签的数据,并且对于将数据样本聚类成组,或者生成高度复杂的数据的更简单的表示来降低数据集的维度任务很有用。此外,无监督的聚类方法,如潜在变量模型,可以帮助识别基因的共同表达模块,这些模块是可能被共同调控或符合共同的生物机制或通路的一组基因。除了分析现有数据,无监督聚类算法也可以用来进行预测。
监督学习方法和无监督学习方法可以结合,形成半监督学习方法。半监督方法用额外的未标记数据丰富一小组标记数据,这使得聚类(非监督)方法可以提高分类(监督)方法的性能,并使用额外的数据规范化预测模型。同样,转导学习方法使用测试数据作为未标记数据来改进标准监督分类方法;这些方法不会导致数据泄漏,因为标签不是共享的,并且可以提高可用数据量低时的性能。
最后,在强化学习方法中奖励或惩罚,以实现预期的输出。在训练过程中,如果对一种新药产生负面反应或药物与药物的相互作用产生不良反应,就会对算法进行惩罚,而对一种能够改善病程的药物进行奖励,这是预期的结果。
3
模型选择
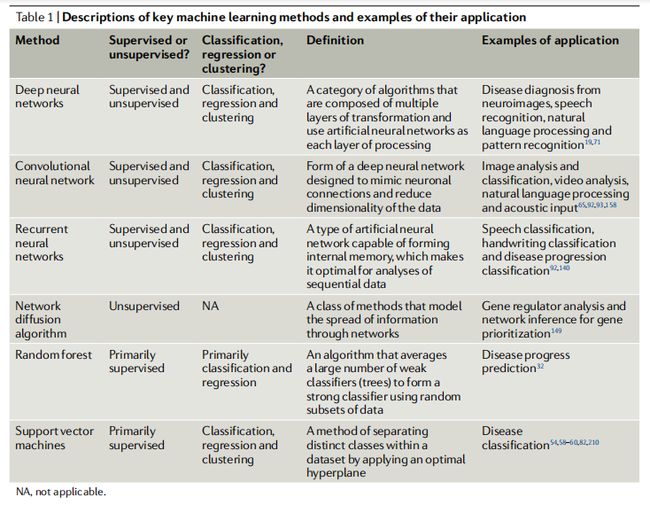
存在大量的机器学习算法,选择正确的算法来应用于特定类型的数据是很重要的。由于特别关注监督学习,有两个因素与选择正确的算法特别相关:模态(数据的形式)和容量(数据样本的数量)。在容量方面,对于样本特征比低 (SFR <10:1)的数据集,算法除了分类外还将努力学习一个有用的“特征化”。对于这样有限的数据集、高度受限或“正则化”的模型,如层次贝叶斯模型,通过学习数据的少数参数,简化了任务并指导算法。对于较大的数据集,通常使用支持向量机(SVM)或随机森林。这些方法比分层贝叶斯模型更灵活,但需要更大的数据量,而且更复杂。
人工神经网络,包括流行的深度神经网络,被广泛用于分析数据的许多模式,特别是图像、视频和声音数据。在预处理过程中,人工神经网络比支持向量机或随机森林需要更少的手工数据操作步骤,并且在某些情况下,将分类器的选择纳入网络架构。这些网络大多是监督的,但也可以是无监督的。CNN从人类视觉系统中汲取灵感,在越来越高的抽象层次上提取特征,首先结合局部信息,最终在图像中整合大规模信息。递归神经网络(RNN),可以从数据序列中提取信息,对分析临床记录特别有用。RNN模型如长短期记忆(LSTM)和门控递归单元构成了大多数序列任务中使用的构建块。这些模型包含一个允许算法学习长期依赖关系和门控单元的记忆单元,这些门控单元控制记忆内容的暴露和根据输入对记忆内容做出改变的程度。在选择机器学习模型时,需要减轻的一些关键技术风险包括数据量不足、数据表示不当、过拟合、不正确的超参数选择和数据缺失。
4
诊断及预知
在许多神经退行性疾病中,包括AD、PD和MND,症状只有在神经细胞大量丧失时才会出现,这使得早期诊断非常具有挑战性。因此,将机器学习模型应用于早期诊断的研究也在不断增长。

这项研究的目的是使用机器学习来检测数据中相对容易收集的预知信号(例如电子健康记录(EHRs)或MRI数据),从而使老年人群的前瞻性筛查成为可能。然后,机器学习驱动的自动诊断可以标记个人进行进一步的临床研究。这种方法需要机器学习模型足够敏感,能够发现早期疾病信号,并且足够具体,不会给卫生系统带来不必要的后续测试负担。目前,测试结果需要由训练有素的工作人员进行分析和解释,这可能导致诊断的延误。这些延迟可以通过对在诊所收集的数据应用机器学习方法来减少。通过比较具有相同内型或表型的患者的历史数据,这些相同的数据可以用于预测患者的情况。
4.1神经成像
CT和MRI等神经成像技术经常用于神经退行性疾病的诊断,而放射学是最早受益于医学计算机化和“智能机器”引入的领域之一。计算机辅助诊断系统可辅以监督学习技术,以进一步改善神经影像资料的解释,并帮助识别影像中未被放射科医师发现的细微异常。支持向量机被用于分析MRI数据,有时结合结构和功能MRI和认知评估数据来改善疾病诊断。
为了提高对神经退行性疾病及其进展的了解,作者正在收集患者的神经成像数据数据库,目的是建立从诊断开始的疾病病程的全面图景。神经成像是研究大脑活动的一种方法。其他监测大脑活动的方法,如脑电图(EEG),也可以从机器学习驱动的数据分析中受益。
4.2运动机能
许多神经退行性疾病,如MND、亨廷顿舞蹈病(HD)和PD,以运动功能障碍为特征,通常以丧失运动能力告终。在写作任务分析中引入机器学习技术,可以帮助对PD患者进行分类,并作为诊断工具。运动数据也可以用于AD的研究。医生可以观看病人进行日常生活器械活动(IADL)(如洗澡、穿衣和吃饭)的录像,并手动评分。深度学习和基于CNN的机器学习算法能够从视频中识别动作,该技术已应用于IADL录音中的动作识别。
4.3语言特征
语言特征是认知状态的重要指标,因为在许多神经退行性疾病中,交流技能和人际行为会恶化。机器学习方法已经被用来从录音文本中提取语言特征,以区分AD患者和健康个体。除了基于机器学习的文本分析外,人工智能驱动的交互式形象符号还被用于捕获更复杂的语言数据。
4.4分子和遗传数据
提高我们对神经退行性疾病的分子基础的理解是开发新疗法和诊断和预知的关键。下一代测序技术提高了DNA测序的速度,使大量数据可以相对较快地获得。产生的大量基因组数据,特别是在GWAS和其他大型队列研究中,需要一种非常精细的分析方法,而机器学习技术在这个领域被证明是有用的。应用机器学习来研究患者样本中的蛋白质特征可以帮助发现生物标志物,这反过来可能会改善疾病诊断。同样,在最近的研究中,机器学习已被应用于MS145或AD146患者的代谢组学数据,以识别这些疾病的新的生物标记。
4.5临床记录
除了上面讨论的应用程序,机器学习还可以用于挖掘日常收集的医疗保健数据,以获得新的见解。机器学习可用于对纵向EHR数据进行时间序列分析。在这些分析中,算法从历史数据中学习预后签名,并在新的数据集中寻找这些签名,为患者创建个性化的健康预测。深度学习方法依赖于大量数据的输入,适合于对电子病历的分析,在某些情况下,电子病历包含了关于全国大多数人口的信息。神经网络模型已被有效地应用于EHRs中,以预测临床事件,提高诊断水平。
5
治疗的发展
许多神经退行性疾病缺乏有效的治疗方法,但这些疾病的临床试验失败率很高,导致大型制药公司撤回投资。大量潜在治疗方法的临床试验失败凸显了开发治疗大脑疾病的复杂性,并为新药开发创造了机会。
5.1靶标识别
神经退行性疾病涉及大量的机制,都有助于疾病的病理。药物靶标识别的一种机器学习方法是知识图上的关系推理,它将基因、疾病和药物等实体连接起来。知识图通常是由多种数据类型的集成构建的。知识图方法可以学习非明显的疾病和生物药物靶点之间的联系(例如,确定新的治疗目标蛋白质与蛋白质的相互作用的基础上已知突变在一个特定的疾病),而且也是有吸引力的,因为一个算法可以用来对多种疾病进行预测。机器学习还可以用于执行大规模的文本挖掘,以提出可能与某种感兴趣的疾病相关的蛋白质。基于机器学习的生物样本分析(例如,死后的中枢神经系统组织)也可能为目标识别提供有用的信息。
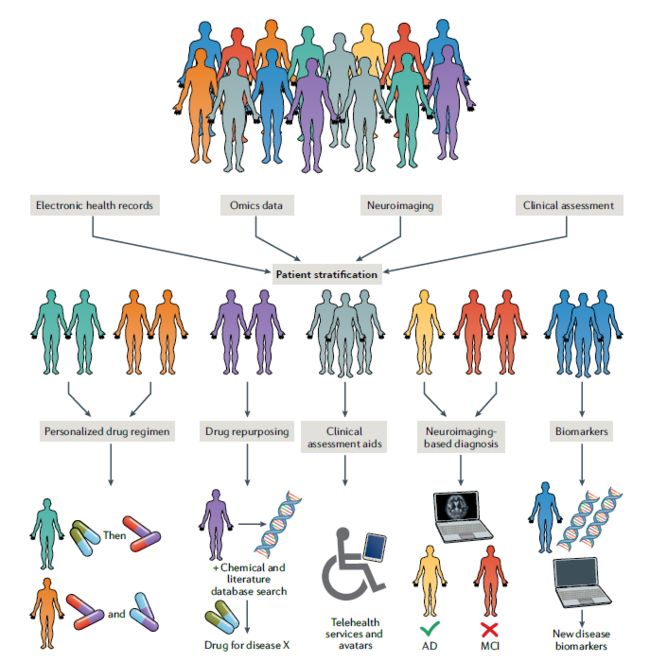
5.2病人分层
临床表现、疾病进展和遗传易感性的异质性常常存在于诊断为同一神经退行性疾病的个体群体中。这种异质性使得从整体上研究诊断组来理解疾病机制变得困难,因为不同的个体可能有不同的机制导致疾病的发生,这也使得确定有效的治疗方法变得更具挑战性。因此,根据比诊断类更详细的标准对研究参与者进行分层正变得越来越普遍。患者群体的异质性也是临床试验设计的一个问题。结果变量的自然异质性是一种无益的噪声源,可以掩盖治疗干预的效果。
6
结论和未来的挑战
机器学习算法可以识别模式,并从大量的多维数据中做出新的推论,而这是人类做不到的。在未来,机器学习技术可能会基于病史、分子谱和影像学信息,并通过识别更具体的诊断生物标志物,对神经退行性疾病做出更准确、更早的诊断.
尽管机器学习很有潜力,但创建和应用机器学习算法来处理神经退行性疾病数据仍然很困难。其中一个挑战与数据本身有关——机器学习模型的强大程度取决于它们所依赖的数据。对于许多疾病来说,缺乏大型数据集,特别是多维的患者数据,是机器学习应用的一个障碍。需要对机器学习模型的性能进行稳健的评估,为任务选择最佳的模型,并确保临床医生对模型的输出有信心。许多机器学习算法的另一个局限性是它们是“黑盒”,也就是说,它们不能用来理解它们解决的问题或产生的输出。要解决将机器学习应用于神经退行性疾病数据的挑战,需要生物医学专家和机器学习专家之间的合作。
总之,将机器学习的整合到诊断和预测神经病学实践中,以及设计未来的治疗方法,可能是通过国家和国际努力建立多学科专家组来解决本综述文章中讨论的一些主要挑战而实现的。尤其在人口逐渐老龄化的社会,这些显得尤为重要。
参考资料
Myszczynska, M.A., Ojamies, P.N., Lacoste, A.M.B. et al. Applications of machine learning to diagnosis and treatment of neurodegenerative diseases. Nat Rev Neurol 16, 440–456 (2020).
https://doi.org/10.1038/s41582-020-0377-8
