聊一聊Docker所使用到的Linux底层技术(Namespace,Cgroup与存储驱动和容器引擎)
容器
-
基于镜像
镜像image就是附加一个JSON配置文件的tar包。镜像常常是嵌套的,防止重复内容占用空间 -
容器运行时会从某处下载镜像,这个地方称为registry。Registry通常是一个通过HTTP协议暴露镜像的元数据和文件以供下载的容器仓库
-
运行时将层次化的镜像解压到支持Copy on Write(CoW)的文件系统里。通常这通过覆盖(overlay)文件系统来实现,所有的层次层层覆盖来构成一个合并的文件系统。 这个步骤通常不能通过命令行直接访问,而是当运行时创建容器时会自动在后台发生
-
运行时来实际地执行容器。 它告诉内核给容器分配合适的资源限制,创建隔离的层(为进程,网络,文件系统等),使用各种机制的混合(包括cgroups,namespaces,capabilities, seccomp, AppArmor, SELinux,等等),底层实际调用的是runC命令
-
容器引擎常见的就是docker,也可以是其他容器引擎,创建容器就是把磁盘上的容器镜像运行成宿主机的一个进程
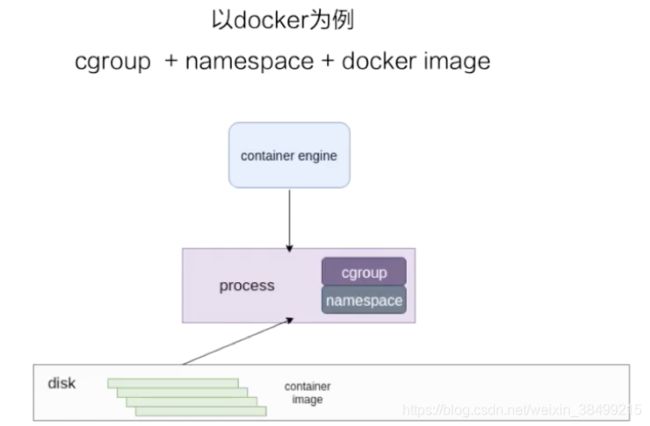
Namespace
首先要理解docker本质上是一个运行在宿主机上的一个进程,用于帮助进程隔离出自己单独的空间.
Linux Namespace可以隔离一系列的系统资源,如进程ID,网络资源,用户ID.
Linux现在实现了六种Namespace
-
UTS Namespace
主要用来进行hostname和domain的隔离 -
IPC Namespace
控制了进程兼通信的一些东西,比方说信号量。 -
PID Namespace
用来进行进程ID的隔离,保证了容器的 init 进程是以 1 号进程来启动的。 -
Mount Namespace
用来隔离各个进程看到的挂载点视图
是保证容器看到的文件系统的视图,是容器镜像提供的一个文件系统,也就是说它看不见宿主机上的其他文件
-
User Namespace
隔离用户的用户组ID,一个在宿主机上以非root用户可以在一个User namespace内映射成root用户 -
Network Namespace
网络设备,IP地址,端口的隔离使得每个容器有自己独立的虚拟网络设备.即使不同容器的服务映射到相同的端口,都不会冲突.在宿主机搭建了网桥后,能很方便实现容器之间的通信.并且不同容器之间应用可以使用相同的端口.
Cgroups
Cgroup提供了对一组进程与将来子进程的资源限制,控制和统计的能力.
这些资源包括cpu,内存,存储,网络等.通过Cgroups可以方便限制某个进程的资源使用,并且可以实时进行对进程的监控与统计
两种cgroup驱动
-
systemd
system daemon 的cgroup驱动 -
cgroupfs
要用 CPU share 为多少,直接把 pid 写入对应的一个 cgroup 文件,然后把对应需要限制的资源也写入相应的 memory cgroup 文件和 CPU 的 cgroup 文件就可以了
三个组件
- cgroup
对进程分组管理的一种机制,负责把一组进程和一组subsystem的系统参数关联起来 - subsystem
一组资源控制的模块 - hierarchy
把cgroup串成一个树状的结构
容器常用的cgroup
- cpu
- memory
- device
上面三个好理解 - freezer
停止容器的时候,freezer会把当前进程全部写入cgroup,然后所有进程都冻结掉,目的是防止在停止的时候,有进程会去做fork,这样的话防止进程逃逸到宿主机上去。 - blkio
block io,主要限制磁盘IOPS和bps速率 - pid
限制容器里可以用到的最大进程数量
操作cgroup
- 创建并且挂载一个hierarchy
mkdir cgroup-test
sudo mount -t cgroup -o none,name=cgroup-test cgroup-test ./cgroup-test
ls ./cgroup-test
- 在创建好的hierarchy上cgroup根节点扩展出两个子cgroup,子cgroup会扩展父cgroupd的属性

- 在cgroup中添加和移动进程
一个进程在一个cgroup的hirearchy进程中,只能在一个cgroup节点上存在,只要把该进程ID写入该cgroup节点的tasks文件,就可以把进程移动到这个cgroup节点
sudo sh -c "echo $$ >> tasks"

- 通过subsystem限制cgroup中的进程资源
通过
mount | grep memory
查看哪个目录挂在了memory subsystem的hierarchy上
![]()
sudo mkdir test-limit && cd test-limit
sudo sh -c "echo "100m" > memory.limit_in_bytes"
sudo sh -c "echo $$ > tasks"
stress --vm-bytes 200m --vm-keep -m 1
我们可以看到,虽然压测声明占用内存为200m,但实际上cgroup为其限制了内存资源只能使用100m.
下面用go来模拟cgroup限制容器的资源
package main
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path"
"strconv"
"syscall"
)
//挂在了memory subsystem的hierarcy目录
const cgroupMemoryHierarchyMount = "/sys/fs/cgroup/memory"
func main() {
if os.Args[0] == "/proc/self/exe" {
fmt.Printf("current pid %d", syscall.Getpid())
fmt.Println()
//启动一个占用内存200m的进程
cmd := exec.Command("sh", "-c" , `stress --vm-bytes 200m --vm-keep -m 1`)
cmd.SysProcAttr = &syscall.SysProcAttr{
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
cmd := exec.Command("/proc/self/exe")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS|syscall.CLONE_NEWPID|syscall.CLONE_NEWNS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Start();err!=nil{
fmt.Println("ERROR", err)
os.Exit(1)
} else {
fmt.Printf("%v", cmd.Process.Pid)
//在挂载了memory subsystem的Hierarchy上创建cgroup文件
err := os.Mkdir(path.Join(cgroupMemoryHierarchyMount, "test"),0755)
if err != nil {
fmt.Println("mkdir failed ", err)
os.Exit(1)
}
writeErr := ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "test", "tasks"),
[]byte(strconv.Itoa(cmd.Process.Pid)),0644)
if writeErr != nil {
fmt.Println("write failed", writeErr)
os.Exit(1)
}
limitErr := ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "test", "memory.limit_in_bytes"),
[]byte("100m"),0644)
if limitErr != nil{
fmt.Println("write Limit file error", limitErr)
os.Exit(1)
}
}
_,waitErr := cmd.Process.Wait()
if waitErr != nil{
fmt.Println("wait error",waitErr)
}
}
这段程序实际上是模拟了用命令行创建cgroup并对进程的资源做限制(从200m到100m)
运行这段程序后,可以用top指令观察stress进程占用的内存会从200m变为只有100m
Docker的存储驱动
先介绍一下Docker是如何建立image的.然后又是如何在image的基础上创建容器.
- docker镜像由一层层layer组合起来
- 每一层layer对应的是Dockerfile中的一条指令
- 这些layer中,一层layer为R/W layer即container layer
- 其他layer是read-only layer
- 通常最后一层为CMD层或者ENTRYPOINT层,这一层是R/W的.
我们知道,多个容器可以依赖一份image启动,那么这些容器究竟是共用一个image,还是说各自把这个image复制了一份,然后各自独立运行呢?
假设每个容器都复制了一份image,那么其实对空间是一种巨大的浪费.
所以所有的容器其实都是共用一个image,但是如何保证一个容器的修改对其他容器是不可见的呢?
我们先不管这个问题,先讨论一下镜像的分层机制.

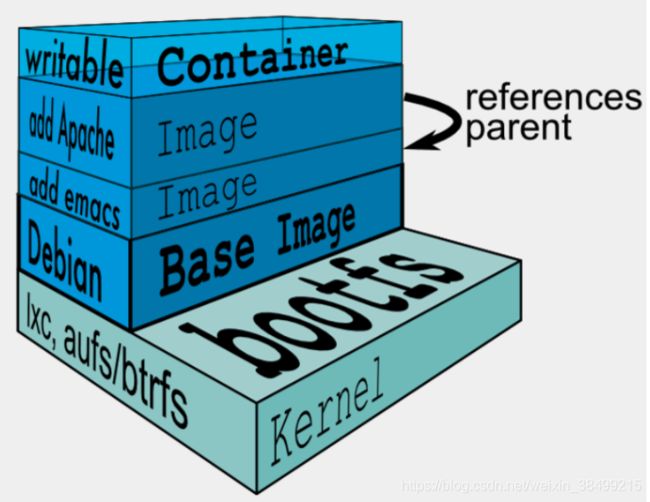
镜像是只读的,每一层都是只读的.在内核的上面,最底层是一个基础镜像层(Debian),如果想要在ubuntu基础镜像上装一个emacs编辑器,则只能在基础镜像之上,再去构建一个新的镜像层.以此类推,如果想要在emacs镜像层上添加一个apache,则只能再在其上面再构建一个新的镜像层.每一层实际上都是挂载在宿主机相应的目录下
容器读写层工作原理
其实在镜像的最上层,还有一个读写层,这个读写层即在容器启动的时候为当前容器单独挂载.所有对容器的操作都发生在读写层.一旦容器销毁,这个读写层也会随之销毁.
所以 容器 = 镜像 + 读写层
对这个读写层的操作主要有写时复制和用时分配
- 写时复制
只有在写的时候才去复制.所以所有容器而已共享镜像的文件系统,所有的文件与数据都是从image读取.当要对文件进行写操作的时候,才从image把要写的文件复制到容器内的文件系统进行修改.所以无论有多少个容器共享同一个image,所做的写操作其实都是对从image中复制到自己的文件系统中的复本中进行,不会修改image的源文件.
所以不同容器对同一个文件的修改,实际上是把镜像中的这个文件复制到容器的自己的文件系统内,然后对这个文件的复本进行修改,相互隔离,互不影响
- 用时配置
启动一个新的容器的时候,并不会为这个容器预分配一些磁盘空间,而是当有新文件写入的时候,才会按需分配新空间.
UnionFS
- 把其他文件系统联合到一个联合挂载点的文件系统服务
- 使用branch把不同文件系统的文件与目录"透明地"覆盖,形成一个单一一致的系统.
- 可以把其看作是一个虚拟的联合文件系统.对这个虚拟的联合文件系统进行写操作的时候,系统是真正写到了一个新文件中.
简单来说就是支持将不同目录挂载到同一个虚拟文件系统下的文件系统。这种文件系统可以一层一层地叠加修改文件。无论底下有多少层都是只读的,只有最上层的文件系统是可写的。当需要修改一个文件时,AUFS创建该文件的一个副本,使用CoW将文件从只读层复制到可写层进行修改,结果也保存在可写层。在Docker中,底下的只读层就是image,可写层就是Container。
OverlayFS
与AUFS多层不同的是,OverlayFS只有两层.
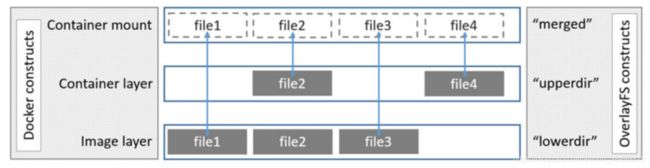 upperdir可读写,对应为读写层
upperdir可读写,对应为读写层
lowerdir只读,对应为镜像层
如果发生对文件的修改,把文件从lowerdir复制到upperdir,写后结果也是保存在upperdir的.
我们自己来手动实现一个AUFS!
首先
mkdir aufs
然后创建一个container-layer,在里面添加一个含有"I am container-layer"的文件
然后创建一个mnt文件夹.
然后分别创建4个image-layer{n}文件夹,每个文件夹都有一个含有"I am image-layer{n}"的文件.
这里提供了一个脚本.
#!/bin/bash
for k in $(seq 1 4)
do
mkdir image-layer${k}
cd image-layer${k}
touch image-layer${k}.txt
echo "I am image layer${k}" >> image-layer${k}.txt
cd ..
done
然后我们就可以把container-layer和四个image-layer挂载到mnt文件夹.默认dirs=右边第一个文件夹是读写的,其余都是只读的.
sudo mount -t aufs -o dirs=./container-layer:./image-layer4:./image-layer3:./image-layer2:./image-layer1 none ./mnt
我们可以观察一下现在mnt目录结构
mnt
├── container-layer.txt
├── image-layer1.txt
├── image-layer2.txt
├── image-layer3.txt
└── image-layer4.txt
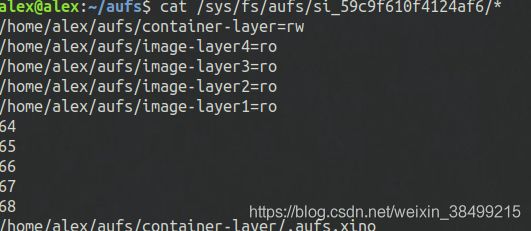
这时候查看一下文件的读写权限.可以看到只有container-layer是读写的,其他都是只读的.

mnt其实只是一个虚拟的挂载点.它里面真实的文件是container-layer内的文件.
而且对mnt内的文件进行修改的时候,不会影响源文件image-layer4内的文件,实际上是从image-layer4中把源文件复制一个副本到读写层(container-layer)去修改并且保存的.
Docker 创建一个容器之后会发生什么?
- 首先会发现PID=1的进程,即指定的前台进程,容器创建的时候其实第一个执行的进程不是用户的进程,而是init初始化的进程,即PID的进程.那和我们预想的不一样,而且PID=1的进程是不能被kill掉的
- 因此需要借助execve这个系统调用
int execve (const char& *filename, char *const argv[], char *const envp[])
可以覆盖当前进程的镜像,数据和堆栈信息包括PID,这些都会被要运行的进程覆盖掉.
总结起来:
1.先创建容器,然后配置Namespace,创建父进程.
2,挂载文件系统然后替换init进程为用户进程
3.完成容器创建
容器引擎

上图是containerd的架构图
那么什么是containerd呢?
Containerd
Containerd是一个工业标准的容器运行时,重点是它简洁,健壮,便携,在Linux和window上可以作为一个守护进程运行,它可以管理主机系统上容器的完整的生命周期:镜像传输和存储,容器的执行和监控,低级别的存储和网络。
容器运行时的定义是:能够基于在线获取的镜像来创建和运行容器的程序.
Containerd把容器运行时以及管理功能从Docker Daemon剥离,其本身也是一个守护进程.容器的实际运行时由runC来控制.
主要职责是镜像管理(镜像、元信息等)、容器执行(调用最终运行时组件执行)

容器运行引擎runC
总结而言,containerd是对runC向上封装了一层.runC可以理解为是一个轻量级的容器运行引擎,包括所有Docker使用的和容器相关的系统调用的代码.
containerd负责容器镜像的拉取,容器的创建与停止,网络以及存储等,而具体运行容器由runC负责.
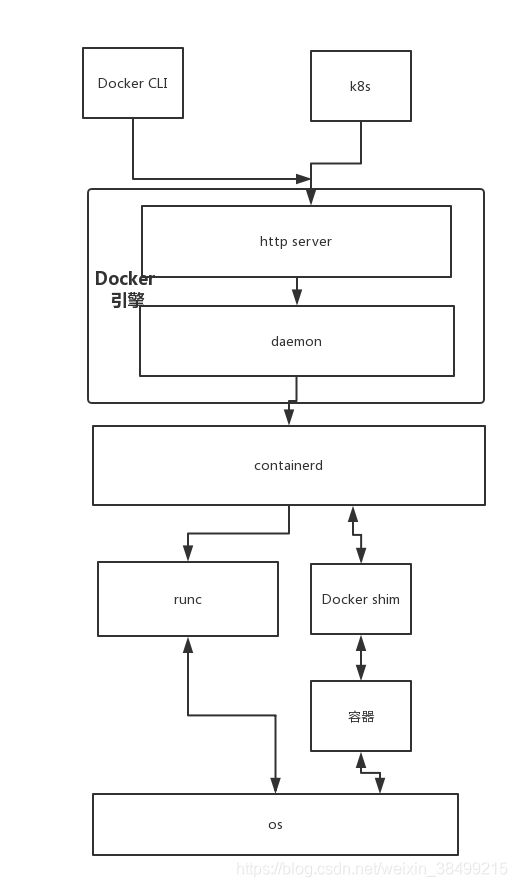
containerd和docker关系
containerd是从docker分离出来的容器执行引擎,本质上是一个Daemon进程.
Docker包括containerd,containerd专注于运行时的容器管理,而Docker除了容器管理还有镜像构建的功能.
containerd,OCI和runC之间的关系
OCI:标准化的容器规范,包括运行时规范和镜像规范
runC是基于这个规范的一个参考实现
containerd比runC层次更高,containerd可以使用runC来直接启动容器.
containerd和容器编排系统的关系
K8s的Kubelet组件是负责容器的执行.
K8s之前可以直接使用Docker,也可以直接使用Containerd,而且在Containerd1.1 之后,kubelet可以直接通过CRI(容器运行时接口)
和containerd打交道
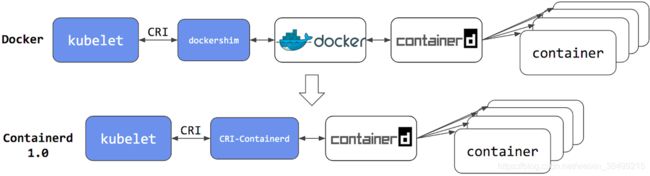
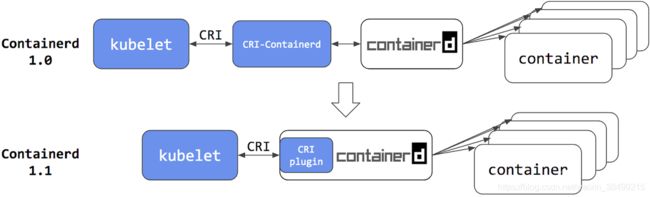
总结
namespace实现了访问隔离,原理是针对一类资源做抽象,并将其封装在一起给一个容器使用,所以每个容器都会对这类资源有不同的视角,而且他们彼此之间不可见.
cgroup实现了资源控制.原理是把一组进程放在一个控制组里面,然后通过给这个控制组分配资源而实现给这一组进程分配资源的目的.
Docker的容器=镜像(只读层) + 读写层
分别对应AUFS/OverlayFS,在实现容器之间文件系统的隔离同时,也节省了大量的系统资源.
runC创建容器的进程:
ref
揭秘容器进行时
Docker存储驱动
云原生公开课
https://www.jianshu.com/p/d9bf66841a1e
https://my.oschina.net/u/2306127/blog/1600270