巨杉内核笔记 | 会话(Session)
SequoiaDB 巨杉数据库是一款金融级分布式关系型数据库,坚持从零开始打造分布式开源数据库引擎。“内核笔记系列”旨在分享交流 SequoiaDB 巨杉数据库引擎的设计思路和代码解析,帮助社区用户深入理解 SequoiaDB 的实现原理,共建开源开放的数据库技术生态。
01 基本概念
会话与连接是两个容易混淆的概念。会话(Session) 指是通信双方从开始通信到通信结束期间的一个上下文(Context)。这个上下文是一段位于服务器端的内存,记录了本次连接的客户端机器,通过哪个应用程序和哪个用户登录等信息。而连接是指从客户端到数据库实例的一条物理路径。连接可以在网络上建立,也可以在本机通过IPC机制建立。通常会在客户端进程与一个专用服务器或一个调度器之间建立连接。
02 SequoiaDB 中的会话设计
分布式数据库 SequoiaDB 的集群通常由数据节点、协调节点和编目节点组成,集群内的不同节点间存在多种类型的连接。因此 SequoiaDB 中存在多种会话,且不同的会话对应不同的服务。会话的主要任务是处理通信的对端发来的请求。
集群中典型的会话结构如下图。
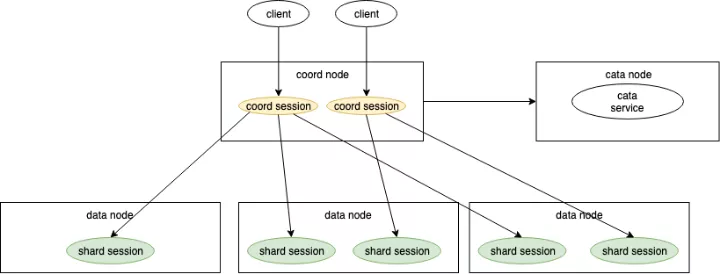
协调节点监听客户端发起的连接请求,连接建立后创建一个 coord session,即协调节点会话,之后便由这个会话处理对应的客户端发起的所有请求。coord session 在接收到客户端发来的处理请求后,会结合编目信息进行分析,确认需要下发到哪些节点去执行,可能会发送给编目节点、一个或多个数据节点。数据节点在接收到协调节点发来的消息时,会创建一个 shard session 来处理请求,执行指定的操作,并返回数据。
03 通信平面
SequoiaDB 集群内的节点间存在多个通信通道,不同类型的节点提供不同的服务。为了保证这些服务各自能够正常工作,SequoiaDB 的节点提供了多个通信平面。简单来说,一个通信平面对应一个服务端口,不同的端口提供不同类型的服务,这也是为什么在安装 SequoiaDB 时,要求预留一定范围内的端口号的原因。
SequoiaDB 中当前提供了如下几个通信平面:
-
local 平面(local service): 使用节点配置文件中指定的基础服务端口号 svcname
-
repl 平面(repl service): 使用端口号svcname+1
-
shard 平面(shard service): 使用端口号svcname+2
-
cat 平面(cat service): 使用端口号svcname+3
-
rest 平面(rest service): 使用端口号svcname+4
-
om 平面(om service): 使用端口号svcname+5
04 本地会话
本地会话在直连节点(即配置 svcname)时创建。直连的含义相对宽泛,指的是连接任意节点的本地服务端口。客户端连接到协调节点时,会在协调节点上创建本地会话。当本地端口上的监听接收到新的连接请求时,会创建一个新的会话(内存结构)及一个服务线程(执行单元),并将它们绑定(attach)起来。后续客户端将会直接与这个新的服务线程进行交互。
代码导读
SequoiaDB 中各类型的会话继承关系如下图所示。
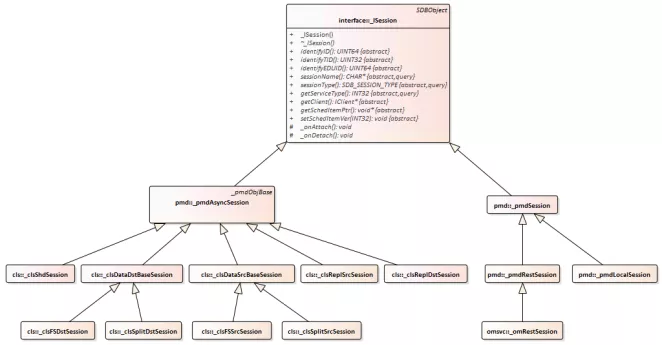
从图中可以看到,本地会话、增量/全量同步会话、复制会话等,都是继承自同一个基类 _ISession。下面将会结合组网对其中几个关键的会话进行介绍,主要是会话建立/销毁的时机、会话的结构、操作等。
本地会话对应数据结构是类 _pmdLocalSession,线程的主函数是 _pmdLocalSession::run(),会话线程启动后,就在这个函数里循环,接收及处理消息,直到会话需要结束时退出该循环。
本地会话能绑定不同的 processor 以执行不同的处理流程。对于协调节点,绑定的是 _pmdCoordProcessor。对于编目节点和数据节点,绑定的是 _pmdDataProcessor。对于协调节点,会先调用 _pmdCoordProcessor 的接口进行消息处理,在无法识别请求类型时,则会再次调用 _pmdDataProcessor 的接口进行处理。

05 同步(或复制)会话 Repl Session
分区组内的节点之间,通过同步动作来保证数据的一致性。同步分为两种,一种是正常运行状态下的增量同步,一种是异常情况下的全量同步。同步是通过对应的同步会话与同步线程来处理的,它涉及到两个节点,在数据生产方称为源端,在数据消费方称为目标端。由于只有数据节点和编目节点上会进行数据复制,所以只有在这两种类型的节点上,才存在同步会话。
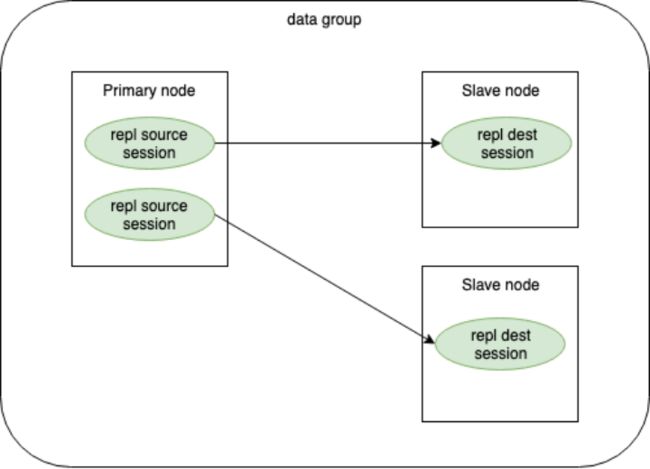
1)增量同步会话
增量同步会话分为增量同步源端会话和目标端会话,且存在于复制组正常运行期间。在数据节点和编目节点的启动过程中,主节点或从节点都会开启增量同步的监听。同时,它也会主动启动一个增量复制目标端会话,并向它选定的源端发送同步请求。源端节点上会被动创建一个增量同步源端会话,这两个会话后续会开始进行交互,以完成数据同步。
2)全量同步会话
全量同步会话存在于全量同步期间,在集群正常运行期间及全量同步完成后不存在。与增量同步会话一样,全量同步会话也分为源端和目标端。
需要全量同步的场景有三种:
-
备节点的重放速度跟不上主节点,主节点上复制日志绕接,导致备节点还未获取到的复制日志被覆盖,备节点无法继续增量同步
-
节点异常重启,启动后节点根据读取到的异常启动状态决定全量同步
-
节点正常停止后正常重启,但停止时间较长,期间其它节点上的日志已经发生了绕接
而无论是上述哪种情况,都会先发生增量复制会话。当这些原因导致增量同步无法继续进行的时候,目标节点上会主动创建一个全量同步会话(以及对应的线程),并退出当前的增量复制线程。当全量同步会话启动时,会向源端发送一个全量同步开始的消息。此时源端上会被动创建一个全量同步源端会话。至此,全量同步的会话创建完成,后续这两个会话之间会开始进行交互,完成数据同步。
代码导读
-
四种会话对应的类为: _clsReplSrcSession, _clsReplDstSession, _clsFSSrcSession, _clsFSDstSession。
-
同步相关的会话都是异步会话,上述四种会话使用同一个会话管理器:_clsReplSessionMgr 来进行管理。
-
异步会话响应的消息类型及对应的处理函数,一般在对应的类中通过 OBJ_MSG_MAP 等宏进行定义,请参考代码。
06 会话的查看
用户可通过 db.snapshot ( SDB_SNAP_SESSIONS ) 命令列出当前数据库节点中的所有会话,或通过 db.snapshot ( SDB_SNAP_SESSIONS_CURRENT ) 命令列出当前数据库节点中的当前会话。
代码导读
session 的导出动作在类 _monSessionFetcher 类中实现,并在 init() 函数中准备数据。用户可选择查看当前会话 (使用当前线程的 eduCB 接口导出) 或所有会话 (使用 _pmdEDUMgr的接口导出)。 在准备好数据后,由上层统一的 context 框架调用该类的 fetch 接口获取数据。