OpenGL中的异步缓存传输Asynchronous Buffer Transfers
本文介绍在OpenGL中buffer的异步传输,翻译、摘抄自OpenGL Insights Chapter 28。
目前更新到第三节,待续(后面还没看懂)
Terminology
为了后文表述方便,现说明一些要使用术语:
1. GPU被称作device
2. 当调用OpenGL functions,相关命令会放入一个队列队列异步地依次执行,这个队列叫device command queue
3. uploading:数据从CPU memory 向device memory传送
4. downloading:数据从从device memory 向CPU memory传送
5. pinned memory(page-lockedmemory) :在 main RAM 中能直接(通过PCI express bus)被device访问的部分
Buffer Object
- 从数据传送的角度看,各buffer object targets(如GL_ARRAY_BUFFER、GL_ELEMENT_ARRAY BUFFER、GL_PIXEL_PACK_BUFFER)都是等价的,因此下文中的描述适用于任何buffer object targets。
- Buffer objects是CPU或device中线性的内存区域,用来存储顶点数据等。
Memory Transfers
数据传送的两种方式:
1. 使用glBufferData或glBufferSubData
2. 使用glMapBuffer和glUnmapBuffer
通过第一种方式的过程如Figure 28.1。首先user data被传送到pinned memory中。然后函数glBufferData执行完毕并返回,同时开始DMA传送。
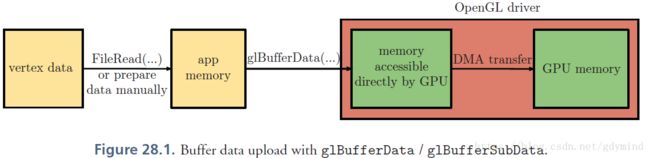
第二种方式更高效,其过程如Figure 28.2。调用glMapBuffer可以获取到指向内部驱动器memory的指针(一般是pinned memory)。使用该指针可以进行存取操作。调用glUnmapBuffer后该指针失效。
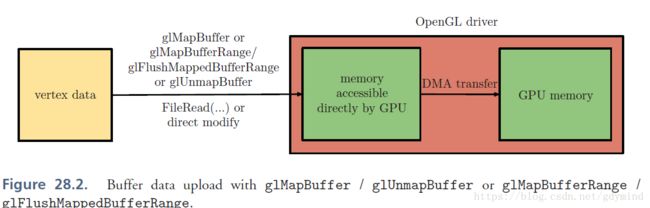
glMapBuffer还有glMapBufferRange和glFlushMappedBufferRange这两个变种,它们的参数更多,控制能力更强。其中glMapBufferRange可用于只有部分data改变的情况。
小技巧:我们可以创建一个两倍大的buffer,前一半用于rendering,后一半用于updating,当upload完成时两部分角色互换。
Usage Hints
OpenGL drivers可以将数据存储在CPU memory 或device memory中。其中CPU memory又可分为page-locked (pinned) memory和paged memory。前者可直接被device访问,但不能传送回disk。后者也能被device 访问,但比较慢。我们可以使用usage hint建议driver怎样放数据(不过有的driver有可能不听你的==),举例Table 28.1
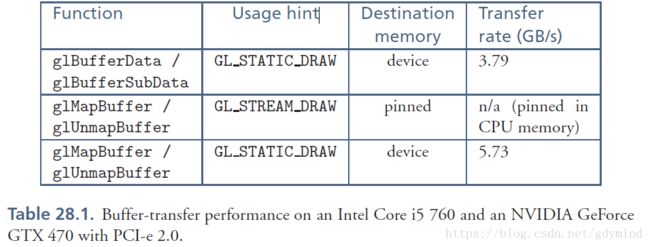
NVIDIA和AMD会根据usage hint决定buffer,怎么放,但之后会根据buffer的实际使用情况进行启发式调整。但也有例外,如在NVIDIA with the Forceware 285 drivers中,glMapBuffer会调整,而glMapBufferRange则完全按照usage hint执行。
不同函数数据传输速度也不同,一般glMapBufferRange性能最高。
Pinned memory中的数据使用时不需要传送到device memory(不过driver也可能这么去做==),因为它直接 PCI-e 传送数据的速度比device进行render的速度快得多。
Implicit Synchronization
一个OpenGL call的完成不代表立即执行,大部分命令只是被放入device command queue中等待依次执行。

使用glBufferSubData或glMapBuffer[Range]可能修改正在使用的数据。driver会隐式的进行同步防止出现问题。这个过程可能暂时阻塞一些函数的执行,降低一些性能。例子间Figure 28.3。
Synchronization Primitives
OpenGL提供了用于同步的sync objects。sync objects就像device command queue中的fence一样,当device到达那个位置时,sync objects就会变成有信号(signaled)状态。
函数glClientWaitSync用于阻塞CPU,直到对应sync object变成signaled状态。而glWaitSync阻塞的是device。
Upload
先说明一个术语streaming,它数据非常频繁地upload到到device(比如每帧都传)。在streaming任务中要特别注意避免implicit synchronization,我们可以采取下面一些方法:
- 对buffer objdect进行round-robin,交替、轮流使用
- 使用glBufferData或者glMapBufferRanges进行buffer respecification(orphaning)
- 使用glMapBufferRange 和glFenceSync/glClientWaitSync完全手动同步
下面分别介绍这三个方法
Round-Robin Fashion (Multiple Buffer Objects)
在device在render buffer N−1的时间更新、传送buffer N,见Figure 28.4

Buffer Respecification (Orphaning)
Buffer respecification与Round-Robin差不多,但在driver内部进行。
*待填坑
Summary
本文介绍了CPU与device间数据传送的问题,介绍了三种对数据在CPU 和device间stream的方法。笔者推荐使用使用一个standard worker thread和若干使用GL_MAP_UNSYCHRONIZED_BIT的buffers。