视觉目标跟踪是计算机视觉中的一个重要研究方向,有着广泛的应用,如:视频监控,人机交互, 无人驾驶等。过去二三十年视觉目标跟踪技术取得了长足的进步,特别是最近两年利用深度学习的目标跟踪方法取得了令人满意的效果,使目标跟踪技术获得了突破性的进展。本文旨在简要介绍:目标跟踪的基本流程与框架,目标跟踪存在的挑战,目标跟踪相关方法,以及目标跟踪最新的进展等,希望通过这篇文章能让读者对视觉目标跟踪领域有一个较为全面的认识。
1.视觉目标跟踪基本流程与框架
视觉目标(单目标)跟踪任务就是在给定某视频序列初始帧的目标大小与位置的情况下,预测后续帧中该目标的大小与位置。这一基本任务流程可以按如下的框架划分:

输入初始化目标框,在下一帧中产生众多候选框(Motion Model),提取这些候选框的特征(Feature Extractor),然后对这些候选框评分(Observation Model),最后在这些评分中找一个得分最高的候选框作为预测的目标(Prediction A),或者对多个预测值进行融合(Ensemble)得到更优的预测目标。
根据如上的框架,我们可以把目标跟踪划分为5项主要的研究内容. (1)运动模型:如何产生众多的候选样本。(2)特征提取:利用何种特征表示目标。(3)观测模型:如何为众多候选样本进行评分。(4)模型更新:如何更新观测模型使其适应目标的变化。(5)集成方法:如何融合多个决策获得一个更优的决策结果。下面分别简要介绍这5项研究内容。
运动模型(Motion Model):生成候选样本的速度与质量直接决定了跟踪系统表现的优劣。常用的有两种方法:粒子滤波(Particle Filter)和滑动窗口(Sliding Window)。粒子滤波是一种序贯贝叶斯推断方法,通过递归的方式推断目标的隐含状态。而滑动窗口是一种穷举搜索方法,它列出目标附近的所有可能的样本作为候选样本。
特征提取(Feature Extractor): 鉴别性的特征表示是目标跟踪的关键之一。常用的特征被分为两种类型:手工设计的特征(Hand-crafted feature)和深度特征(Deep feature)。常用的手工设计的特征有灰度特征(Gray),方向梯度直方图(HOG),哈尔特征(Haar-like),尺度不变特征(SIFT)等。与人为设计的特征不同,深度特征是通过大量的训练样本学习出来的特征,它比手工设计的特征更具有鉴别性。因此,利用深度特征的跟踪方法通常很轻松就能获得一个不错的效果。
观测模型(Observation Model):大多数的跟踪方法主要集中在这一块的设计上。根据不同的思路,观测模型可分为两类:生成式模型(Generative Model)和判别式模型(Discriminative Model). 生成式模型通常寻找与目标模板最相似的候选作为跟踪结果,这一过程可以视为模板匹配。常用的理论方法包括:子空间,稀疏表示,字典学习等。而判别式模型通过训练一个分类器去区分目标与背景,选择置信度最高的候选样本作为预测结果。判别式方法已经成为目标跟踪中的主流方法,因为有大量的机器学习方法可以利用。常用的理论方法包括:逻辑回归,岭回归,支持向量机,多示例学习,相关滤波等。
模型更新(Model Update): 模型更新主要是更新观测模型,以适应目标表观的变化,防止跟踪过程发生漂移。模型更新没有一个统一的标准,通常认为目标的表观连续变化,所以常常会每一帧都更新一次模型。但也有人认为目标过去的表观对跟踪很重要,连续更新可能会丢失过去的表观信息,引入过多的噪音,因此利用长短期更新相结合的方式来解决这一问题。
集成方法(Ensemble Method): 集成方法有利于提高模型的预测精度,也常常被视为一种提高跟踪准确率的有效手段。可以把集成方法笼统的划分为两类:在多个预测结果中选一个最好的,或是利用所有的预测加权平均。
2.视觉目标跟踪面临的挑战
视觉运动目标跟踪是一个极具挑战性的任务,因为对于运动目标而言,其运动的场景非常复杂并且经常发生变化,或是目标本身也会不断变化。那么如何在复杂场景中识别并跟踪不断变化的目标就成为一个挑战性的任务。如下图我们列出了目标跟踪中几个主要的挑战因素:


其中遮挡(Occlusion)是目标跟踪中最常见的挑战因素之一,遮挡又分为部分遮挡(Partial Occlusion)和完全遮挡(Full Occlusion)。解决部分遮挡通常有两种思路:(1)利用检测机制判断目标是否被遮挡,从而决定是否更新模板,保证模板对遮挡的鲁棒性。(2)把目标分成多个块,利用没有被遮挡的块进行有效的跟踪。对于目标被完全遮挡的情况,当前也并没有有效的方法能够完全解决。
形变(Deformation)也是目标跟踪中的一大难题,目标表观的不断变化,通常导致跟踪发生漂移(Drift)。解决漂移问题常用的方法是更新目标的表观模型,使其适应表观的变化,那么模型更新方法则成为了关键。什么时候更新,更新的频率多大是模型更新需要关注的问题。
背景杂斑(Background Clutter)指得是要跟踪的目标周围有非常相似的目标对跟踪造成了干扰。解决这类问题常用的手段是利用目标的运动信息,预测运动的大致轨迹,防止跟踪器跟踪到相似的其他目标上,或是利用目标周围的大量样本框对分类器进行更新训练,提高分类器对背景与目标的辨别能力。
尺度变换(Scale Variation)是目标在运动过程中的由远及近或由近及远而产生的尺度大小变化的现象。预测目标框的大小也是目标跟踪中的一项挑战,如何又快又准确的预测出目标的尺度变化系数直接影响了跟踪的准确率。通常的做法有:在运动模型产生候选样本的时候,生成大量尺度大小不一的候选框,或是在多个不同尺度目标上进行目标跟踪,产生多个预测结果,选择其中最优的作为最后的预测目标。
当然,除了上述几个常见的挑战外,还有一些其他的挑战性因素:光照(illumination),低分辨率(Low Resolution),运动模糊(Motion Blur),快速运动(Fast Motion),超出视野(Out of View),旋转(Rotation)等。所有的这些挑战因数共同决定了目标跟踪是一项极为复杂的任务。更多信息请参考http://cvlab.hanyang.ac.kr/tracker_benchmark/datasets.html。
3.视觉目标跟踪方法
视觉目标跟踪方法根据观测模型是生成式模型或判别式模型可以被分为生成式方法(Generative Method)和判别式方法(Discriminative Method)。前几年最火的生成式跟踪方法大概是稀疏编码(Sparse Coding)了, 而近来判别式跟踪方法逐渐占据了主流地位,以相关滤波(Correlation Filter)和深度学习(Deep Learning)为代表的判别式方法也取得了令人满意的效果。下面我们分别简要概括这几种方法的大体思想和其中的一些具体的跟踪方法。
稀疏表示(Sparse Representation):给定一组过完备字典,将输入信号用这组过完备字典线性表示,对线性表示的系数做一个稀疏性的约束(即使得系数向量的分量尽可能多的为0),那么这一过程就称为稀疏表示。基于稀疏表示的目标跟踪方法则将跟踪问题转化为稀疏逼近问题来求解。如稀疏跟踪的开山之作L1Tracker, 认为候选样本可以被稀疏的表示通过目标模板和琐碎模板,而一个好的候选样本应该拥有更稀疏的系数向量。稀疏性可通过解决一个L1正则化的最小二乘优化问题获得,最后将与目标模板拥有最小重构误差的候选样本作为跟踪结果。L1Tracker中利用琐碎模板处理遮挡,利用对稀疏系数的非负约束解决背景杂斑问题。随后在L1Tracker基础上的改进则有很多,比较有代表性的有ALSA,L1APG等。
相关滤波(Correlation Filter):相关滤波源于信号处理领域,相关性用于表示两个信号之间的相似程度,通常用卷积表示相关操作。那么基于相关滤波的跟踪方法的基本思想就是,寻找一个滤波模板,让下一帧的图像与我们的滤波模板做卷积操作,响应最大的区域则是预测的目标。根据这一思想先后提出了大量的基于相关滤波的方法,如最早的平方误差最小输出和(MOSSE)利用的就是最朴素的相关滤波思想的跟踪方法。随后基于MOSSE有了很多相关的改进,如引入核方法(Kernel Method)的CSK,KCF等都取得了很好的效果,特别是利用循环矩阵计算的KCF,跟踪速度惊人。在KCF的基础上又发展了一系列的方法用于处理各种挑战。如:DSST可以处理尺度变化,基于分块的(Reliable Patches)相关滤波方法可处理遮挡等。但是所有上述的基于相关滤波的方法都受到边界效应(Boundary Effect)的影响。为了克服这个问题SRDCF应运而生,SRDCF利用空间正则化惩罚了相关滤波系数获得了可与深度学习跟踪方法相比的结果。
深度学习(CNN-Based):因为深度特征对目标拥有强大的表示能力,深度学习在计算机视觉的其他领域,如:检测,人脸识别中已经展现出巨大的潜力。但早前两年,深度学习在目标跟踪领域的应用并不顺利,因为目标跟踪任务的特殊性,只有初始帧的图片数据可以利用,因此缺乏大量的数据供神经网络学习。只到研究人员把在分类图像数据集上训练的卷积神经网络迁移到目标跟踪中来,基于深度学习的目标跟踪方法才得到充分的发展。如:CNN-SVM利用在ImageNet分类数据集上训练的卷积神经网络提取目标的特征,再利用传统的SVM方法做跟踪。与CNN-SVM提取最后一层的深度特征不同的是,FCN利用了目标的两个卷积层的特征构造了可以选择特征图的网络,这种方法比只利用最后的全连接层的CNN-SVM效果有些许的提升。随后HCF, HDT等方法则更加充分的利用了卷积神经网络各层的卷积特征,这些方法在相关滤波的基础上结合多层次卷积特征进一步的提升了跟踪效果。然而,跟踪任务与分类任务始终是不同的,分类任务关心的是区分类间差异,忽视类内的区别。目标跟踪任务关心的则是区分特定目标与背景,抑制同类目标。两个任务有着本质的区别,因此在分类数据集上预训练的网络可能并不完全适用于目标跟踪任务。于是,Nam设计了一个专门在跟踪视频序列上训练的多域(Multi-Domain)卷积神经网络(MDNet),结果取得了VOT2015比赛的第一名。但是MDNet在标准集上进行训练多少有一点过拟合的嫌疑,于是VOT2016比赛中禁止在标准跟踪数据集上进行训练。2016年SRDCF的作者继续发力,也利用了卷积神经网络提取目标特征然后结合相关滤波提出了C-COT的跟踪方法取得了VOT2016的冠军。
4.视觉目标跟踪最新进展
目标跟踪最近几年发展迅速,以基于相关滤波(Correlation Filter)和卷积神经网络(CNN)的跟踪方法已经占据了目标跟踪的大半江山。如下图给出的2014-2017年以来表现排名靠前的一些跟踪方法。
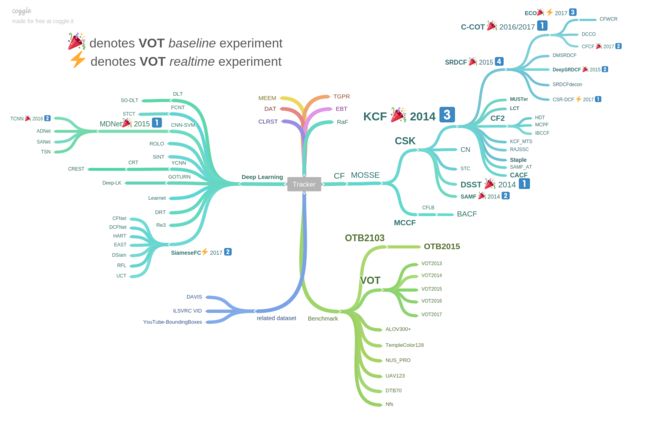
可以看到前三名的方法不是基于相关滤波的方法就是基于卷积神经网络的方法,或是两者结合的方法。比如ECCV2016的C-COT就是在相关滤波的基础上结合卷积神经网络的杰作。下图给出这些方法在标准跟踪数据集OTB2013上的跟踪结果:

可以看到基于卷积神经网络的方法取得了惊人的突破。预计未来两年相关滤波和卷积神经网络将仍然会是目标跟踪领域的主角。