Python基础语法笔记整理
文章目录
- 一. 常用函数
-
- choice()
- combinations()
- count()
- Counter()
- defaultdict()
- deque()
- enumerate()
- eval()
- filter(), zip(), map()
- format()
- formkeys()
- hash()
- heapq()
- isinstance()
- join()
- ord()
- OrderedDict()
- permutations()
- randint()
- reduce()
- replace()
- split()
- strip()
- setdefault()
- 二. 基本概念
-
- 元组
- r+ 字符串 --> 使原生失效
- set 支持一个参数
- dict 修改增加键值对
-
- 字典遍历所有键-值对
- 字典按键值排序
- Python命名规范
- 面对对象的特征
- 类、类对象、实例对象
- 类的静态属性
- 魔法方法
-
- Python序列的三大容器
- 生成器
- 异常
- os模块
- 命名空间的冲突
- 包
- 日志
- 多线程
- 三. 方法技巧
-
- requirements.txt
- 字符串
-
- 字符串格式化
- 正则表达式
- 装饰器
- 四. 编程技巧
-
- 求数组中相同元素
- 元素逆置
- 一维数组换行打印/或变多维数组
- 随机生成指定类型的随机数据
- 两个不同长度数组间元素形成映射
- 五. 数据结构
-
- 字典树segmentTree
一. 常用函数
choice()
choice() 方法返回一个列表,元组或字符串的随机项。
>>> print("choice([1,2,3,5,9]): ", random.choice([1,2,3,5,9]))
choice([1,2,3,5,9]): 2 #从列表中返回一个随机数
>>> print("choice('A String'): ", random.choice('A String'))
choice('A String'): S #从字符串中返回一个随机字符:S
创建随机密码组合:
import string #string module里包含了阿拉伯数字,ascii码,特殊符号
import random #需要利用到choice
n = int(input('请输入要求的密码长度'))
w = string.digits + string.ascii_letters + string.punctuation #构建密码池
password = "" #命名一个字符串
for i in range(0,n): #for loop 指定重复次数
password = password + random.choice(w) #从密码池中随机挑选内容构建密码
print(password) #输出密码
combinations()
combinations(iterable,r)创建一个迭代器,返回iterable中所有长度为r的子序列,返回的子序列中的项按输入iterable中的顺序排序。类似permutations()
note: 不带重复
for i in combinations([1, 2, 3], 2):
print i
(1, 2)
(1, 3)
(2, 3)
count()
该方法返回子字符串在字符串中出现的次数。
str.count(sub, start= 0,end=len(string))
- sub – 搜索的子字符串
- start – 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
- end – 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
Counter()
Counter一种继承于dict用于统计元素个数的数据结构,也称为bag 或 multiset.
from collections import Counter
c = Counter([1,3,2,3,4,2,2]) # 统计每个元素的出现次数
print(c) # Counter({1: 1, 3: 2, 2: 3, 4: 1})
# 除此之外,还可以统计最常见的项
# 如统计最常见的项,返回元素及其次数的元组
c.most_common(1) [(2, 3),(3,2)]
使用场景 基本的
dict能解决的问题就不要用Counter,但如遇到统计元素出现频次的场景,就不要自己去用dict实现了,果断选用Counter。
实现原理Counter实现基于dict,它将元素存储于keys上,出现次数为values.
Leetcode347中求数组中前K个高频元素,可直接用Counter解决。
def topKFrequent(self, nums:List[int], k:int) -> List[int]:
return [i[0] for i in Counter(nums).most_common(k)]
defaultdict()
Python中通过Key访问字典,当Key不存在时,会引发
KeyError异常。为了避免这种情况的发生,可以使用collections类中的defaultdict()方法来为字典提供默认值。
语法格式:collections.defaultdict([default_factory[, …]])
该函数返回一个类似字典的对象。defaultdict是Python内建字典类(dict)的一个子类。
参考链接
ss = ['yellow', 'blue','yellow','blue','red']
d = {
}
for k,v in enumerate(ss):
if v in d:
d[v].append(k)
else:
d[v]=[k]
print(d) #{'yellow': [0, 2], 'blue': [1, 3], 'red': [4]}
from collections import defaultdict
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d = defaultdict(list)
print(d) #defaultdict(, {})
for k, v in s:
d[k].append(v)
print(d) # defaultdict(, {'yellow': [1, 3], 'blue': [2, 4], 'red': [1]})
a = sorted(d.items())
print(a) # [('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]
setdefault(),需提供两个参数,第一个参数是键值,第二个参数是默认值,每次调用都有一个返回值,如果字典中不存在该键则返回默认值,如果存在该键则返回该值,利用返回值可再次修改代码。
words = ['hello', 'world', 'nice', 'world']
counter = dict()
for kw in words:
# counter.setdefault(kw, 0)
# counter[kw] += 1
counter[kw] = counter.setdefault(kw, 0) + 1
print(counter) # {'hello': 1, 'world': 2, 'nice': 1}
deque()
deque双端队列,基于list优化了列表两端的增删数据操作。
from collections import deque
d = deque([3,2,4,0])
d.popleft() # 左侧移除元素,O(1)时间复杂度 >>> 3
d.appendleft(3) # 左侧添加元素,O(1)时间复杂度
print(d) #deque([3, 2, 4, 0])
使用场景
list左侧添加删除元素的时间复杂度都为O(n),所以在Python模拟队列时切忌使用list,相反使用deque双端队列非常适合频繁在列表两端操作的场景。但是,加强版的deque牺牲了空间复杂度
enumerate()
返回 enumerate(枚举) 对象。
enumerate(sequence, [start=0])
- sequence – 一个序列、迭代器或其他支持迭代对象。
- start – 下标起始位置。
>>> seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
eval()
函数用来执行一个字符串表达式,并返回表达式的值。
eval(expression[, globals[, locals]])
- expression – 表达式。
- globals – 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
>>> x = 7
>>> eval( '3 * x' )
21
>>> eval('pow(2,2)')
48
filter(), zip(), map()
filter()函数是一个过滤器
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
filter()接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True的元素放到新列表中。
import math
def is_sqr(x):
return math.sqrt(x) % 1 == 0 #完全平方数
newlist = filter(is_sqr, range(1, 101))
print(newlist)
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
使用zip()会将两数以元组的形式绑定在一块
>>> list(zip([1, 3, 5, 7, 9], [2, 4, 6, 8, 10]))
[(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]
>>> list(map(lambda x, y : [x, y], [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]))
[[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]

format()
>>> "{} {}".format("hello","world") #不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello","world") #设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello","world") #设置指定位置
'world hello world'
formkeys()
fromkeys方法是直接创建一个新的字典,不要试图使用它来修改一个原有的字典,因为它会直接无情的用把整个字典给覆盖掉.
hash()
hash() 函数的用途
hash()函数的对象字符不管有多长,返回的 hash值都是固定长度的,也用于校验程序在传输过程中是否被第三方(木马)修改,如果程序(字符)在传输过程中被修改hash值即发生变化,如果没有被修改,则hash值和原始的hash值吻合,只要验证 hash 值是否匹配即可验证程序是否带木马(病毒)。
heapq()
基于list优化的一个数据结构:
堆队列,也称为优先队列。堆队列特点在于最小的元素总是在根结点。
import heapq
In [1]: a = [3,1,4,5,2,1]
In [2]: heapq.heapify(a) # 对a建堆,建堆后完成对a的就地排序
In [3]: a[0] # a[0]一定是最小元素
In [4]: a
Out[4]: [1, 1, 3, 5, 2, 4]
In [5]: heapq.nlargest(3,a) # a的前3个最大元素
Out[5]: [5, 4, 3]
In [5]: heapq.nsmallest(3,a) # a的前3个最小元素
Out[5]: [1, 1, 2]
基本原理堆是一个二叉树,它的每个父节点的值都只会小于或大于所有孩子节点(的值),原理与堆排序极为相似
isinstance()
判断
object是否为classinfo的实例,是返回true
>>> class Student():
def __init__(self,id,name):
self.id = id
self.name = name
>>> xiaoming = Student('001','xiaoming')
>>> isinstance(xiaoming,Student)
True
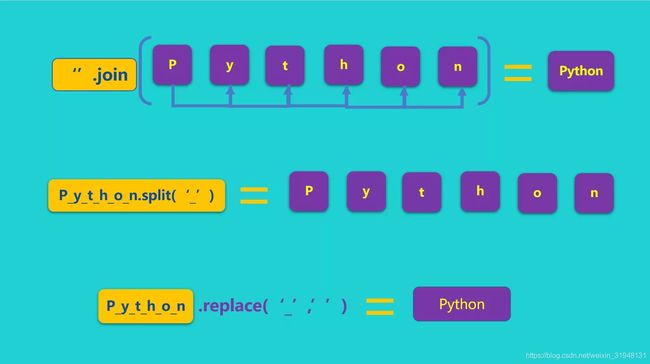
join()
str.join(sequence)
- sequence – 要连接的元素序列。
- 返回通过指定字符连接序列中元素后生成的新字符串
>>> str = '-'
>>> seq = ("a","b","c"); #字符串序列
>>> print(str.join(seq))
a-b-c
ord()
计算出字母的ASCII值
>>> ord('a')
97
OrderedDict()
继承于dict,能确保keys值按照顺序取出来的数据结构
from collections import OrderedDict
od = OrderedDict({
'c':3,'a':1,'b':2})
for k,v in od.items():
print(k,v)
c 3
a 1
b 2
permutations()
permutations(p[ ] ,r)返回p数组中任意取r个元素做排列的元组的迭代器
for i in permutations([1, 2, 3], 3):
print(i)
(1, 2, 3)
(1, 3, 2)
(2, 1, 3)
(2, 3, 1)
(3, 1, 2)
(3, 2, 1)
randint()
random.randint(a,b)
函数返回数字 N ,N 为 a 到 b 之间的数字(a <= N <= b),包含 a 和 b。 随机数。
reduce()
reduce函数,也是类似的。它的作用是先对序列中的第 1、2 个元素进行操作,得到的结果再与第三个数据用lambda函数运算,将其得到的结果再与第四个元素进行运算,以此类推下去直到后面没有元素了。

replace()
str.replace(old, new[, max])
- old – 将被替换的子字符串。
- new – 新字符串,用于替换old子字符串。
- max – 可选字符串, 替换不超过 max 次
返回字符串中的
old(旧字符串) 替换成
new(新字符串)后生成的新字符串,如果指定第三个参数max,则替换不超过max次。
split()
str.split(str="", num=string.count(str))
- str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
- num – 分割次数。默认为
-1, 即分隔所有。
split()通过指定分隔符对字符串进行切片,如果参数 num有指定值,则仅分隔 num+1个子字符串。
>>> str = "this is string example .... wow!!!"
>>> print(str.split( )) #以空格为分隔符
['this', 'is', 'string', 'example....wow!!!']
>>> print(str.split('i', 1)) #以 i 为分隔符
['th', 's is string example....wow!!!']
>>> print(str.split('w')) #以 w 为分隔符
['this is string example....', 'o', '!!!']
strip()
strip()返回移除字符串头尾指定的字符序列生成的新字符串。
>>> str = "*****this is **string** example .... wow!!!*****"
>>> print(str.split('*')) #指定字符串*
this is **string** example .... wow!!!
setdefault()
dict.setdefault(key, default=None)
- key – 查找的键值。
- default – 键不存在时,设置的默认键值。
如果 key在 字典中,返回对应的值。如果不在字典中,则插入key及设置的默认值 default,并返回 default ,default 默认值为None。
二. 基本概念
元组
元组: 封闭的列表,一旦定义,就不可改变(不能添加、删除或修改)。
r+ 字符串 --> 使原生失效
>>> print("ab\ncd")
ab
cd
>>> print(r"ab\ncd") #原生失效
ab\ncd
set 支持一个参数
>>> set(("Tony", "Jack", "Robbin")) #双括号
{
'Tony', 'Jack', 'Robbin'}
dict 修改增加键值对
>>> d[3] = "test" #有就修改key为3,没有就增加键值对
>>> d.setdefault(3, "test") #同上
字典遍历所有键-值对
uers={
"Kobe":24,"James":23}
for k, v in uers.items():
字典按键值排序
X[1]根据 value排序,X[0]根据key排序
List1 = sorted(dict1.items(), key=lambda x: x[1], reverse=True)
Python命名规范
类: 驼峰命名法
PythonMachineLearning
其他:包名,模块名,方法名,函数名,变量名 采用:python_machine_learning。
面对对象的特征
| 封装 | 对外部隐藏对象的工作细节 |
|---|---|
| 继承 | 子类自动共享父类之间数据和方法的机制 |
| 多态 | 可以对不同类的对象调用相同的方法,产生不同的结果 |
类、类对象、实例对象
首先要明白类、类对象、实例对象是三个不同的名词。
我们常说的类指的是类定义,由于“Python无处不对象”,所以当类定义完之后,自然就是类对象。在这个时候,你可以对类的属性(变量)进行直接访问(MyClass.name)
一个类可以实例化出无数的对象(实例对象),Python 为了区分是哪个实例对象调用了方法,于是要求方法必须绑定(通过self参数)才能调用。而未实例化的类对象直接调用方法,因为缺少self参数,所以就会报错。
类的静态属性
类的静态属性很简单,在类中直接定义的变量(没有
self.)就是静态属性。引用类的静态属性使用类名.属性名的形式。
静态方法是类的特殊方法,静态方法只需要在普通方法的前边加上@staticmethod修饰符即可。
静态方法最大的优点是:不会绑定到实例对象上,换而言之就是节省开销。
魔法方法
__name__()
所有模块都有一个 __name__ 属性,__name__ 的值取决于如何应用模块,在作为独立程序运行的时候,__name__ 属性的值是’__main__’,而作为模块导入的时候,这个值就是该模块的名字了。
__init__() 方法的返回值一定是None
| 魔法方法 | 含义 |
|---|---|
| __getattr__(self,name) | 定义当用户试图获取一个不存在的属性时的行为 |
| __getattrbute__(self,name) | 定义当该类的属性被访问时的行为 |
| __setattr__(self,name,value) | 定义当一个属性被设置时的行为 |
| __delattr__(self,name) | 定义当一个属性被删除时的行为 |
__mro__ (Class.__mro__) |
查看线性继承的继承顺序 |
Python序列的三大容器
python 基于序列的三大容器类指的是: 列表(List),元组(Tuple)和字符串(String)。
生成器
生成器的最大作用是: 使得函数可以“保留现场”,当下一次执行该函数是从上一次结束的地方开始,而不是重头再来。
将一个函数改造为生成器,说白了就是把return语句改为yield语句
生成器所能实现的任何操作都可以由迭代器来代替,生成器事实上就是基于迭代器来实现的,生成器只需要一个yield语句即可,但它内部会自动创建__iter__() 和 __next__() 方法
def func():
for i in range(5):
yield i
print("生成器后面的一行")
print('生成器外层')
A = func()
print(A) # 无输出
print(A.__next__()) # 测试结果
print(A.__next__()) #每一个__next__(),函数向下运行一次。
异常
try-except-finally: try语句块没有出现错误,跳过except语句直接执行finally语句;出现异常,先执行except内容,再执行finally语句内容。except语句中:较低的异常应优先抛出。raise语句: 自己抛出一个异常。
try:
print("hello Error")
except FileNotFoundError as e:
print("发生异常:文件未发现。 ")
print(e)
except ReferenceError as e:
print("发生异常。")
except Exception:
print("异常。")
else:
print("未发生异常")
finally:
print("无论是否发生异常,都会被执行")
os模块
test_file = input('请输入文件名:')
import os
if os.path.exists(test_file):
print('此文件已存在!')
命名空间的冲突
第二次导入的 b 模块把 a 模块的同名函数
function()给覆盖了,这就是所谓命名空间的冲突。所以,在项目中,特别是大型项目中我们应该避免使用from...import...,除非你非常明确不会造成命名冲突。
模块就是平时我们写的任何代码,然后保存的每一个
.py结尾的文件,都是一个独立的模块。
包
import urllib.request语句,那么这个urllib是一个包,Python把同类的模块放在一个文件夹中统一管理,这个文件夹称之为一个包。
Python区分一个文件是普通文件还是包,看文件夹中是否有__init__.py文件。
必须在包文件夹中创建一个__init__.py的模块文件,内容可以为空。可以是一个空文件,也可以写一些初始化代码。这个是 Python的规定,用来告诉 Python 将该目录当成一个包来处理。
日志
import logging
LOG_FORMAT = "%(asctime)s - %(levelname)s - %(message)s"
DATE_FORMAT = "%Y-%m-%d %H:%M:%S"
logger = logging.getLogger()
logger.setLevel("DEBUG") #设置等级,DEBUG较低,能同时显示出其他info,debug
# 文件处理器,输入到文件
file_handler = logging.FileHandler("my.log", mode='a', encoding="UTF-8")
# 流处理器,控制输入到控制台
steam_handler = logging.StreamHandler()
# 错误日志处理器,将错误日志单独输出到一个文件中
error_handler = logging.FileHandler("error.log", mode='a', encoding="UTF-8")
error_handler.setLevel(logging.ERROR)
# 将所有的处理器添加到logger中
logger.addHandler(file_handler)
logger.addHandler(steam_handler)
logger.addHandler(error_handler)
#格式化
formatter = logging.Formatter(fmt="%(asctime)s - %(levelname)s - %(message)s", datefmt="%Y-%m-%d %H:%M:%S")
#设置格式化器,需要针对每一个处理器进行分别设置
file_handler.setFormatter(formatter)
steam_handler.setFormatter(formatter)
error_handler.setFormatter(formatter)
# 过滤器
# my_filter = logging.Filter("日志")
# file_filter_log = file_handler.addFilter(my_filter)
# print(file_filter_log)
logger.info("日志打印")
logger.info("今日打印")
logger.error("这是一个错误日志")
多线程
场景描述:
有一个馒头店,生产馒头,每天销售
有一个生产者,就是馒头店老板,不停的生产馒头,但是当库存充足的时候就不生产了,等待消费
有一个消费者,去消费馒头,当没有馒头了就不能消费了。
import threading
import time
condition = threading.Condition() # 锁
products = 0
class Producer(threading.Thread):
def run(self):
while True:
global condition, products #全局变量
if condition.acquire(): # 锁上
if products <= 10:
products += 1
print("{}:{}库存不足商品数量小于等于0,努力生产商品,现在商品总数量是{}" \
.format("生产者", threading.currentThread().getName(), products))
condition.notify() # 唤醒一个等待的线程
else:
print("{}:{}库存不足商品数量大于10,休息一会,现在商品总数量是{}" \
.format("生产者", threading.currentThread().getName(), products))
condition.wait() # 线程等待
condition.release() # 释放锁
time.sleep(2)
class Consumer(threading.Thread):
def run(self):
global condition, products
while True:
if condition.acquire():
if products >= 1:
products -= 1
print("{}:{}->我消费了一件商品,现在的数量是{}" \
.format("消费者", threading.currentThread().getName(), products))
else:
print("{}:{}->没有库存了,现在的数量是{}" \
.format("消费者", threading.currentThread().getName(), products))
condition.wait()
condition.release() # 释放锁
time.sleep(2)
if __name__ == '__main__':
for i in range(3):
p = Producer()
p.start()
for i in range(10):
c = Consumer()
c.start()
三. 方法技巧
requirements.txt
在当前工作目录下,生成requirements.txt文件,环境所需要的依赖包。特别是工程代码中,运行他人的代码要注重所依赖的环境。
$ pip freeze > requirements.txt #生成环境中的python包
# 安装环境依赖的python包
$ pip install -r requirements.txt
字符串
list1=[int(i) for i in input('请输入一组数字,用空格隔开:').split(' ')]
字符串格式化
>>> print("23:{0}, {1}:James".format("Kobe", 23))
24:Kobe, 23:James
>>> print("{:,}".format(10241024)) # 以逗号分隔的数字格式
10,241,024
>>> print("{:.2%}".format(0.718)) # 百分比格式
71.80%
>>> print("{:.2e}".format(10241024)) # 指数记法
1.02e+07
正则表达式
- 元字符
| 元字符 | 匹配规则 |
|---|---|
. |
代表的是换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配任意的数字0-9 |
^ |
匹配字符串的开始 |
| $ | 匹配字符串的结束(Tab键匹配四个空格) |
| \W | 与\w相反 |
| \S | 与\s相反,匹配任意的非空白符 |
| \D | 与\d相反,匹配任意非十进制的数字,类似于[^0-9] |
- 限定符
| 限定符 | 匹配规则 |
|---|---|
* |
代表的是它前面的正则表达式重复0次或多次 |
+ |
重复1次或多次 |
? |
重复0次或1次 |
| {n} | 重复n次 |
| {n, } | 重复n次或多次, 最小重复n次 |
| {n, m} | 重复n次到m次 |
re.search匹配
import re
str1 = "我的QQ号是:12345678, 我的邮编是:100000"
reg = "(\d{8}).*(\d{6})" # .*表示任意字符重复多次
#分组匹配
print(re.findall(reg,str1)) # [('12345678', '100000')]
print(re.search(reg,str1)) # re.findall匹配
>>> import re
>>> str1 = "hello worldhello"
>>> reg = "hello"
>>> print(re.findall(reg,str1))
['hello', 'hello'] #为一个数组
>>> print(re.findall(reg,str1)[0])
hello
- 零宽断言
(?=reg) |
匹配reg前面的位置 |
|---|---|
(?<=reg) |
匹配reg后面的位置 |
(?!=reg) |
匹配后面跟的不是reg的位置 |
(? |
匹配前面跟的不是reg的位置 |
s = "helloworldchina"
reg1 = "l{2}o(?=world)"
reg2 = "(?<=world)[a-z]*"
print(re.findall(reg1, s)) #['llo']
print(re.findall(reg2, s)) #['china']
装饰器
1. 函数的返回值为一个函数,可以理解为闭包 。即外部函数的返回值是内部函数的引用。
def func(x):
if x == 1:
def inner_func(y):
print("inner 1 被调用")
return y*y
if x == 2:
def inner_func(y):
print("inner 2 被调用")
return y*y*y
return inner_func #标记 函数的引用
calc = func(2) # calc为一个变量, 接收func(2)的返回值,可理解为inner_func作为变量传给了calc。
# 执行顺序:会先申明x==2中的inner_func函数,接着返回inner_func这个变量(‘标记’位置),内部的inner_func()函数并未被调用及执行
print(type(calc)) # 函数的参数可以是一个函数。
def func1(x): # 函数1
return x * x
def func2(x): # 函数2
return x * x * x
def func3(x, y, i, j): # 函数3
return x(i) + y(j)
n = func3(func1, func2, 1, 2)
# func1是函数1的引用,并将函数的引用直接赋给x, x此时是一个函数。x(i)才表示函数1的执行
# func2是函数2的引用,并将函数的引用直接赋给y。y(j)才表示函数2的执行
# x(i) + y(j) 等于 func1(1) + func2(2) 等于 1*1 + 2*2*2 等于 9
- 装饰器
import time
def runtime_noargs(function_time): # function_time就是function_demo1函数
def wrapper():
start_time = time.time()
function_time() # function_demo1()函数的调用
end_time = time.time()
print(end_time - start_time)
return wrapper
@runtime_noargs # 就是一个闭包函数
def function_demo1():
time.sleep(1)
print("demo1函数运行")
function_demo1() # demo1函数运行 1.0001513957977295
函数中接收参数
def args_is_str(function_name):
def wrapper(a): # 此时function_demo2中的参数args,传到此处'a'处,参数名'a'可随意命名
t = type(a)
if not isinstance(t(), str):
print("参数错误")
else:
function_name(a)
return wrapper
@args_is_str
def function_demo2(args): # args要传给上面的'a'
print(args)
function_demo2(1) #参数错误
function_demo2('nba') #nba
函数中接收多个参数 —
*args(可变参数):表示不定长参数。
def many_args(function_name):
def wrapper(*args): # 函数名wrapper可任意命名
print(*args)
function_name(*args)
return wrapper
@many_args
def function_demo3(*args):
print(*args)
function_demo3(1,2,3,4,5)
# 1 2 3 4 5
# 1 2 3 4 5
函数中接收多个参数 —
**kwargs(关键字参数):以字典形式表示不同类型参数。
def dict_args(function_name):
def wrapper(**dict):
print(dict) #{'name': 'bryant', 'number': 24} 以字典形式打印
# function_name(**dict)
return wrapper
@dict_args
def function_demo4(**kwargs):
print(kwargs) #无打印输出,需要在wrapper调用function_name
# pass
function_demo4(name='bryant', number = 24)
#{'name': 'bryant', 'number': 24} 以字典形式打印
函数中接收多个参数 —
*args, **kwargs: 混合形式参数
def combo_args(function_name):
def wrapper(*args, **kwargs):
print(*args, kwargs)
return wrapper
@combo_args
def function_demo5(*args, **kwargs):
pass
function_demo5(2020, 2, name='bryant', number = 24)
# 2020 2 {'name': 'bryant', 'number': 24}
四. 编程技巧
求数组中相同元素
参考链接
from collections import defaultdict
def list_duplicates(seq):
tally = defaultdict(list)
for i,item in enumerate(seq):
tally[item].append(i)
return ((key, locs) for key, locs in tally.items() ) # k, v的值,也可以只返回k或v值
# if len(locs) > 1) # 可进行筛选
for dup in sorted(list_duplicates(source)):
print(dup)
>>> #输出举例
('A', [0, 2, 6, 7, 16, 20])
('B', [1, 3, 5, 11, 15, 22])
('D', [4, 9])
元素逆置
list1 = [1,2,3,4,5,6,7,8,9]
print(list1[-1]) # 9
print(list1[:-1]) # 除了最后元素[1, 2, 3, 4, 5, 6, 7, 8]
print(list1[::-1]) # 逆置 [9, 8, 7, 6, 5, 4, 3, 2, 1]
print(list1[5::-1]) # 取下标为5的元素翻转读取 [6, 5, 4, 3, 2, 1]
一维数组换行打印/或变多维数组
这里生成3×3矩阵
import numpy
list1 = [1,2,3,4,5,6,7,8,9]
for m in range(3):
print(list1[m*3 : (m+1)*3])
print(numpy.array(list1).reshape(3,3))
随机生成指定类型的随机数据
import random
temp = [25,50,100] # 给定数据
test = []
num = random.randint(2, 16)
for i in range(num):
test.append(random.choice(temp))
print(test) # 随机数组 [50, 25, 25, 100, 50, 25, 25, 100, 25, 50, 25]
两个不同长度数组间元素形成映射
list1 = ['A', 'B', 'C', 'D']
list2 = ['1', '2', '3']
list3 = list(map(lambda x: x[0]+x[1], list(zip(list1*3, list2*4))))
print(list(zip(list1*3, list2*4))) # [('A', '1'), ('B', '2'), ('C', '3'), ('D', '1'),...
for i in range(3):
print(list3[i*4: (i+1)*4])
# ['A1', 'B2', 'C3', 'D1']
# ['A2', 'B3', 'C1', 'D2']
# ['A3', 'B1', 'C2', 'D3']
五. 数据结构
字典树segmentTree
Leetcode307-区域和检索-字典树实现-参考链接
class SegmentTree:
def __init__(self, data, merge):
'''
data:传入的数组
merge:处理的业务逻辑,例如求和/最大值/最小值,lambda表达式
'''
self.data = data
self.n = len(data)
# 申请4倍data长度的空间来存线段树节点
self.tree = [None] * (4 * self.n) # 索引i的左孩子索引为2i+1,右孩子为2i+2
self._merge = merge
if self.n:
self._build(0, 0, self.n-1)
def query(self, ql, qr):
'''
返回区间[ql,..,qr]的值
'''
return self._query(0, 0, self.n-1, ql, qr)
def update(self, index, value):
# 将data数组index位置的值更新为value,然后递归更新线段树中被影响的各节点的值
self.data[index] = value
self._update(0, 0, self.n-1, index)
def _build(self, tree_index, l, r):
'''
递归创建线段树
tree_index : 线段树节点在数组中位置
l, r : 该节点表示的区间的左,右边界
'''
if l == r:
self.tree[tree_index] = self.data[l]
return
mid = (l+r) // 2 # 区间中点,对应左孩子区间结束,右孩子区间开头
left, right = 2 * tree_index + 1, 2 * tree_index + 2 # tree_index的左右子树索引
self._build(left, l, mid)
self._build(right, mid+1, r)
self.tree[tree_index] = self._merge(self.tree[left], self.tree[right])
def _query(self, tree_index, l, r, ql, qr):
'''
递归查询区间[ql,..,qr]的值
tree_index : 某个根节点的索引
l, r : 该节点表示的区间的左右边界
ql, qr: 待查询区间的左右边界
'''
if l == ql and r == qr:
return self.tree[tree_index]
mid = (l+r) // 2 # 区间中点,对应左孩子区间结束,右孩子区间开头
left, right = tree_index * 2 + 1, tree_index * 2 + 2
if qr <= mid:
# 查询区间全在左子树
return self._query(left, l, mid, ql, qr)
elif ql > mid:
# 查询区间全在右子树
return self._query(right, mid+1, r, ql, qr)
# 查询区间一部分在左子树一部分在右子树
return self._merge(self._query(left, l, mid, ql, mid),
self._query(right, mid+1, r, mid+1, qr))
def _update(self, tree_index, l, r, index):
'''
tree_index:某个根节点索引
l, r : 此根节点代表区间的左右边界
index : 更新的值的索引
'''
if l == r == index:
self.tree[tree_index] = self.data[index]
return
mid = (l+r)//2
left, right = 2 * tree_index + 1, 2 * tree_index + 2
if index > mid:
# 要更新的区间在右子树
self._update(right, mid+1, r, index)
else:
# 要更新的区间在左子树index<=mid
self._update(left, l, mid, index)
# 里面的小区间变化了,包裹的大区间也要更新
self.tree[tree_index] = self._merge(self.tree[left], self.tree[right])
class NumArray:
def __init__(self, nums: List[int]):
self.segment_tree = SegmentTree(nums, lambda x, y : x + y)
def update(self, i: int, val: int) -> None:
self.segment_tree.update(i, val)
def sumRange(self, i: int, j: int) -> int:
return self.segment_tree.query(i, j)
1. 参考笔记 - 鱼C工作室
2. 参考笔记 - 菜鸟教程
3. 参考笔记 - python小例子 公众号
4. 参考笔记 - python与算法社区 公众号
5. 参考笔记 - 贪心科技
6. 参考笔记 - LeetCode