maskrcnn-benchmark学习随笔
maskrcnn_benchmark源码学习
- 写在前面
- 关于backbone
- 1. 先期采用vgg16_bn进行初步探索。
- 2. 实验过程随笔
- 3. ResNet
- 各种变体结构
- resnet网络结构
- 初级和高级block : Residual Block和BottleNeck Block
- 4. FPN结构
- 关于rpn
- 关于roi_heads
- 1. box_head
- 2. mask_head
- 数据集标签的制作、数据增强与加载
- 评估方法MetricLogger
- 模型评估、保存与加载CheckPointer
写在前面
之前大多关注的是faster rcnn、mask rcnn,但它们的开山作rcnn、fast rcnn却没怎么仔细了解,这里补充下资源,有必要时回头学习。
rcnn-译bounding_box_regressionfast rcnn-译smoth_l1_lossfaster rcnn-译mask rcnn-译
关于backbone
1. 先期采用vgg16_bn进行初步探索。
(1) 用vgg-c4还是vgg-c5作为backbone输出?先用-c5吧
(2) 关于初始化策略,参考此博客
方案是采用预训练模型参数初始化并冻结前几层,随机初始化后面的高层,重新训练。
参考fast rcnn的结论,对于vgg16,fine-tune conv3-1之后的所有层是权衡训练速度、gpu显存和mAP的最佳选择。
并且一般conv1也就是第一阶段的卷积对预测结果影响不大,也就是直接初始化imageNet的权重即可。通常称这个阶段为stem-stage。
2. 实验过程随笔
torchvision.models的预训练模型默认保存在'./home/host/.torch/models'文件夹,这是个隐藏文件夹
可以在model_zoo或者找到model_url通过浏览器或者迅雷下载,更快些,模型保存位置自己定
model.parameters()返回模型参数,冻结用法
for param in model.parameters():
param.requires_grad = False
model.named_parameters()返回一个生成器,迭代生成的是权重命名、权重参数
for name, parameter in model.named_parameters():
print(name, parameter.shape)
关于pytorch模型加载和保存,更多细节参考
关于如何提取vgg16特征提取部分的网络架构,具体要保留哪些,视情况而定
vgg_features_extractor = nn.Sequential(*list(vgg16.features.children())[:-1])
更细节的,像我有点小强迫症,喜欢模块化,所以想给各部分取名字以区分模块,那么免不了要用到OrderedDict了
from collections import OrderedDict
classifier = nn.Sequential(nn.Linear(in_features=20588, out_features=4096, bias=True),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(in_features=4096, out_features=4096, bias=True),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(in_features=4096, out_features=10))
model = nn.Sequential(OrderedDict([('features', nn.Sequential(*list(model.features.children())[:-1])),
('classifier', classifier)]))
首先将各个模块分别写好,比如提前写好feature = nn.Sequential(...); classifier = nn.Sequential(...),那么接下来
用一个nn.Sequential(OrderedDict([('features', features), ('classifier', features)])把各个模块封装起来。如此甚好
torch.save()实现对网络结构和模型参数的保存。有两种保存方式:
(1) 是保存年整个神经网络的的结构信息和模型参数信息,save的对象是网络net;
(2) 是只保存神经网络的训练模型参数,save的对象是net.state_dict()。
# 保存和加载整个模型
torch.save(model_object, 'model.pkl')
model = torch.load('model.pkl')
# 仅保存和加载模型参数(推荐使用)
torch.save(model_object.state_dict(), 'params.pkl')
model_object.load_state_dict(torch.load('params.pkl'))
关于重塑vgg16,提供接口指定输入和输出的通道数。 好像也不需要
关于配置文件config中,cfg.SOLVER.STEPS的说明,参考blog
就是用来调整学习率的step,比如到了steps[0]调整(衰减)第一次,steps[1]第二次…
3. ResNet
各种变体结构
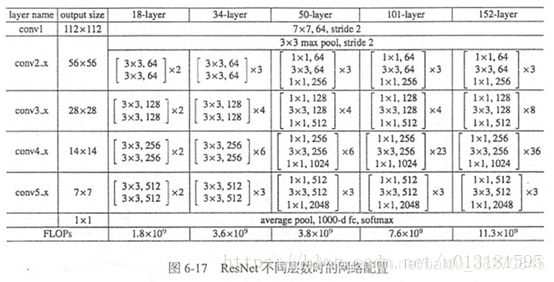
resnet网络结构
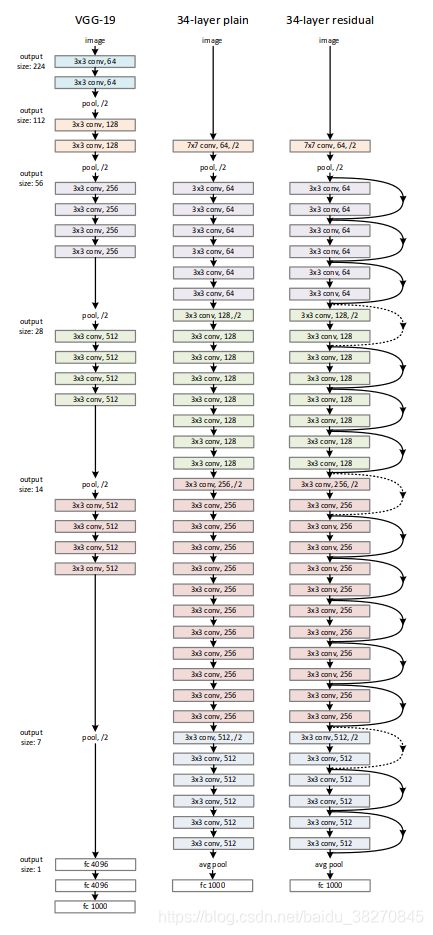
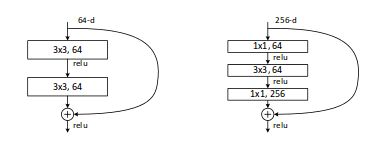
初级和高级block : Residual Block和BottleNeck Block
4. FPN结构
参考gihubpytorch-fpn
building block
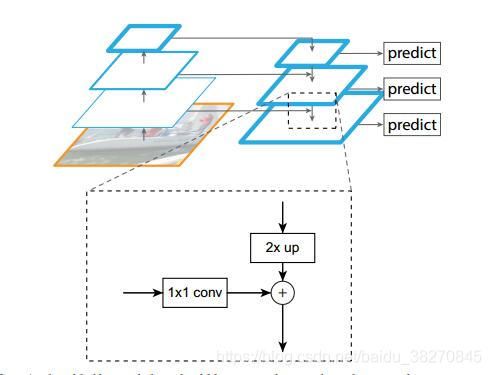
- FPN参考博客
每一层输出的feature maps都是256个通道。
关于rpn
anchor_generator
首先,必要的参数是(stride, scales, aspect_ratios)
stride是backbone卷积网络的stride,一般stride=16,表示得到的feature map相比原输入图缩小了stride倍。同时它也是作为初始anchor的base_size。一般初始anchor为(0, 0, 15, 15)即中心为(7.5, 7.5),宽高为(16, 16)。
其次,根据初始anchor,由给定的不同宽高比例aspect_ratios,在保证面积近似一致的情况下,生成指定宽高比例的anchors。
最后,迭代上述过程生成的不同宽高比例的anchors,每一种anchor又分别扩展到给定的面积scales。注意,这里scales参数是指相对于原输入图像上的面积,但实际上在扩展anchor时,考虑到feature map已经缩小了stride倍,所以在计算时将给定的参数scales分别都除以stride再乘以宽高。
实验过程随笔
下午写的很多东西因为突然断电,没了!!
后面简单补充关键点
*由generate_anchors()得到的是初始的k个anchors,需要将他们扩展到全图(feature map),maskrcnn里是将这个函数再包装在nn.Module的继承类里边,作为最终的anchor_generator。由forward(imagelist, feature_map)返回全图的mxmxk个anchors。
*straddle_thresh=0和visibility
全图的anchors有大量的越界情况,后期对越界anchors进行处理,需要对越界的anchors进行标记,anchor左上角坐标大于straddle_thresh并且右下角坐标小于图像高宽+straddle_thresh的记为界内,否则记为界外。界内的visibility记为1,越界的记为0。
*anchor_stride注意区别于cnn的stride
这个参数关于anchors在原图上滑动的步长。比如feature map上第一个位置处的一个anchor(0,0,15,15),anchor_stride=32,那么它在feature map上第二个位置处的坐标为(0,0+anchor_stride,15,15+anchor_stride)。
另外这个参数应该怎么设定?应该是和stride同样大小吧。如果是fpn网络的backbone,这个stride应该分不同阶段给定
- rpn的设计以及代码实现
*几个问题
(1) 关于输入图像的长短边问题
INPUT:
MAX_SIZE_TRAIN: 1000
MIN_SIZE_TRAIN: 800
MAX_SIZE_TEST: 1000
MIN_SIZE_TEST: 800
这么设定的原因是什么?
(2) 关于参数size_divisibility=32
这个参数是在to_image_list(tensors, size_divisible=0)函数中会用到,首先这个函数找到batch所有图像的最大长宽,然后目的是统一尺寸到最大长宽,这样才能放到一个batch_tensor里边。另外,size_divisiblity=32也就是stride,它要确保每一张图像都能够被这个stride完整划分,所以如果不能完整划分,那么需要将图像进行0填充。做法是,math.ceil(max_size / stride) * stride向上取整,不能用max_size // stride * stride,整除是向下取整,会使尺寸变小。
*也就是说,backbone计算得到的feature map是在填充过的输入图像上计算得来的。
*那这个参数应该怎么设置?是和cnn阶段的stride一致吗?
*另外图像尺寸改变了,那gt_bbox不是也要改?事实上不用改,因为给图像填充是在右边和下边进行填充的,图像的坐标系没有变化,因而gt_bbox的坐标也不用更新。
(3) rpn主要由rpn_head、anchor_generator和loss_evaluator构成,更细节的,还涉及候选框的编解码器,分类和回归的损失函数,正负样本的采样策略等。
(4) rpn的前向传播过程,包括训练和测试。
(5) 训练时,不是整图计算feature map上的anchors的损失吗?采样是个什么鬼?不是所有anchors都要匹配吗?
带着以上的问题,实验观察ing…
假设feature map的shape为Nx512xSxS,N为batch_size,S为输入size/stride。
*则rpn_head输出的objectness.shape==(N, A, S, S), box_regression.shape==(N, Ax4, S, S)
*关于训练时的正负样本采样以及loss评估,重点关注class RPNLossComputation(object)
RPNLossComputation.__init__(self, proposal_matcher, fg_bg_sampler, box_coder)
RPNLossComputation.__call__(self, anchors, objectness, box_regression, targets)训练时才会被调用计算损失,分别返回分类和回归损失。
*proposal_matcher匹配器,根据匹配得分矩阵MxN,得分指标是iou,M表示gt_bbox,N表示predict_bbox。
__call__(self, match_quality_matrix)返回的是每个预测框(anchor)相应匹配度最佳gt_bbox(的索引值)N(i), i belong to [0, M-1),当然,如果匹配得分低于阈值则该预测框记为负样本。注意,返回的是所有anchors的标记,而且这里的标记也不是最终的标记,后面还会转换。
*BalancedPositiveNegativeSampler该类用于采样固定比例的正负样本。
__init__(self, batch_size_per_image, positive_fraction)参数分别是,每张图像上要采样(前景候选框和背景候选框)的总数,正样本的比例。
调用函数__call__(self, matched_idxs),matched_idxs: list of tensor, -1, 0 or positive values,分别表示ignore(0.3<=iou<0.7), 负样本(iou<0.3)和正样本(iou>=0.7),返回值分别是正、负样本的idxs。
*接下来是重头戏,RPNLossComputation
prepare_targets(self, anchors, targets)返回的是labels, regression_targets,也就是所有anchors都会给上一个标签(-1 ignore,0 bg,1 fg),关于regression_targets是如何计算的,需要熟悉原理再去看BoxCoder是如何编解码的。
__call__(self, anchors, objectness, box_regression, targets)返回objectness_loss, box_loss。
(1) prepare_targets给所有anchors分配标签和和编码targets的回归值;
(2) fg_bg_sampler采样正负样本,返回其idxs;
(3) 将objectness, box_regression平铺展开,最终希望objectness和label、box_regression和regression_targetsshape一样;
(4) 计算损失,binary_cross_entropy_with_logits和smooth_l1_loss
objectness_loss = F.binary_cross_entropy_with_logits(objectness[sampled_inds], labels[sampled_inds])
box_loss = smooth_l1_loss(box_regression[sampled_pos_inds], regression_targets[sampled_pos_inds],
beta=1.0 / 9, size_average=False, ) / (sampled_inds.numel())
当然,测试时前向过程直接计算anchors的objectness得分,然后排序选取topk即可。训练时才需要计算损失,更加关键。
*还有box_selector_train = make_rpn_postprocessor(cfg, rpn_box_coder, is_train=True)
这里因为我只debugrpn,所以不需要选择bboxes,返回所有anchors。之后加入roi_head再观察研究。
- 损失函数loss
objectness损失函数binary_cross_entropy_with_logits就不说了,比较原始的loss fuction。重点学习一下bbox_regression的losssmoth_l1_loss。
*原理部分[参考此博客]or回去参考有道云笔记,之前学习过。再复习一下,然后在maskrcnn_benchmark对号入座。
*小结
(1) Bounding Box Regression(rcnn原文有详细介绍bbox_regression)
首先rpn里的anchors其实都可能是proposals,只是经过box_regression和objectness排序之后才能得到准确高质量的proposals。
这个回归器呢其实是根据cnn得到的feature map, 用一个3x3和一个1x1卷积核处理得到512-d(假设)的特征向量,用来进行分类和回归。回归器可以看做是一个512x(9x4)(假设每个锚点9个anchors)的权重矩阵,也就是全连接512-d的特征,输出9x4预测值,预测值实际上不是边框的坐标,而是预测anchor相对于真实边框的偏移量。通过编码解码器可以很方便将这个预测的偏移量转变为bbox的坐标。可以看做网络输出的还是坐标,这与后面的假设一致。
假设预测为fg的anchor的坐标为 P ( P x , P y , P w , P h ) P(P_x,P_y,P_w,P_h) P(Px,Py,Pw,Ph),原始标签为 G ( G x , G y , G w , G h ) G(G_x, G_y, G_w, G_h) G(Gx,Gy,Gw,Gh),我们的目的是找到映射函数 F F F,使得 G ^ = F ( P ) ≈ G \hat{G}=F(P)\approx G G^=F(P)≈G
并且假设这个函数是线性函数,但其实当且仅当预测bbox与gt_bbox的高和宽高度近似时,映射是线性函数才能成立(后面会说明)。
那么需要对这种mode=xyxy形式的标签进行编码encode,希望它和真正的预测值(偏移量)一致,
t x = G x − P x P w t y = G y − P y P h t w = log G w P w t h = log G h P h t_x = \tfrac{G_x-P_x}{P_w}\\ t_y = \tfrac{G_y-P_y}{P_h}\\ t_w = \log\tfrac{G_w}{P_w}\\ t_h = \log\tfrac{G_h}{P_h} tx=PwGx−Pxty=PhGy−Pytw=logPwGwth=logPhGh
这是预测anchor相对于标签的真实偏移量target,反过来decode
G ^ x = P x + Δ x P w G ^ y = P y + Δ y P h G ^ w = P w exp ( Δ w ) G ^ h = P h exp ( Δ h ) \hat{G}_x = P_x+\Delta x P_w \\ \hat{G}_y = P_y+\Delta y P_h \\ \hat{G}_w = P_w\exp(\Delta w) \\ \hat{G}_h = P_h\exp(\Delta h) G^x=Px+ΔxPwG^y=Py+ΔyPhG^w=Pwexp(Δw)G^h=Phexp(Δh)
显然 t x 、 t y t_x、t_y tx、ty的encode函数是线性的; t w = log ( G w + P w − P w P w ) = log ( 1 + G w − P w P w ) t_w=\log(\tfrac{G_w+P_w-P_w}{P_w})=\log(1+\tfrac{G_w-P_w}{P_w}) tw=log(PwGw+Pw−Pw)=log(1+PwGw−Pw),
我们知道, lim x → 0 log ( 1 + x ) ≈ x \lim_{x\rightarrow0}\log(1+x)\approx x limx→0log(1+x)≈x,所以当 G w → P w G_w\rightarrow P_w Gw→Pw时,该映射是线性的。
而在检测时,我们肯定不能只凭借宽高来计算偏移量,这个条件应该是用iou来评估的。
(2) multi_task_loss(fast rcnn原文有详细介绍smoth_l1_loss)
假设 ( p , u , t u , v ) (p,u,t^u,v) (p,u,tu,v)分别表示anchor的前景概率、真实标签(0,1)、真实偏移量target和预测偏移量,那么总损失如下
L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u = 1 ] L r e g ( t u , v ) = − log ( p u ) + λ [ u = 1 ] Σ i ∈ ( x , y , w , h ) s m o o t h L 1 ( t u − v ) \begin{aligned} L(p,u,t^u,v) & = L_{cls}(p,u)+\lambda [u=1]L_{reg}(t^u,v) \\ & = -\log(p_u)+\lambda [u=1]\Sigma_{i\in(x,y,w,h)}smooth_{L1}(t^u-v) \end{aligned} L(p,u,tu,v)=Lcls(p,u)+λ[u=1]Lreg(tu,v)=−log(pu)+λ[u=1]Σi∈(x,y,w,h)smoothL1(tu−v)
并且,
s m o o t h L 1 ( x ) = { 0.5 x 2 if |x|<1 ∣ x ∣ − 0.5 else smooth_{L_1}(x)= \begin{cases} 0.5x^2 & \text{if |x|<1} \\ |x|-0.5 & \text{else} \end{cases} smoothL1(x)={0.5x2∣x∣−0.5if |x|<1else
smoth_l1_loss曲线图
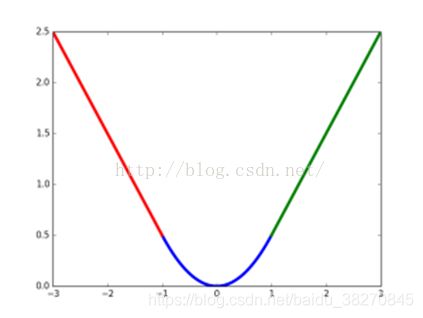
*非极大值抑制NMS算法
【非极大值抑制(NMS)的几种实现】
为了打破速度瓶颈,通常需要使用C语言版本的NMS以及cuda加速,因为在大量的计算下,python的慢体现得很明显。
这里只学习原理和简单python实现。
*IOU(overlap)计算
关于重叠率的计算,在这个模块里from boxlist_ops import boxlist_iou,
用法是overlaps = boxlist_iou(prediction, gt_boxes)
关于roi_heads
1. box_head
关键modulebox_head.py,子module包括
roi_box_feature_extractor,根据cnn的features和rpn的proposals来提取rois的特征,作为后期推理依据;
主要有两种情况,一种是原始CNN的最后一层特征,一种是带有FPN结构的多层融合特征。根据proposals和feature maps,输入pooler器,提取特征,最后得到一个proposal对应一个roi_feature。
两者有比较小的差别。
roi_box_predictor,头部预测器,可以是典型的Fast RCNN Detector结构,或者是带有FPN的结构;
两者都有两个线性全连接层来做分类和回归,区别差异不大。
PostProcessor,主要用于编解码bbox和nms滤除detections;
FastRCNNLossComputation,损失评估器;
2. mask_head
同样的,由roi_mask_feature_extractor ,roi_mask_predictor,PostProcessor和LossComputation构成。
feature_extractor主要负责将proposals的features提取出来,即roi_features,mask_predictor由一个反卷积ConvTranspose2d上采样和一个conv1x1逻辑回归全连接线性分类器预测各像素输出。
数据集标签的制作、数据增强与加载
参考语雀的部分笔记。
评估方法MetricLogger
参考语雀的部分笔记。
模型评估、保存与加载CheckPointer
参考语雀的部分笔记。