Python TFIDF计算文本相似度
本文主要参考https://stackoverflow.com/questions/12118720/python-tf-idf-cosine-to-find-document-similaritStackOverflow的回答
主要是使用sklearn的TfidfTransformer
cosine_similarity就是计算L2归一化的向量点乘。如果x,y是行向量,它们的cosine similarityk是:
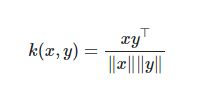
linear_kernel 是多项式核的特例,如果x,和y是列向量,他们的线性核为:

fit &fit_tansform & transform
- fit是一个适配的过程,用于train,得到一个统一的转换的规则的模型;
- transform:将数据进行转换,比如测试数据按照训练数据同样的模型进行转换,得到特征向量;
- fit_tansform:将上述两个合并起来,fit to data,then transform it. 如果训练阶段用的是fit_transform,在测试阶段只需要transform就行
也就是一般训练的时候用fit_transform(train_data)
在测试的时候用transform(test_data)
回答一
如果你想提取count features并应用TF-IDFnormalizaition以及行基础的欧式距离,用一个操作就行:
TFidfVectorizor
>>> from sklearn.feature_extraction.text import TfidfVectorizer
>>> from sklearn.datasets import fetch_20newsgroups
>>> twenty = fetch_20newsgroups()
>>> tfidf = TfidfVectorizer().fit_transform(twenty.data)
>>> tfidf
<11314x130088 sparse matrix of type 'numpy.float64'>'
with 1787553 stored elements in Compressed Sparse Row format>
现在要求一个文档(如第一句)同其他所有文档的距离,只需要计算第一个向量和其他所有向量的点乘,因为tfidf向量已经row-normalized
cos距离并不考虑向量的大小(也就是绝对值),Row-normalised(行标准化)向量大小为1,所以Linear Kernel足够计算相似值。
scipy sparse matrix查看第一个向量:
>>> tfidf[0:1]
<1x130088 sparse matrix of type 'numpy.float64'>'
with 89 stored elements in Compressed Sparse Row format>
scikit-learn已经提供了pairwise metrics,稀疏的不稀疏的矩阵表示。这里我们需要点乘操作,也叫linear kernel:
>>> from sklearn.metrics.pairwise import linear_kernel
>>> cosine_similarities = linear_kernel(tfidf[0:1], tfidf).flatten()
>>> cosine_similarities
array([ 1. , 0.04405952, 0.11016969, ..., 0.04433602,
0.04457106, 0.03293218])
这里插播一下,linear_kernel的输入是(NT)和(MT)的向量,输出(N*M)的向量
因此,要找5个最接近的相关文档,只需要用argsort切片取就行了:
>>> related_docs_indices = cosine_similarities.argsort()[:-5:-1]
>>> related_docs_indices
array([ 0, 958, 10576, 3277])
>>> cosine_similarities[related_docs_indices]
array([ 1. , 0.54967926, 0.32902194, 0.2825788 ])
第一个结果用于检查,这是query本身,相似度为1
在这个例子里,learn_kernel就相当于cos similarity,因为sklearn.feature_extraction.text.TfidfVectorizer本身得到的就是归一化后的向量,这样cosine_similarity就相当于linear_kernel
回答2
是个手动计算的方法
循环计算test_data与train_data的特征间的cosine 距离
首先用简单的lambda函数表示cosine距离的计算:
cx = lambda a, b : round(np.inner(a, b)/(LA.norm(a)*LA.norm(b)), 3)
然后就只要for循环就行
for vector in trainVectorizerArray:
print vector
for testV in testVectorizerArray:
print testV
cosine = cx(vector, testV)
print cosine
回答3
跟回答1一样,不过直接用cosine_similarity
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import TfidfVectorizer
print "cosine scores ==> ",cosine_similarity(tfidf_matrix_train[0:1], tfidf_matrix_train) #here the first element of tfidf_matrix_train is matched with other elements