R语言基础介绍
文章目录
- 软件安装
- R语言
- RStudio
- 可视化数据挖掘工具Rattle
- 菜单栏
- Data-数据读入
- Explore-数据探索
- Test-数据相关检验
- Transform-数据转换
- Cluster-聚类
- Mode-构建模型
- Evaluate-模型评估
- Log-日志
- R语言基础介绍
- 区分大小写
- 赋值符号
- 注释符号
- 管理工作空间
- 查看工作空间
- 显示和修改工作目录
- R语言的包
- 查看帮助
- 数据结构
- 向量
- 创建向量
- 查看向量长度
- 向量的模式
- 向量化
- 矩阵
- 数组
- 创建数组
- 选取数组中的元素
- 数据框
- 创建数据框
- 选取数据框的元素
- 因子
- 名义型变量
- 有序型变量
- 创建因子
- 列表
- 创建列表
- 列表的索引
- 编辑列表
- 数据的读取
- 读取文本文件
- 读取非结构化文本文件
- 读取网络数据
- R语言的基础绘图
- 散点图
- 普通散点图
- 散点图矩阵
- 柱状图和条形图
- 绘制饼图
- 绘制Q-Q图
- 箱线图
- 茎叶图
- 点图
- R语言描述性统计分析
- 参考资料
软件安装
R语言
https://www.r-project.org/
RStudio
https://www.rstudio.com/
可视化数据挖掘工具Rattle
#Rattle的安装
install.packages("RGtk2")
install.packages("rattle")
library(rattle)#载入rattle包
rattle()#调出Rattle界面
菜单栏
-
数据读入(Data)
-
数据探索(Explore)
-
数据相关验证(Test)
-
数据转换(Transform)
-
聚类分析(Cluster)
-
关联规则(Associate)
-
构建模型(Mode)
-
模型评估(Evaluate)
-
日志(Log)
Data-数据读入
在数据来源中,通常有来源于表格的数据(Spreadsheet),例如在Excel中建立的数据:来源于数据库的数据(ODBC),例如通过R直接提取MySQL中的数据;来源于R软件中的数据集(R Dataset)等。
第三行中的参数Partition主要用于数据的划分。在Rattle包中,为了方便进行模型的建立和分析,系统将会把原始数据集划分为三部分:Training、Validation以及Testing。系统将默认划分比例设定为70:15:15,并将按照划分比例从数据集中随机抽取样本。在具体使用过程中,数据集Training主要用于模型的建立,数据集Validation以及数据集Testing主要用于模型评估以及模型测试。
在确定数据来源与数据划分之后,系统将会列出数据集中的各个变量以及变量的数据类型。在数据对话框中,我们可以选择变量在构建模型时的具体作用。
这里我们读取气象数据集,其目标是预测明天是否下雨

Explore-数据探索
Explore选项主要能根据数据集输出关于数据集的一下信息:数据总体概括(Summary)、数据分布情况(Distributions)、数据的相关系数矩阵(Correlation)、数据集的主成分分析(Principal Components)以及各变量之间的相互作用(Interactive)。
- 描述性统计分析
例如这里对气象数据集进行描述性统计分析,选中"Summary"之后,点击“执行”。
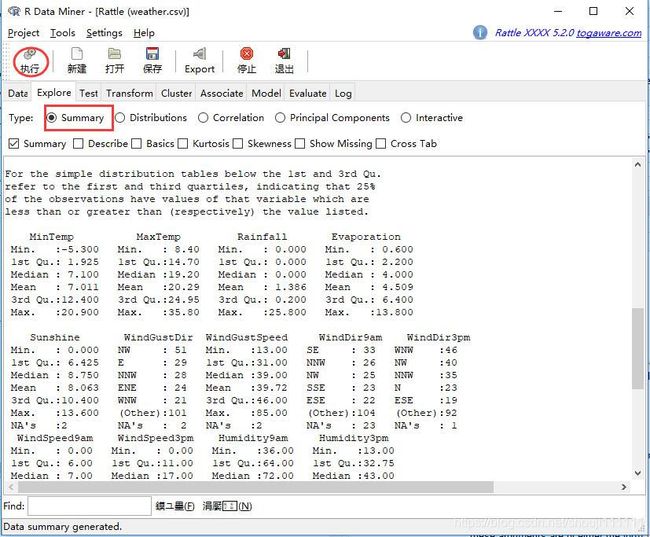
- 数据的分布
选中Distributions,查看变量MinTemp的箱线图

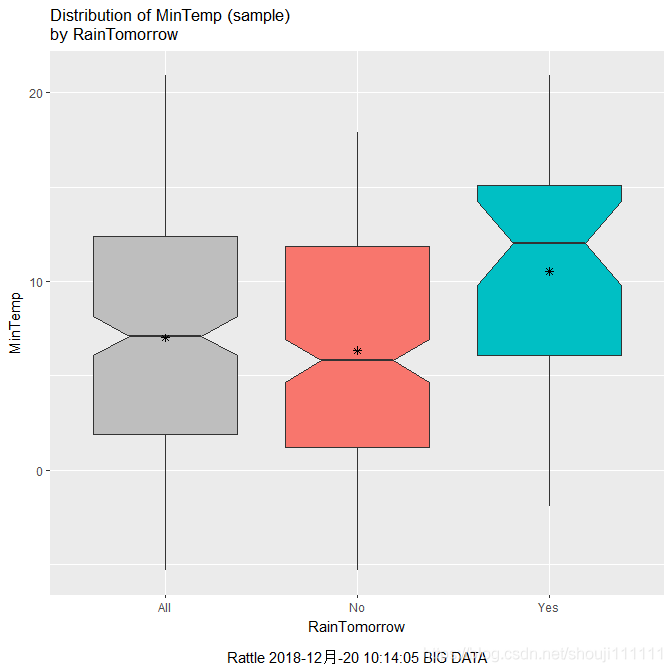
Test-数据相关检验
Test选项主要进行的统计检验有:KS检验(Kolmogorov-Smirnov)、威尔克特斯检验(Wilcoxon Rank-Sum)、T检验(T-test)以及F检验(F-test)。
Transform-数据转换
选项Transform主要用于数据集的预处理。
Transform选项对数据的转换主要有4种转换类型,分别为数据标准话(Rescale)、数据插值(Impute)、数据重排列(Recode)以及数据清理(Cleanup)。我们可以看到,在数据转换类型Type的下面一行里,显示出了在数据标准化中将要使用到的标准化方式,例如0-1标准化等。
Cluster-聚类
Cluster选项主要存在4种数据的聚类方式,分别为K均值聚类法(KMeans)、自适应的软子空间聚类算法(Ewkm)、层次聚类法(Hierarchical)以及双聚类算法(BiCluster)。在聚类方法Type的下面一行主要用于决定聚类分析的相关参数,例如类别数量以及随机生成器初始值等。
Mode-构建模型
第一行是模型类型Type,总共有6种。
- Tree-决策树
- Forest-随机森林
- 组合算法(Boost)
- 支持向量机(SVM)
- 线性回归(Linear)
- 神经网络(Neural Net)
这里的模型类别并非由R软件自定固定决定,而主要取决于读者电脑中相关的程序包。即读者需要评估何类模型,则应先下载安装相应的模型构建程序包。
在确定了模型的预测类别后,界面下面将会出现和模型相关的参数。例如从图中关于决策树的参数中我们可以看到,第一个参数值是决策树的最小节点数。在确定模型的类别以及模型相关的参数之后,我们需要点击"执行"按钮进行模型的构建。
系统在建立出模型之后将会在下面的对话框中展示出模型的相关信息。
我们取rattle默认的数据集“weather.csv”为例,以随机森林为例,详细情况如下图所示。

上图是利用Rattle程序构建随机森林模型的相关结果输出图。在图中我们可以看到,随机森林模型中决策树的个数为500棵,而每一棵决策树的节点分支处所选择的变量个数为4个。
在参数决定窗口的旁边有四个按钮。其中,Importance按钮主要用于绘制模型中各变量在不同标准下的重要值图像;Errors按钮主要用于绘制模型中各个类别以及根据袋外数据计算的误判率的图像;OOB ROC按钮主要用户绘制根据随机森林模型的袋外数据计算而得到的ROC图像。例如点击impotrant可以查看模型中各个变量的重要性

上图是通过Importance按钮生成的重要值图像。该图像总体分为两个图像,其中第一个图像为根据精确度平均减少值所计算得出的重要值所绘制;第二个图像为根据节点不纯度减少平均值计算得出的重要值所绘制。图中纵轴为所有变量的名称,横轴为各变量对应的重要值,越在顶层的变量对于模型的重要程度越大。

上图是通过Errors按钮生成的误判率图像。该图中总共有三条颜色的线,这三条线分别代表了肯定结论的误判率、否定结论的误判率以及根据袋外数据计算而得的误判率。该图中纵轴为具体误判率的值,而横轴为随机森林中决策树的数量。查看模型有没有出现欠拟合或过拟合的结果,误判率图像可以用来帮助决策随机森林中决策树的数量。
Evaluate-模型评估
Evaluate选项中,Rattle程序包提供了一系列模型评估标准。其中有模型混淆矩阵(Error Matrix)、模型风险表(Risk)、模型ROC图像(ROC)以及模型得分数据集(Score)等各类模型评估指标。
在模型评估标准类型的下面一行是需要进行评估的模型类别,这一行的选项只有在前面Model选项中已经建立了的模型才可用。在模型类别的选择栏下面一行是数据类型选择栏,Training数据集用于模型构建,而Validation数据集与Testing数据集用于模型评估。
如选择混淆矩阵,我们选择Error Matrix之后点击执行,查看结果

Log-日志
选项Log主要用于记录以上所介绍的所有功能的具体执行情况。Rattle非常好的地方就是在日志中会将你执行的所有步骤的R脚本保存,我们可以从日志中学习很多的语法,比如我们执行某个变量的箱线图之后,可以在日志中查看如何通过脚本绘制箱线图。
R语言基础介绍
友好编辑器
RStudio
区分大小写
> a<-1:15
> a
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
> A
错误: 找不到对象'A'
> cor(iris[,1:4])#鸢尾花数据集中第1列至第4列变量之间的相关性系数
Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 1.0000000 -0.1175698 0.8717538 0.8179411
Sepal.Width -0.1175698 1.0000000 -0.4284401 -0.3661259
Petal.Length 0.8717538 -0.4284401 1.0000000 0.9628654
Petal.Width 0.8179411 -0.3661259 0.9628654 1.0000000
> Cor(iris[,1:4])#无法找到Cor这个函数,因此函数也是区分大小写
Error in Cor(iris[, 1:4]) : 没有"Cor"这个函数
赋值符号
R语句由函数和赋值构成,R语言的标准赋值符号是<-(即一个小于号加上一个减号)
> y<-rnorm(5)#创建一个名为y的向量对象,它包含5个来自标准正态分布的随机偏差
> y
[1] 1.3800778 -0.9753630 1.5347207 -1.1228029 0.7462479
c(1:4)
> x
[1] 1 2 3 4
> c(1:4)->x
> x
[1] 1 2 3 4
> assign("x",c(1:4))#使用赋值函数assign()
> x
[1] 1 2 3 4
注意:
- R语言允许=为对象赋值,但是它不是标准语法,某些情况下,用等号赋值会出现问题。
- R语言还有可以反转赋值方向,例如
c(1:4)->x与x<-c(1:4)等价 - R语言还有一个赋值函数assign()
- 使用等号赋值的做法并不常见,不推荐使用
注释符号
注释由符号#开头,在#之后出现的任何文本都会被R解释器忽略
管理工作空间
查看工作空间
在R中可以通过ls()查找当前工作空间的对象。
#创建数据对象
a<-1:6
#创建模型对象fit
fit<-lm(Sepal.Length~Sepal.Width,data=iris)
fit #得到截距为6.5262,自变量的系数为-0.2234
#查看模型的详细内容
summary(fit)
#创建图形对象p
library(ggplot2)
p<-qplot(mpg,wt,data = mtcars)
p
ls() #通过ls()命令查找当前工作空间的对象
#通过rm函数移除一个或多个对象
rm(list = "fit")
ls()
#移除全部对象
rm(list = ls())
ls()
> fit
Call:
lm(formula = Sepal.Length ~ Sepal.Width, data = iris)
Coefficients:
(Intercept) Sepal.Width
6.5262 -0.2234
> summary(fit)
Call:
lm(formula = Sepal.Length ~ Sepal.Width, data = iris)
Residuals:
Min 1Q Median 3Q Max
-1.5561 -0.6333 -0.1120 0.5579 2.2226
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.5262 0.4789 13.63 <2e-16 ***
Sepal.Width -0.2234 0.1551 -1.44 0.152
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.8251 on 148 degrees of freedom
Multiple R-squared: 0.01382, Adjusted R-squared: 0.007159
F-statistic: 2.074 on 1 and 148 DF, p-value: 0.1519
> ls()
[1] "a" "fit" "p"
> rm(list = "fit")
> ls()
[1] "a" "p"
> rm(list = ls())
> ls()
character(0)
显示和修改工作目录
#显示当前的工作目录
getwd()
#修改当前的工作目录
setwd("mydirectory")
R语言的包
包是R函数、数据、预编译代码以一种定义完善的格式组成的集合。从某种意义上,R的包就是针对R的插件,相当于Python里面的库,不同的插件满足不同的需求。
- 查看包的位置
> .libPaths()
[1] "F:/Rsoftware/R3.4.4/R-3.4.4/library"
- 安装包
- 通过命令
install.packages("package_name","dir")#可以省略安装路径dir,默认是安装我们之前的路径
第一次安装的时候需要选择镜像

- 通过工具栏(在RStudion)操作

- 加载包
通过library或者require命令加载包
#加载shiny包并使用runExample函数,必须先加载包之后才能调用里面的函数
library(shiny)
runExample()
runExample("01_hello")
> library(shiny)
> runExample()
Valid examples are "01_hello", "02_text", "03_reactivity", "04_mpg", "05_sliders", "06_tabsets", "07_widgets", "08_html", "09_upload", "10_download", "11_timer
shiny包可以实现平台的交互,改变图像中的滑动条,图形就会跟着改变。

查看帮助
有两种方式
> help(plot)
> ?plot
> ??plot #两个问号,检索所有与plot相关的信息
在RStudio还有另外一种快捷的方式‘

数据结构
向量
创建向量
向量是用于存储数值型、字符型或逻辑型数据的一维数组。执行组合功能的函数c()和相应的参数可用来创建向量。
各类向量的示例如下
a<-c(1:4) #数值型变量
b<-c("one","two","three","four") #字符型变量
d<-c("TRUE","TRUE","FALSE","FALSE") #逻辑型变量
ab<-c(a,b) #数值型+字符型=字符型
ab
bd<-c(b,d) #字符型+逻辑型=字符型
bd
> ab<-c(a,b) #数值型+字符型=字符型
> ab
[1] "1" "2" "3" "4" "one" "two" "three" "four"
> bd<-c(b,d) #字符型+逻辑型=字符型
> bd
[1] "one" "two" "three" "four" "TRUE" "TRUE" "FALSE" "FALSE"
注意:单个向量的数据必须属于相同的类型或模式(数值型、字符型或逻辑型)。如果不是,R将强制执行类型转换
由于R中内置了同名函数c(),最后不要在编码时使用c作为对项目,否则可能产生一些不易察觉的问题
标量是只含一个元素的向量,例如 f<-3、g<-"US"、h<-TRUE
它们用于保存常量。
查看向量长度
查看向量中有多少个元素。
> d<-c(TRUE,TRUE,FALSE,FALSE) #逻辑型变量,可以简写T,F,不过注意要大写
> length(d) #查看长度
[1] 4
向量的模式
> d<-c(TRUE,TRUE,FALSE,FALSE) #逻辑型变量
> mode(d) #查看模式
[1] "logical"
向量化
- 向量的运算
#长度相同
v1<-seq(1,10,2)
v2<-seq(2,10,2)
v12<-v1+v2
v12
#长度不同
w1<-c(2,4,6,8)
w2<-c(10,12)
w12<-(w1+w2)
w12
> v12
[1] 3 7 11 15 19
> w12
[1] 12 16 16 20
解释w12:
w1的第一个元素2加上w2的第一个元素10等于12
w1的第二个元素4加上w2的第二个元素12等于16
本应该的是,w1的第三个元素加上w2的第三个元素,但是w2没有第三个元素,所以这时候就会进行循环,w1的第三个元素6加上w2的第一个元素10,所以等于16;同理,w1的第四个元素8加上w2的第二个元素12等于20.
注意:如果两个向量的长度不同,R将利用循环规则,该规则重复较短的向量元素,直到得到的向量长度与较长的向量的长度一样
- 等差数列的创建
> seq(1,-9);seq(1.9) # 只给出首项和尾项,by自动匹配为1或-1
[1] 1 0 -1 -2 -3 -4 -5 -6 -7 -8 -9
[1] 1
> seq(1,-9,length.out = 5) # 给出首项和尾项数据以及长度,自动计算等差
[1] 1.0 -1.5 -4.0 -6.5 -9.0
> seq(1,-9,by=-2) # 给出首项和尾项数据以及步长,自动计算长度
[1] 1 -1 -3 -5 -7 -9
> seq(1,by=2,length.out = 10) # 给出首项和步长以及长度数据,自动计算尾项
[1] 1 3 5 7 9 11 13 15 17 19
归纳:向量是一维的数据,但是在日常生活中很多数据是二维或者多维的数据,接下来介绍矩阵和数据框。
矩阵
矩阵是一个二维数组,每个元素都拥有相同的模式(数值型、字符型或逻辑型)。可以通过函数matrix创建矩阵。
一般的使用格式为:
mymatrix<-matrix(vector,nrow = number_of_rows,ncol = number_of_columns,
byrow = logical_value,dimnames = list(char_vector_rownames,char_vector_colnames))
其中,vector包含矩阵的元素,nrow和ncol用以指定行和列的维数,dimnames包含了可选的、以字符型向量表示的行名和列名。选项byrow则表明矩阵应当按行填充(byrow=TRUE)还是按列填充(byrow=FALSE),默认情况下是按列填充
- 创建矩阵
代码清单
w<-seq(1,10)
(a<-matrix(w,nrow=5,ncol=2))# nrow和ncol用以指定行和列的维数
(b<-matrix(w,nrow = 5,ncol = 2,byrow = T)) # 按行填充
(d<-matrix(w,nrow=5,ncol = 2,byrow = T,dimnames = list(paste0("r",1:5),paste0(list("l",1:2))))) #给行和列设置名称
> (a<-matrix(w,nrow=5,ncol=2))#
[,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10
> (b<-matrix(w,nrow = 5,ncol = 2,byrow = T))
[,1] [,2]
[1,] 1 2
[2,] 3 4
[3,] 5 6
[4,] 7 8
[5,] 9 10
> (d<-matrix(w,nrow=5,ncol = 2,byrow = T,dimnames = list(paste0("r",1:5),paste0(list("l",1:2)))))
l 1:2
r1 1 2
r2 3 4
r3 5 6
r4 7 8
r5 9 10
- 矩阵下标的使用
我们可以使用下表和方括号来选择矩阵中的行、列或元素。x[i,]选择矩阵x中的第i行,x[,j]选择矩阵x中的第j列,x[i,j]选择矩阵x中的第i行第j列的元素。选择多行或多列的时候,下标i和j可为数值型向量
(m<-matrix(1:20,nrow=4))
(mr2<-m[2,])# 选择第2行
(mc4<-m[,4]) #选择第4列
(m45<-m[4,5]) #选择第4行第5列的元素
(mk<-m[c(1,2),c(1,2)])# 选择前两行和前两列的元素
> (m<-matrix(1:20,nrow=4))
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> (mr2<-m[2,])# 选择第2行
[1] 2 6 10 14 18
> (mc4<-m[,4]) #选择第4列
[1] 13 14 15 16
> (m45<-m[4,5]) #选择第4行第5列的元素
[1] 20
> (mk<-m[c(1,2),c(1,2)])# 选择前两行和前两列的元素
[,1] [,2]
[1,] 1 5
[2,] 2 6
- 矩阵的合并
# 矩阵的合并
(x1<-rbind(c(1,2),c(3,4)))
(x2<-10+x1)
(x3<-cbind(x1,x2))# 列合并,小的矩阵合并成更宽的矩阵
(x4<-rbind(x1,x2)) # 行合并,小的矩阵合并成更长的矩阵
cbind(1,x1)
rbind(1,x1)
> (x1<-rbind(c(1,2),c(3,4)))
[,1] [,2]
[1,] 1 2
[2,] 3 4
> (x2<-10+x1)
[,1] [,2]
[1,] 11 12
[2,] 13 14
> (x3<-cbind(x1,x2))#
[,1] [,2] [,3] [,4]
[1,] 1 2 11 12
[2,] 3 4 13 14
> (x4<-rbind(x1,x2)) #
[,1] [,2]
[1,] 1 2
[2,] 3 4
[3,] 11 12
[4,] 13 14
> cbind(1,x1)
[,1] [,2] [,3]
[1,] 1 1 2
[2,] 1 3 4
> rbind(1,x1)
[,1] [,2]
[1,] 1 1
[2,] 1 2
[3,] 3 4
数组
在R语言中,可以认为数组是矩阵的扩展,它将矩阵扩展到2维以上。如果给定的数组是一维的,则相当于向量,二维的相当于矩阵。
数组可以通过array函数创建,格式如下:
myarray<-array(vector,dimensions,dimnames)
其中vector包含数组中的数据,dimensions是一个数值型向量,给出各个维度下标的最大值,而dimnames是可选的,各维度名称的列表。
创建数组
ar1<-array(1:3)#相当于一维的向量:1 2 3
ar2<-array(1:6,dim = c(2,3))#相当于2行3列的矩阵
ar3<-array(1:24,dim = c(3,4,2))#相当于创建3×4×2维的数组
#给出各维度的名称标签
dim1<-c("a1","a2")
dim2<-c("b1","b2","b3")
dim3<-c("C1","C2","C3","C4")
myarray<-array(1:24,c(2,3,4),dimnames = list(dim1,dim2,dim3))
myarray
> myarray
, , C1
b1 b2 b3
a1 1 3 5
a2 2 4 6
, , C2
b1 b2 b3
a1 7 9 11
a2 8 10 12
, , C3
b1 b2 b3
a1 13 15 17
a2 14 16 18
, , C4
b1 b2 b3
a1 19 21 23
a2 20 22 24
选取数组中的元素
myarray[1,2,3]#获取单个元素的值
myarray["a1","b1","C1"]#通过维度的名称来获取元素值
myarray[1,,]#组合元素值,获取第1个维度的第一个水平的所有组合元素值
myarray[2,1,]#获取第1个维度的第2个水平和第2个维度的第1个水平的所有元素值
> myarray[1,2,3]#获取单个元素的值
[1] 15
> myarray["a1","b1","C1"]
[1] 1
> myarray[1,,]
C1 C2 C3 C4
b1 1 7 13 19
b2 3 9 15 21
b3 5 11 17 23
> myarray[2,1,]#获取第1个维度的第2个水平和第2个维度的第1个水平的所有元素值
C1 C2 C3 C4
2 8 14 20
数据框
由于不同的列可以包含不同的模式(数值型、字符型等)的数据,数据框的概念较矩阵来说更为一般。
- 读取excel/txt等格式数据集的时候,也是以数据框对象输入
- 数据分析算法函数的输入对象都是数据框对象
- 数据框可通过==data.frame()==创建
常用的格式
mydata<-data.frame(col1,col2,col3,……)
其中的列向量col1,col2,col3,……可谓任何类型(如字符型、数值型或逻辑型)。每一列的名称可由函数names指定。
创建数据框
site<-c("a","b","c","d","e")
number<-c(1:5)
luoji<-c(T,F,T,F,T)
(DT<-data.frame(site,number,luoji))
names(DT)#读取数据框的列名
names(DT)[1]<-"Aw" #修改第一列列名为Aw
names(DT)
> (DT<-data.frame(site,number,luoji))
site number luoji
1 a 1 TRUE
2 b 2 FALSE
3 c 3 TRUE
4 d 4 FALSE
5 e 5 TRUE
> names(DT)#读取数据框的列名
[1] "site" "number" "luoji"
> names(DT)[1]<-"Aw" #修改第一列列名为Aw
> names(DT)
[1] "Aw" "number" "luoji"
注意:每一列的数据的模式必须唯一,不过你却可以将多个模式的不同列放到一起组成数据框。
选取数据框的元素
选取数据框中元素的方式有若干种,可以使用前述(如矩阵)下标记号,亦可直接指定列名。
DT[1:2]# 下标的方式
DT[c("Aw","luoji")] # 指定列名
DT$Aw #记号$
第三个例子中的记号$是新出现的,它被用来选取一个给定数据框的某个特定变量。
> DT[1:2]
Aw number
1 a 1
2 b 2
3 c 3
4 d 4
5 e 5
> DT[c("Aw","luoji")]
Aw luoji
1 a TRUE
2 b FALSE
3 c TRUE
4 d FALSE
5 e TRUE
> DT$Aw
[1] a b c d e
如果想要生成Aw和luoji两个变量的列联表,以下代码可以实现
> table(DT$Aw,DT$luoji)
FALSE TRUE
a 0 1
b 1 0
c 0 1
d 1 0
e 0 1
每个变量名前都键入一次DT很浪费时间,可以采用attach()函数和detach()函数来实现。其中attach()是将数据框绑定到R的搜索路径中,R中遇到一个变量名以后,将检查搜索路径中的数据框,以定位到这个变量。detach()是解除绑定。
attach(DT)
table(Aw,luoji)
detach(DT) # 解除绑定
因子
变量可归结为名义型、有序型或连续型变量。名义型变量是没有顺序之分的类别变量。糖尿病类型Diabetes(Type1、Type2)是名义型变量的一例。即使在数据中Type1编码为1而Type2编码为2,这也并不意味着二者是有序的。有序型变量表示一种顺序关系,而非数量关系。病情Status(poor, improved, excellent)是顺序型变量的一个上佳示例。我们明白,病情为poor(较差)病人的状态不如improved(病情好转)的病人,但并不知道相差多少。连续型变量可以呈现为某个范围内的任意值,并同时表示了顺序和数量。年龄Age就是一个连续型变量,它能够表示像14.5或22.8这样的值以及其间的其他任意值。很清楚,15岁的人比14岁的人年长一岁。类别(名义型)变量和有序类别(有序型)变量在R中称为因子(factor)
函数factor()以一个整数向量的形式存储类别值,整数的取值范围是[1… k ](其中k 是名义型变量中唯一值的个数),同时一个由字符串(原始值)组成的内部向量将映射到这些整数上。
名义型变量
diabetes<-c("Type1","Type2","Type3","Type1")
语句diabetes <- factor(diabetes)将此向量存储为(1, 2, 1, 1),并在内部将其关联为1=Type1和2=Type2(具体赋值根据字母顺序而定)。针对向量diabetes进行的任何分析都会将其作为名义型变量对待,并自动选择适合这一测量尺度的统计方法。
> diabetes<-c("Type1","Type2","Type3","Type1")
> diabetes<-factor(diabetes)
> mode(diabetes)
[1] "numeric"
> diabetes
[1] Type1 Type2 Type3 Type1
Levels: Type1 Type2 Type3
有序型变量
要表示有序型变量,需要为函数factor()指定参数ordered=TRUE。
state<-c("Poor","Imporoved","Excellent","Poor")
> status<-factor(status,ordered = TRUE)
> mode(status)
[1] "numeric"
> status
[1] Poor Excellent Improved Poor
Levels: Excellent < Improved < Poor
语句status <- factor(status, ordered=TRUE)会将向量编码为(3, 2, 1, 3),并在内部将这些值关联为1=Excellent、2=Improved以及3=Poor。另外,针对此向量进行的任何分析都会将其作为有序型变量对待,并自动选择合适的统计方法。
对于字符型向量,因子的水平默认依字母顺序创建。这对于因子status是有意义的,因为“Excellent”、“Improved”、“Poor”的排序方式恰好与逻辑顺序相一致。如果“Poor”被编码为“Ailing”,会有问题,因为顺序将为“Ailing”、“Excellent”、“Improved”。如果理想中的顺序是“Poor”、“Improved”、“Excellent”,则会出现类似的问题。按默认的字母顺序排序的因子很少能够让人满意。
可以通过指定levels选项来覆盖默认排序
newstatus<-factor(status,ordered = TRUE,levels = c("Poor","Improved","Excellent"))
newstatus
[1] Poor Excellent Improved Poor
Levels: Poor < Improved < Excellent
各水平的赋值将为1=Poor、2=Improved、3=Excellent。请保证指定的水平与数据中的真实值相匹配,因为任何在数据中出现而未在参数中列举的数据都将被设为缺失值。
创建因子
patientid<-c(1:4)
diabetes<-c("Type1","Type2","Type3","Type1")
status<-c("Poor","Excellent","Improved","Poor")
diabetes<-factor(diabetes)
status<-factor(status,ordered = TRUE)
#将数据合并为一个数据框
patientdata<-data.frame(patientid,diabetes,status)
str(patientdata)#输出对象的结构
summary(patientdata)#显示对象的统计概要
> str(patientdata)#输出对象的结构
'data.frame': 4 obs. of 3 variables:
$ patientid: int 1 2 3 4
$ diabetes : Factor w/ 3 levels "Type1","Type2",..: 1 2 3 1
$ status : Ord.factor w/ 3 levels "Excellent"<"Improved"<..: 3 1 2 3
> summary(patientdata)#显示对象的统计概要
patientid diabetes status
Min. :1.00 Type1:2 Excellent:1
1st Qu.:1.75 Type2:1 Improved :1
Median :2.50 Type3:1 Poor :2
Mean :2.50
3rd Qu.:3.25
Max. :4.00
首先,以向量的形式输入了数据。然后,将diabetes和status分别指定为一个普通因子和一个有序型因子。最后,将数据合并为一个数据框。函数str(object)可提供R中某个对象(本例中为数据框)的信息。它清楚地显示diabetes是一个因子,而status是一个有序型因子,以及此数据框在内部是如何进行编码的。
注意,函summary()会区别对待各个变量。它显示了连续型变量=的最小值、最大值、均值和各四分位数,并显示了类别型变量diabetes和status(各水平)的频数值。
列表
R语言中的列表与R语言中的向量、数组和矩阵不同,它的每个分量的数据类型可以是不同的
列表是对象的集合,可以包含向量、矩阵、数组,数据框,甚至是另外一个列表,且在列表中要求每一个成分都要有一个名称。
列表中的对象又称为它的分量(components)。
在R语言中可以使用==list()==函数来创建列表,其语法格式为:
mylist<-list(name1=object1,name2=object2,……)
创建列表
a<-c("A同学","B同学","c同学")
b<-c("数学","计算机","英语")
e<-c(88,89,99)
mylist<-list(st.name=a,major.course=b,test.grade=e)
mylist
$st.name
[1] "A同学" "B同学" "c同学"
$major.course
[1] "数学" "计算机" "英语"
$test.grade
[1] 88 89 99
列表的索引
mylist[1]#访问列表中的第一个成分,返回结果为一个列表
mylist[[1]]#访问列表中的第一个成分的元素值,这次仅是元素值,是向量,不是列表
mylist[[1]][1]#访问列表中的第一个成分的第一个元素值
mylist[[1:2]]#访问列表中的第一个到第二个成分
mylist[c(1,3)]#访问列表中的第一个和第三个成分
mylist$st.name#访问列表中名称为st.name的元素值
mylist$st.name[1]#访问列表中名称为st.name中的第一个元素值
mylist["major.course"]#访问列表中名称为major的成分,其结果为一个列表
mylist[["major.course"]]#访问列表中名称为major的元素值
mylist["major.course"][1]#访问列表中名称为st.name中的第一个元素值
编辑列表
- 修改某个成分的元素值
mylist[[1]][1] = '李小东'
mylist$st.name[2] = '黄铭'
mylist[["st.name"]][3] = '陆远风'
mylist
$st.name
[1] "李小东" "黄铭" "陆远风"
$major.course
[1] "数学" "计算机" "英语"
$test.grade
[1] 88 89 99
- 修改某一成分的所有值
mylist$major.course = c("数学分析","计算机思维与结构", "大学英语")
mylist[[3]] = c(88.3,89.2,99.1)
mylist
$st.name
[1] "李小东" "黄铭" "陆远风"
$major.course
[1] "数学分析" "计算机思维与结构" "大学英语"
$test.grade
[1] 88.3 89.2 99.1
- 添加一个成分
mylist$no<-c(1601,1602,1603)
mylist<-c(mylist,hobby = list(c("篮球","排球","羽毛球")))
- 删除某一个成分
mylist$st.name = NULL
mylist[1] = NULL
mylist[-1]
数据的读取
读取文本文件
# 数据的导入
# 设置工作路径
setwd("D:/data")
getwd()
# 另外一种路径的设置
#setwd("D:\\data")
#文本文件的导入
importtxt<-read.table("iris.txt",header = TRUE)
#header=TRUE表示数据文件第一行中带有变量名。因为table默认的分隔符是空格,和txt一致,所以不需要进行分隔符的参数设置
importcsv<-read.table("iris.csv",header=T,sep=",")
#默认情况下,R语言会认为第一行的是数据的标题,假如你的数据的第一行并不是标题,可以设置header=F
#对于csv文件,还可以利用read.csv读取
importcsv2<-read.csv("iris.csv",header = T)
#查看前5行,默认是前6行
head(importtxt[c(1:5),])
head(importcsv2)
> head(importtxt[c(1:5),])
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
> head(importcsv2)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
读取非结构化文本文件
使用readLines()函数,按行读入数据
# 读取非结构化文本文件,每行的长度都不一样
unstructuredtxt<-readLines("unstructuredText.txt")
unstructuredtxt
> unstructuredtxt
[1] "R语言是一套开源的数据分析解决方案,几乎可以独立完成数据处理、数据可视化、数据建模及模型评估等工作,而且可以完美配合其他工具进行数据交互。具体来说,R语言具有以下优势:"
[2] "1)高效的数据处理能力"
[3] "2)数据分析"
[4] "3)数据可视化"
[5] "4)通过庞大的R程序包库文件进行扩展"
读取网络数据
网址:http://www.justinmrao.com/salary_data.csv
salarydata<-read.csv("http://www.justinmrao.com/salary_data.csv")
head(salarydata[c(1:3),])
> head(salarydata[c(1:3),])
team year player contract_years_remaining contract_thru position full_name
1 Boston Celtics 2002-03 Bremer, J.R. 1 2002-03 G Bremer
2 Cleveland Cavaliers 2003-04 Bremer, J.R. 1 2003-04 G Bremer
3 Charlotte Hornets 2001-02 Brown, P.J. 7 2002-03 F Brown
salary_year salary_total year_counter obs mean_salary mean_remaining
1 349458 349458 1 2 456568.5 1
2 563679 563679 2 2 456568.5 1
3 6404800 36000000 1 6 7668267.0 5
R语言的基础绘图
散点图
普通散点图
par(mfrow=c(1,2)) # 绘制一行两列的散点图
plot(x=rnorm(10))
plot(women)

散点图矩阵
plot(iris[,1:4],main="利用plot函数绘制散点图矩阵")
pairs(iris[,1:4],main="利用pairs函数绘制散点图矩阵")

柱状图和条形图
#柱状图和条形图
par(mfrow=c(1,2))
for (i in c(F,T)) {barplot(VADeaths,horiz = i,beside = T,col = rainbow(5))
}#当horiz=T,绘制条形图,F则绘制柱状图

绘制饼图
pie(table(mtcars$cyl))#绘制饼图

绘制Q-Q图
qqnorm(economics$psavert)
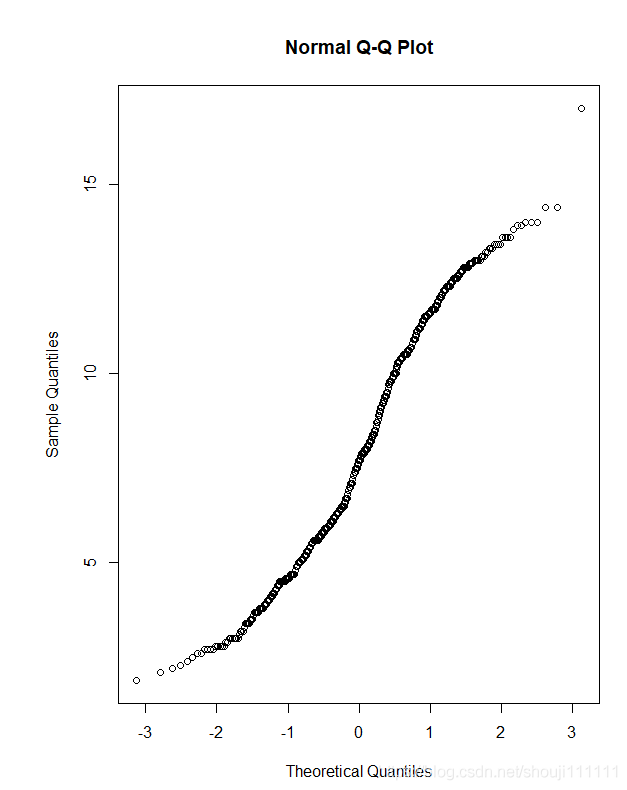
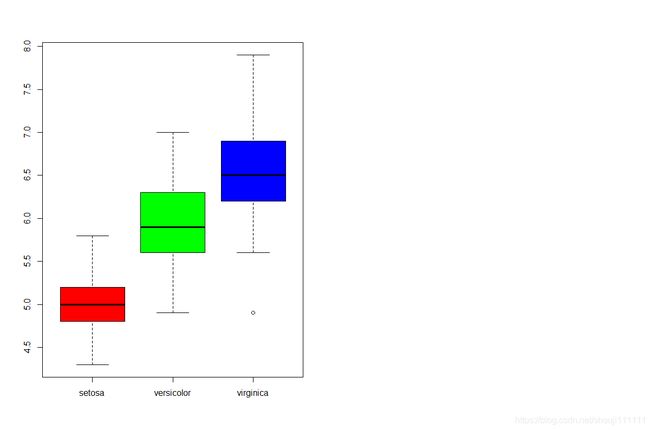
箱线图
boxplot(iris$Sepal.Length~iris$Species,col=rainbow(3))
茎叶图
> stem(mtcars$wt)
The decimal point is at the |
1 | 5689
2 | 123
2 | 56889
3 | 22224444
3 | 55667888
4 | 1
4 |
5 | 334
点图
#点图
dotchart(mtcars$mpg,labels = rownames(mtcars))

R语言描述性统计分析
- 平均数
> xmean<-mean(x)
> (xmean<-mean(x))
[1] 5.5
- 中位数
> (xmedian<-median(x))
[1] 5.5
- 百分位数
- 描述性统计函数
- summary()函数
> vars<-c("mpg","hp","wt")#重点关注每加仑汽油行驶英里数(mpg)、马力(hp)和车重(wt)
> summary(mtcars[vars])
mpg hp wt
Min. :10.40 Min. : 52.0 Min. :1.513
1st Qu.:15.43 1st Qu.: 96.5 1st Qu.:2.581
Median :19.20 Median :123.0 Median :3.325
Mean :20.09 Mean :146.7 Mean :3.217
3rd Qu.:22.80 3rd Qu.:180.0 3rd Qu.:3.610
Max. :33.90 Max. :335.0 Max. :5.424
> summary(iris[,5])# 对因子变量进行频数统计
setosa versicolor virginica
50 50 50
- Hmisc包中的describe()函数
library(Hmisc)
describe(mtcars[vars])
mtcars[vars]
3 Variables 32 Observations
---------------------------------------------------------------------------------------------------------
mpg
n missing distinct Info Mean Gmd .05 .10 .25 .50 .75
32 0 25 0.999 20.09 6.796 12.00 14.34 15.43 19.20 22.80
.90 .95
30.09 31.30
lowest : 10.4 13.3 14.3 14.7 15.0, highest: 26.0 27.3 30.4 32.4 33.9
---------------------------------------------------------------------------------------------------------
hp
n missing distinct Info Mean Gmd .05 .10 .25 .50 .75
32 0 22 0.997 146.7 77.04 63.65 66.00 96.50 123.00 180.00
.90 .95
243.50 253.55
lowest : 52 62 65 66 91, highest: 215 230 245 264 335
---------------------------------------------------------------------------------------------------------
wt
n missing distinct Info Mean Gmd .05 .10 .25 .50 .75
32 0 29 0.999 3.217 1.089 1.736 1.956 2.581 3.325 3.610
.90 .95
4.048 5.293
lowest : 1.513 1.615 1.835 1.935 2.140, highest: 3.845 4.070 5.250 5.345 5.424
---------------------------------------------------------------------------------------------------------
参考资料
- Robert Kabacoff. Data Analysis and Graphics with R[M]. The United States of America:Manning Publications.2011.
- 高涛,肖楠,陈钢. R语言实战[M]. 北京:人民邮电出版社, 2013.
- 天善智能_R语言快速入门
- https://baijiahao.baidu.com/s?id=1609504979912550722&wfr=spider&for=pc
- https://baijiahao.baidu.com/s?id=1578027914319223370&wfr=spider&for=pc
- https://baijiahao.baidu.com/s?id=1609601023572921783&wfr=spider&for=pc
- https://jingyan.baidu.com/article/48a42057ef3ba2a924250429.html
- https://www.cnblogs.com/xuancaoyy/p/5309966.html