理解布隆过滤器并不难
布隆过滤器(BloomFilter)
- 1. 布隆过滤器(BloomFilter)
-
- 1.1 介绍
- 1.2 数据结构
- 1.3 运行过程
- 1.4 小节
- 2. 布隆过滤器的实现
-
- 2.1 Guava BloomFilter
-
- 2.1.1 构造过滤器
- 2.1.2 使用过滤器
- 2.2 Redis BloomFilter
-
- 2.2.1 自己实现
- 2.2.2 Redisson实现
- 3. 应用场景
- 4. 问题
1. 布隆过滤器(BloomFilter)
1.1 介绍
布隆过滤器(BloomFilter)是一个数据结构。借助它可以快速地判断出指定的元素是否存在于集合之中,并且它占用的空间很小。
布隆过滤器有着高效的插入和查询性能(时间复杂度为O(k),k代表的是hash次数),然而它是一个基于概率的数据结构,它只能告诉我们,指定的元素可能存在于集合中,或一定不存在于集合中。
1.2 数据结构
布隆过滤器的基础数据结构是一个比特向量(Bit Vector),可以理解为一个bit数组,该数组中每个元素的初始值都是0。
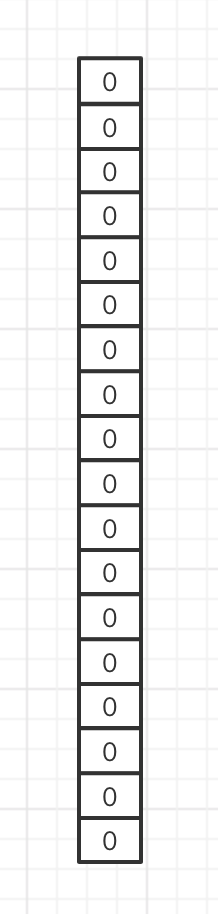
1.3 运行过程
假设我们已有一组数据(例如DB中存在10条数据),这时候过来一个查询(如查询ID=20的数据),那此时我们怎么能不经过DB查询从而快速地知道这个ID=20的数据是否存在于DB中呢?
最容易想到的,就是把这些DB中已存在的数据的ID读出来放到一个Set中,然后利用set.contains()方法来判断指定元素是否存在于集合中,若不存在,则等价地认为它同样不存在于DB中。
利用布隆过滤器的操作与上面一样(可以理解布隆过滤器就是上面的Set集合的角色),但它内部有一套独特的运行机制。
在把数据放入布隆过滤器时,需要经过n次hash,每次得到的hashCode对bit数组长度取余(hashCode % bitArr.length)得到一组index,之后将index对应的数组元素的值改为1。
判断一个元素是否存在,其过程和上面类似,同样把指定元素经过n次hash,得到一组hashCode,再依次对bit数组长度取余得到一组index,若这组index对应的数组元素的值都是1,那么认为该元素可能存在;若对应的数组元素的值有0,那么认为该元素一定不存在。
假设我们将字符串"hello"放入过滤器,需要经过三次hash。
将已有元素——字符串“hello”放入过滤器,三个箭头表示三次hash并取余之后,指向的数组下标,对应元素已从0改为1.
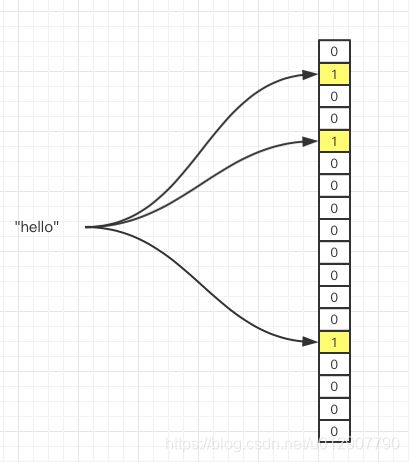
给定元素——字符串“world”,判断是否在集合中。因为哈希取余的结果不全都是1,因此该元素一定不在集合中。

给定字符串——“demo”,判断是否存在集合中。此时我们假设,“demo”经过hash取余后,恰好映射到的元素都为1,从肉眼可见,“demo”实际上是不存在于集合之中的,因此,当映射到的元素都为1时,布隆过滤器只能告诉你该元素可能存在。
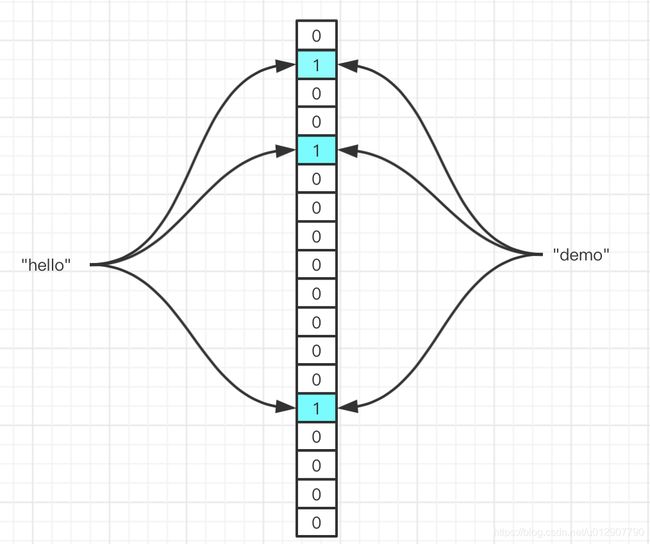
由此可见,布隆过滤器是存在一定的误判的。那么什么会影响到判断的正确性呢?
-
hash次数
hash的次数越多,一个数据映射到数组中的元素就越多,当判断指定元素是否存在时,就有更多的机会“纠正”实际不存在的数据但映射到的元素都是1的情况,出现误判的机率会变小。
-
bit向量的位数(数组长度)
数组长度越大,hash散列就越分散,出现“碰撞”的机率也就降低了。
-
过滤器中已存在的元素个数
这里涉及到一个背景,就是布隆过滤器“只进不出”,也就是说,数据添加到布隆过滤器后,就不能移除了。例如原来有A、B、C三个数据塞入了过滤器中,后续B从DB中移除了,但我们无法将B从过滤器中移除;DB中新增的元素D会同步添加到过滤器中,随着元素的增加,过滤器会慢慢“塞满”,数组的中值为1的元素越来越多,会降低后续判断的准确性。
hash次数,会影响计算时间,次数越多越慢;bit向量位数会影响过滤器对内存的消耗;因此,在使用布隆过滤器时需要在误判率(false positive probability,fpp)、hash次数、bit向量位数之间进行取舍。
在初始化布隆过滤器时,用户能指定两个参数,一个是期望添加的数据个数(expectedInsertions),表示已经存在的真实数据的个数(如DB中已有10条数据,那么expectedInsertions = 10);另一个是期望的误判率(fpp)。过滤器的内部实现中,会依据一套数学公式,利用expectedInsertions和fpp推导出bit向量位数(bitNums);再利用另一套数学公式,结合expectedInsertions和bitNums推导出hash次数(numHashFunctions)。
具体数学证明,可以参考
http://llimllib.github.io/bloomfilter-tutorial/
1.4 小节
至此,浮现出了几个和布隆过滤器相关的关键词:bit向量(Bit Vector)、期望添加的数据个数(expectedInsertions)、期望的误判率(fpp)、bit向量位数(bitNums)、hash次数。
2. 布隆过滤器的实现
2.1 Guava BloomFilter
Guava中提供了布隆过滤器的实现BloomFilter。
/** The bit set of the BloomFilter (not necessarily power of 2!) */
/** bit数组,内部封装了AtomicLongArray,线程安全 */
private final LockFreeBitArray bits;
/** Number of hashes per element */
/** 每个元素的hash次数 */
private final int numHashFunctions;
/** The funnel to translate Ts to bytes */
/** 用于配合Guava Hashings实现hash过程,在此可以忽略 */
private final Funnel<? super T> funnel;
/** The strategy we employ to map an element T to {@code numHashFunctions} bit indexes. */
/** 处理元素的具体策略 */
private final Strategy strategy;
2.1.1 构造过滤器
使用BloomFilter的静态create()方法构造一个布隆过滤器。
public static <T> BloomFilter<T> create(
Funnel<? super T> funnel, int expectedInsertions, double fpp) {
return create(funnel, (long) expectedInsertions, fpp);
}
-
Funnel
Guava中已经预设好了一组Funnel,在Funnels类中提供,我们根据需要选择一个就好。
-
expectedInsertions
期望添加的数据量。指的是希望加入到过滤器中的真实数据的个数,如希望添加10条数据,那么expectedInsertions = 10。注意,该数值必须大于0。
-
fpp
期望的误判率。表示期望过滤器有多大概率会发生误判,数值越小,判断精度越高。该数值必须大于0且小于1。
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 10000, 0.1);
我们深入到creat()方法内部来看:
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter<T>(new LockFreeBitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e);
}
其中有两个重要的方法:
-
optimalNumOfBits(expectedInsertions, fpp)
利用数学公式,结合expectedInsertions和fpp推导出bit向量的位数,numBits。
static long optimalNumOfBits(long n, double p) { if (p == 0) { p = Double.MIN_VALUE; } return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2))); } -
optimalNumOfHashFunctions(expectedInsertions, numBits)
利用数学公式,结合expectedInsertions和numBits推导出hash次数,numHashFunctions
这两个方法计算出的numBits和numHashFunctions是利用数学公式,对过滤器的性能和准确性的权衡得出。
2.1.2 使用过滤器
对布隆过滤器的操作,主要是put()和mightContain()方法。
-
put()
put()方法用于将已存在的数据放入过滤器中。数据放入过滤器时,会经过几次hash取模,将bit数组对应元素的值设置为1的过程。
public <T> boolean put( T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits) { long bitSize = bits.bitSize(); byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal(); long hash1 = lowerEight(bytes); long hash2 = upperEight(bytes); boolean bitsChanged = false; long combinedHash = hash1; for (int i = 0; i < numHashFunctions; i++) { // Make the combined hash positive and indexable bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize); combinedHash += hash2; } return bitsChanged; }Guava利用内置的Hashing.murmur3_128()实现hashCode的计算,它得到一个长度为16的字节数组(128bit)。
之后将该byte数组一分为二,八个字节为一个long,得到两个long型hash值。
开始for循环,循环次数即前面计算得到的hash次数,这里注意到利用了双重哈希的方式(combinedHash += hash2;),每一轮循环都让原hash值累加hash2。这种操作多用于开放寻址法解决hash碰撞。
由于hash值可能是负的,在与bitSize取模之前,必须要变为正数,否则取到的数组index将会是负数。这里使用的操作是
combinedHash & Long.MAX_VALUE,可以联想一下HashMap中的 hash & (length - 1),这里的核心思想就是利用按位与操作,将负数的符号位1与正数的符号位0相与,得到新的符号位0,即完成了负转正的操作。得到数组index后,再将对应元素的值改为1即可。
-
mightContain
mightContain()方法的过程和put()几乎一致,不同的是,求的index后,会在bit数组中取出index对应元素的值,如果取出的值中有0,即认为指定数据一定不存在于过滤器中,方法直接返回false;若取出的值都是1,则认为指定数据可能存在于过滤器中。
public <T> boolean mightContain( T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits) { long bitSize = bits.bitSize(); byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal(); long hash1 = lowerEight(bytes); long hash2 = upperEight(bytes); long combinedHash = hash1; for (int i = 0; i < numHashFunctions; i++) { // Make the combined hash positive and indexable if (!bits.get((combinedHash & Long.MAX_VALUE) % bitSize)) { return false; } combinedHash += hash2; } return true; }
下面是一个完整的demo:
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 10000, 0.1);
for (int i = 0; i < 10000; i++) {
bloomFilter.put(i);
}
boolean result = bloomFilter.mightContain(10010);
System.out.println("数据存在吗?" + result);
2.2 Redis BloomFilter
可以利用Redis的bitmap实现布隆过滤器。涉及到的api是setbit和getbit。
整体思路和上面的Guava实现是一样的,只不过把对本地bit数组的操作替换成了对redis bitmap的操作。
2.2.1 自己实现
代码如下:
import com.google.common.base.Charsets;
import com.google.common.hash.Hashing;
import com.google.common.primitives.Longs;
import org.springframework.util.StringUtils;
import redis.clients.jedis.Jedis;
public class RedisBloomFilter {
private static final Jedis jedis = new Jedis("127.0.0.1", 6379);
/** bit数组元素的个数 */
private final long bitNums;
/** hash次数 */
private final int hashFunctionNums;
private final String filterName;
private RedisBloomFilter(long bitNums, int hashFunctionNums, String filterName) {
this.bitNums = bitNums;
this.hashFunctionNums = hashFunctionNums;
this.filterName = filterName;
}
/** 构造布隆过滤器 */
public static RedisBloomFilter build(int expectedInsertions, double fpp, String filterName) {
if (expectedInsertions < 0) {
throw new IllegalArgumentException("expectedInsertions 必须大于0");
}
if (expectedInsertions == 0) {
expectedInsertions = 1;
}
if (fpp >= 1.0) {
throw new IllegalArgumentException("fpp 必须 小于 1.0");
}
if (StringUtils.isEmpty(filterName)) {
throw new IllegalArgumentException("filterName 不能为空");
}
long numOfBits = optimalNumOfBits(expectedInsertions, fpp);
int numOfHashFunctions = optimalNumsOfHashFunctions(expectedInsertions, numOfBits);
return new RedisBloomFilter(numOfBits, numOfHashFunctions, filterName);
}
public void put(String key) {
byte[] bytes = Hashing.murmur3_128().hashString(key, Charsets.UTF_8).asBytes();
long hash1 = lowerEights(bytes);
long hash2 = higherEights(bytes);
long combinedHash = hash1;
for (int i = 0; i < hashFunctionNums; i++) {
long offset = (combinedHash & Long.MAX_VALUE) % bitNums;
jedis.setbit(filterName, offset, true);
combinedHash += hash2;
}
}
public boolean mightContains(String key) {
byte[] bytes = Hashing.murmur3_128().hashString(key, Charsets.UTF_8).asBytes();
long hash1 = lowerEights(bytes);
long hash2 = higherEights(bytes);
long combinedHash = hash1;
for (int i = 0; i < hashFunctionNums; i++) {
long offset = (combinedHash & Long.MAX_VALUE) % bitNums;
if (!jedis.getbit(filterName, offset)) {
return false;
}
combinedHash += hash2;
}
return true;
}
private long lowerEights(byte[] bytes) {
return Longs.fromBytes(bytes[7], bytes[6], bytes[5], bytes[4], bytes[3], bytes[2], bytes[1], bytes[0]);
}
private long higherEights(byte[] bytes) {
return Longs.fromBytes(bytes[15], bytes[14], bytes[13], bytes[12], bytes[11], bytes[10], bytes[9], bytes[8]);
}
private static long optimalNumOfBits(long expectedInsertions, double fpp) {
if (fpp == 0) {
fpp = Double.MIN_VALUE;
}
return (long) (-expectedInsertions * Math.log(fpp) / (Math.log(2) * Math.log(2)));
}
private static int optimalNumsOfHashFunctions(long expectedInsertions, long numOfBits) {
return Math.max(1, (int) Math.round((double) numOfBits / expectedInsertions * Math.log(2)));
}
2.2.2 Redisson实现
Redisson中已经提供了对BloomFilter的实现,
https://github.com/redisson/redisson/wiki/6.-distributed-objects#68-bloom-filter
RBloomFilter<SomeObject> bloomFilter = redisson.getBloomFilter("sample");
// initialize bloom filter with
// expectedInsertions = 55000000
// falseProbability = 0.03
bloomFilter.tryInit(55000000L, 0.03);
bloomFilter.add(new SomeObject("field1Value", "field2Value"));
bloomFilter.add(new SomeObject("field5Value", "field8Value"));
bloomFilter.contains(new SomeObject("field1Value", "field8Value"));
bloomFilter.count();
3. 应用场景
布隆过滤器典型的应用场景是防范缓存穿透。我们在DB上层加一层布隆过滤器,若请求的key判定为在过滤器中一定不存在,那么请求可以直接返回,不会落到DB上,从而保护DB。
下面是伪代码:
Object value = cache.get("key");
if (value == null) {
boolean mightContain = bloomFilter.mightContain("key");
if (!mightContain) {
return new DefaultValue();
} else {
value = db.select("key");
}
}
4. 问题
-
使用布隆过滤器需要考虑过滤器本身占用的内存空间的问题,防止过大的空间占用
-
布隆过滤器只能添加不能删除,数组中的1越来越多,误判率越老越高,咋办?
-
redis实现布隆过滤器需要考虑bitmap的大小限制(一个bitmap最多2^32 bit,即512M),以及读写性能
https://redis.io/commands/setbit
-
Redis Cluster对布隆过滤器的影响?