视频换脸-Deepfakes代码解读和训练说明
Faceswap
Faceswap是一种利用深度学习手段来交换图片和视频中的面孔的工具。
本文可以帮助对此目标感兴趣的深度学习爱好者了解强化学习模型GAN(生成对抗网络),同时还涉及人脸检测和特征点提取等相关内容。
首先本文对如何利用GAN进行faceswap的原理进行说明,其次对训练过程给出了说明,最后对模型存在的问题进行了分析,希望以后有时间可以进行改进。
刚刚开始写博客,欢迎大家评论,如果大家对训练过程有什么问题,欢迎提问,我会积极回答大家的提问。
我的项目地址:https://github.com/luckyluckydadada/faceswap
(原理清晰,注释完整,如果觉得对您有帮助,github上给点个star,谢谢了。)
代码参考:https://github.com/deepfakes/faceswap(原作者)
目录
1 目标
2 人脸识别科普
3 实现流程图
4 后续改进
5 用到的工具
6 应用前景
7 代码使用举例
8 参看文档
1 目标
1.1 主目标
实现视频中的人物被换脸
1.2 子目标
人脸检测 Detection
人脸校准 Alignment
人脸Decoder/Encoder (将一张脸训练成另一张脸)
视频与图像的互相转换
2 人脸识别科普
人脸识别任务主要分为4大板块:
- Detection - 识别出人脸位置
- Alignment -人脸上的特征点定位
- Verification -人脸校验
- Identification(Recognization) -人脸识别
后两者的区别在于,人脸校验是要给你两张脸问你是不是同一个人,人脸识别是给你一张脸和一个库问你这张脸是库里的谁。
此次faceswap只用到前两个板块Detection和Alignment:
- Detection - 用于找到视频中被换脸人的脸的位置
- Alignment - 用于解决B脸和A脸的表情同步,判断正脸侧脸等问题
3 实现流程图

- 五个步骤:视频转图片、人脸检测和校准、Encoder/Decoder训练、人脸转换、图片转视频
- 两个模型:人脸定位模型+人脸转换模型(训练+转换)
我们将整个项目分成五个部分,其中使用了两个模型人脸定位模型和人脸转换模型(Encoder-Decoder):
3.1 First Step – 使用FFmpeg工具视频转图片
FFmpeg介绍
-
支持几乎所有音频、视频格式合并、剪切、格式转换、音频提取、视频转图片、图片转视频
-
播放器、直播等音视频行业核心
3.2 Second Step – 人脸检测和校准
人脸检测和校准是一个相对成熟的领域(识别率98%以上),虽然我们可以自己定制一个人脸检测的算法,但是我们采用通用的人脸识别的函数库Dlib,毕竟没必要重复造轮子。
- Dlib 这是一个很有名的库,有c++、Python的接口。
使用dlib可以大大简化开发,比如人脸检测,特征点检测之类的工作都可以很轻松实现。
同时也有很多基于dlib开发的应用和开源库,比如face_recogintion库等等。
3.2.1 人脸检测 - 两种方案

-
- 基于传统HOG模型
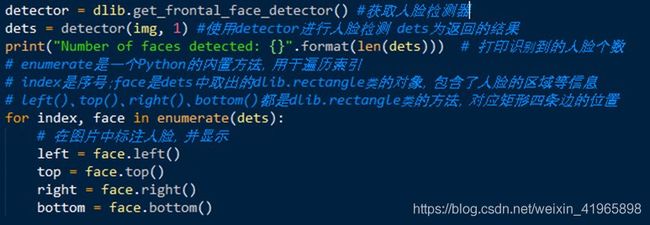
上述为调用dlib库中的HOG模型做人脸检测,dlib官方文档有如下描述,表明该模型经过大量训练在人脸检测领域确实比较成熟:
This face detector is made using the classic Histogram of Oriented Gradients (HOG) feature combined with a linear classifier, an image pyramid, and sliding window detection scheme.
The pose estimator was created by using dlib’s implementation of the paper: One Millisecond Face Alignment with an Ensemble of Regression Trees by Vahid Kazemi and Josephine Sullivan, CVPR 2014 and was trained on the iBUG 300-W face landmark dataset.
顺便值得一提的是,HOG模型多用于行人检测,行人检测很多基于经典论文HOG+SVM模型。
-
- 基于CNN模型-
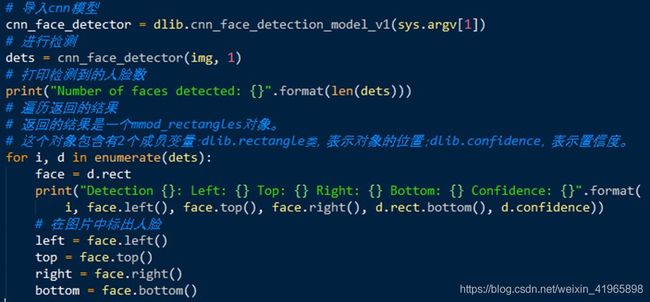
从上述代码可以看出,我们是将first step 得到的连续帧序列图片作为输入。
通过对输入的处理得到每一帧人脸位置的信息输出到json文件中,并且截取人脸位置的照片。
- 人脸特写照片:用于third step 训练人脸转换GAN模型。
- Json文件:用于fourth step 人脸转换,只对标记区域进行转换,我们只换人脸。
3.2.2 人脸校准
- 为什么要做人脸校准?
转换后的脸和原脸保持同一表情,同一朝向,要让每一帧的图像都符合原图,彻底让图像动起来。 - 怎么做人脸校准?
首先要提取人脸特征点。
对转换后的脸按照原脸提取到的特征点排布进行变换,这样就解决了表情同步等问题。
3.2.2.1 特征点提取
- 怎么提取特征点?
特征点提取总的来说分为三种方式:(目前,应用最广泛,效果精度最高的是基于深度学习的方法)
基于 ASM 和 AAM 的传统方法;
基于级联形状回归的方法;
基于深度学习的方法。
原理不做展开,直接调用dlib实现。
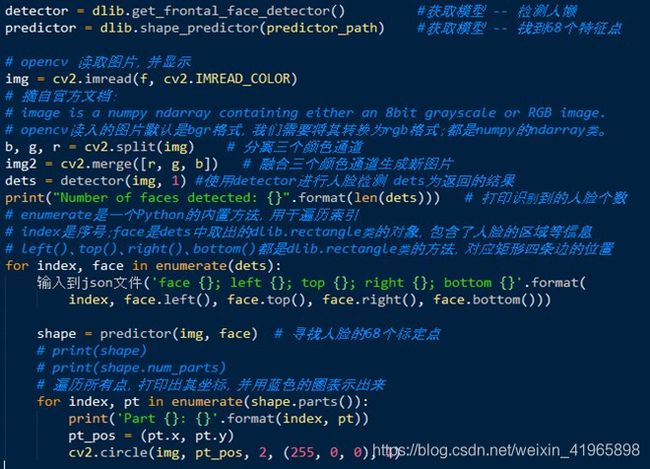
我们可以找到68个人脸特征点。
3.2.2.2 校准
对提取到的特征点,通过以下两种方案对特征点进行处理来做到校准人脸(表情同步)
- 普氏分析
因为图片中的人脸可能会有一定的倾斜,而且不同图片中人脸的神态表情朝向也不一样。
所以,我们需要把人脸进行调整。
PA( 普氏分析)包含了常见的矩阵变换和SVD的分解过程,最终返回变换矩阵,调用变换矩阵,最后将原图和所求得矩阵放进warpAffine即可获的新图片。其中cv.warpAffine的功能就是根据变换矩阵对源矩阵进行变换。
注意:
1 这个矩阵不是将a脸转换为b脸,那是third setp要完成的任务。
2 这个矩阵是让a脸具有和b脸拥有相同的表情,朝向。

实质上最后transformation_from_points就是得到了一个转换矩阵,第一幅图片中的人脸可以通过这个转换矩阵映射到第二幅图片中,与第二幅图片中的人脸对应。
- 点云匹配 PCL
Umeyama是一种PCL算法,简单点来理解就是将源点云(source cloud)变换到目标点云(target cloud)相同的坐标系下,包含了常见的矩阵变换和SVD的分解过程。最终返回变换矩阵。计算过程与普氏分析极其相似。
调用umeyama后获取变换所需的矩阵,最后将原图和所求得矩阵放进warpAffine即可获的新图片。
注意:
代码详见 lib/umeyama.py ,不做解释。
umeyama实现来自开源scikit-image/skimage/transform/_geometric.py
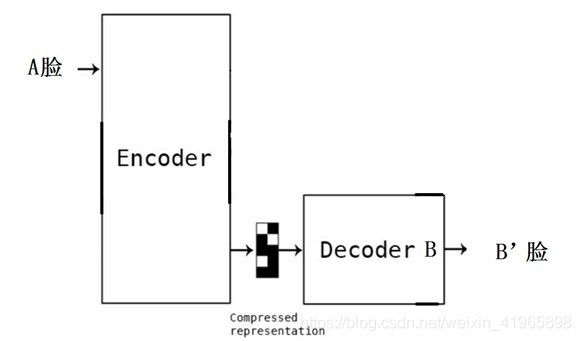
3.3 Third Step – 人脸Encoder/Decoder训练
接下来转换人脸,人脸转换的基本原理是什么?
假设让你盯着一个人的视频连续看上 100 个小时,接着又给你看一眼另外一个人的照片,接着让你凭着记忆画出来刚才的照片,你一定画的会很像第一个人的。使用的模型是 Autoencoder。核心思想:GAN
1 这个模型所做的是基于原始的图片再次生成原始的图片。
2 Autoencoder 的编码器(Encoder)把图片进行压缩,而解码器(Decoder)把图片进行还原,一个示例如下图:

我们的目标不是让他原始图片到原始图片,而是让原始图片转为目标图片?
1 有趣的是,在之前的基础上,即使我们输入的是另外一个人脸,也会被 Autoencoder 编码成为一个类似原来的脸。
2 为了提升我们最终的效果,我们还需要把人脸共性相关的属性和人脸特性相关的属性进行学习。
因此,我们对所有的脸都用一个统一的编码器Encoder,这个编码器的目的是学习人脸共性的地方;
然后,我们对每个脸有一个单独的解码器Decoder,这个解码器是为了学习人脸个性的地方。
这样当你用 A 的脸通过编码器,再使用 B 的解码器的话,你会得到一个与 A 的表情一致,但是 B 的脸。
上述过程用流程图表示如下:(训练过程)

上述过程用公式表示如下:
X‘ = Decoder(Encoder(X)) #目标函数
Loss = L1Loss(X‘-X) #损失函数
A’ = Decoder_A(Encoder(A))
Loss_A = L1Loss(A’-A)
B’ = Decoder_B (Encoder(B))
Loss_B = L1Loss(B’-B)
上述过程用代码表示如下:



Encoder 就是4层卷积+2层全连接层+1层upscale。
Decorder 就是三层upscale+1层卷积。
Upscale 嵌套在Encoder和Decoder中。
Upscale的核心是PixelShuffler() ,该函数是把图像进行了一定的扭曲,而这个扭曲增加了学习的难度,反而让模型能够实现最终的效果。
PixelShuffler对训练起作用的解读:
如果你一直在做简单的题目,那么必然不会有什么解决难题的能力。但是,我只要把题目做一些变体,就足以让你成功。因为在建模中使用的是原图 A 的扭曲来还原 A,应用中是用 B 来还原 A,所以扭曲的方式会极大的影响到最终的结果。因此,如何选择更好的扭曲方式,也是一个重要的问题。
3.4 Fourth Step – 人脸转换
我们的目标是:将带有landmark( A脸)的帧图片转换成新的图片(只换landmark区域,A脸变B脸)
3.4.1 首先,生成每一帧图片中A脸区域对应的B脸区域图片
过程:Decoder_B (Encoder(A)) #输入A ,输出B
3.4.2 将生成的B脸图片替换A脸区域
根据之前3.2.1人脸检测生成的json文件找到A脸的landmark,逐帧替换,生成一系列新图。
3.5 Fifth Step – 图片转视频
将经过Step4转换后的图片通过FFmpeg组合成视频,将原视频的音频也可以加进去。
4 后续改进和总结
| 问题描述 | 目前策略 | 如何改进 |
|---|---|---|
| 视频转换 | FFmpeg | 无 |
| 变脸 | Encoder - Decoder | 无 |
| 肤色光照 | 增加训练集的多样性 | 肤色检测 |
| 人脸检测 | cnn_face_detection_model_v1 | 无 |
| 特征点提取 | dlib64个特征点 | 无 |
| 表情同步 | umeyama + cv2.warpAffine | 无 |
| 边界明显 | A图加上自身和B图的每一个像素的均值的差值 | 泊松融合ongoing |
1 因为在训练中使用的是原图 A 的扭曲来还原 A,应用中是用 B 来还原 A,所以扭曲的方式(PixelShuffler) 会极大的影响到最终的结果。因此,如何选择更好的扭曲方式,也是一个重要的问题。
2 当我们图片融合的时候,会有一个难题,如何又保证效果又防止图片抖动。于是我们还要引入相关的算法处理这些情况。于是我们知道,一个看似直接的人脸转换算法在实际操作中需要考虑各种各样的特殊情况,这才可以以假乱真。
5 用到的工具
- Dlib:基于 C++的机器学习人脸检测算法库
- OpenCV:计算机视觉图像处理算法库
- Keras:在底层机器学习框架之上的高级 API 架构
- TensorFlow:Google 开源的机器学习算法框架
- CUDA:Nvidia 提供的针对 GPU 加速的开发环境
- Anaconda:创建独立的 Python 环境
- FFmpeg:多媒体音视频处理开源库
6 应用前景
- faceswap到底有哪些真正的社会价值呢?
我们可以用任何人来拍摄一个电影,然后变成我们想要的任何人。
我们可以创建更加真实的虚拟人物(AR、VR技术)。
穿衣购物可以更加真人模拟。
7 代码使用举例
- 1 将吴彦祖和王宝强视频转为帧序列图片
ffmpeg -i video/wyz/yanzu.mp4 photo/wyz/video-frame-%d.png
ffmpeg -i video/wbq/wbq.mp4 photo/wbq/video-frame-%d.png
- 2 将人脸特写图片剪出来保存,并输出landmark 到json文件中
python faceswap.py extract -i photo/wyz -o photo/faces/wyz
python faceswap.py extract -i photo/wbq -o photo/faces/wbq
- 3 将两人人脸特写照片进行训练
python faceswap.py train -A photo/faces/wyz -B photo/faces/wbq -m models/wyz_wbq
- 4 将吴彦祖的帧序列原图转为王宝强的帧序列图片
python faceswap.py convert -i photo/wyz -o photo/wyz_wbq -m models/wyz_wbq
- 5 将转换后的图片帧组合成视频,如何加入音频请自行google用法
ffmpeg -i photo/wyz_wbq/video-frame-%0d.png -c:v libx264 -vf “fps=24,format=yuv420p” video/wyz_wbq/out.mp4
8 参考
- https://github.com/deepfakes/faceswap