R语言基础之第六部分 分类(史上最全含ddply、aggregate、split、by)
R语言基础之第六部分 分类(史上最全含ddply、aggregate、split、by)
数据:
某市2014年-2018年空气质量指数日数据,需要按年分类计算每年 warm值为1和 0的均值。
数据长这个样子:
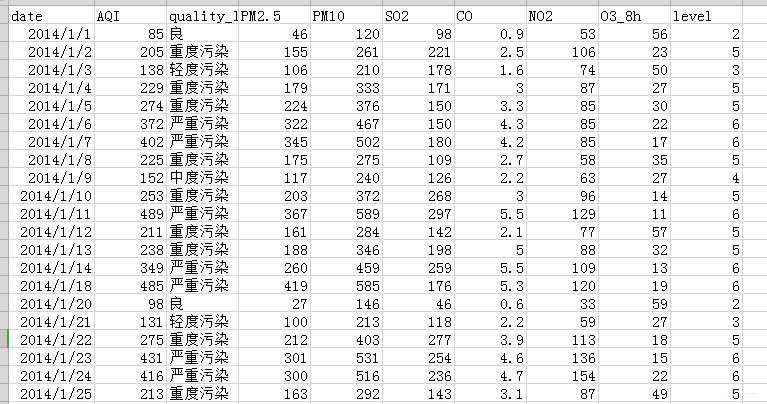
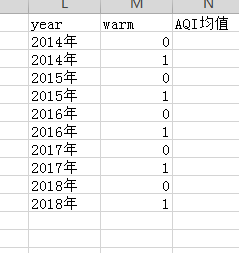
目标:求下列的均值
一、数据处理(提取年月)
首先需要处理一下日期数据,拿到想要的年月。
这里先看一下R语言自带的 和 lubridate包的 提取年月季度的函数 的区别
> sjz = read.csv('C:/Users/Administrator/Desktop/简书/sjz.csv')
> head(sjz) #读取的日期格式不是R可以处理的
date AQI quality_level PM2.5 PM10 SO2 CO NO2 O3_8h level
1 2014/1/1 85 良 46 120 98 0.9 53 56 2
2 2014/1/2 205 重度污染 155 261 221 2.5 106 23 5
3 2014/1/3 138 轻度污染 106 210 178 1.6 74 50 3
4 2014/1/4 229 重度污染 179 333 171 3.0 87 27 5
5 2014/1/5 274 重度污染 224 376 150 3.3 85 30 5
6 2014/1/6 372 严重污染 322 467 150 4.3 85 22 6
> sjz$date = as.Date(sjz$date) #R可以处理的日期格式是:y-m-d或者y/m/d
> head(sjz)
date AQI quality_level PM2.5 PM10 SO2 CO NO2 O3_8h level
1 2014-01-01 85 良 46 120 98 0.9 53 56 2
2 2014-01-02 205 重度污染 155 261 221 2.5 106 23 5
3 2014-01-03 138 轻度污染 106 210 178 1.6 74 50 3
4 2014-01-04 229 重度污染 179 333 171 3.0 87 27 5
5 2014-01-05 274 重度污染 224 376 150 3.3 85 30 5
6 2014-01-06 372 严重污染 322 467 150 4.3 85 22 6
1.1 R自带函数提取年月日季度
> head(years(sjz$date)) #R自带函数提取年
[1] "16071y 0m 0d 0H 0M 0S" "16072y 0m 0d 0H 0M 0S" "16073y 0m 0d 0H 0M 0S"
[4] "16074y 0m 0d 0H 0M 0S" "16075y 0m 0d 0H 0M 0S" "16076y 0m 0d 0H 0M 0S"
> head(months(sjz$date)) #R自带函数提取月
[1] "一月" "一月" "一月" "一月" "一月" "一月"
> head(quarters(sjz$date)) #R自带函数提取季度
[1] "Q1" "Q1" "Q1" "Q1" "Q1" "Q1"
> head(days(sjz$date)) #R自带函数提取天
[1] "16071d 0H 0M 0S" "16072d 0H 0M 0S" "16073d 0H 0M 0S" "16074d 0H 0M 0S" "16075d 0H 0M 0S"
[6] "16076d 0H 0M 0S"
1.2 lubridate包提取年月日
> library(lubridate)
> sjz$year = year(sjz$date)
> sjz$month = month(sjz$date)
> head(sjz) #最后两列提取结果是不是就很人性
date AQI quality_level PM2.5 PM10 SO2 CO NO2 O3_8h level year month
1 2014-01-01 85 良 46 120 98 0.9 53 56 2 2014 1
2 2014-01-02 205 重度污染 155 261 221 2.5 106 23 5 2014 1
3 2014-01-03 138 轻度污染 106 210 178 1.6 74 50 3 2014 1
4 2014-01-04 229 重度污染 179 333 171 3.0 87 27 5 2014 1
5 2014-01-05 274 重度污染 224 376 150 3.3 85 30 5 2014 1
6 2014-01-06 372 严重污染 322 467 150 4.3 85 22 6 2014
1.3 生成分类变量warm
如果月份是11,12,1,2,3,则设置warm为1.其他为0
> #本行这种写法错误 sjz$warm = ifelse(sjz$month == 11|12|1|2|3,1,0),须多次使用ifelse语句,即下面这种
> sjz$warm = ifelse(
+ sjz$month == 11,
+ 1,
+ ifelse(
+ sjz$month == 12,
+ 1,
+ ifelse(sjz$month == 1, 1, ifelse(
+ sjz$month == 2, 1, ifelse(sjz$month == 3, 1, 0)
+ ))))
> head(sjz)
date AQI quality_level PM2.5 PM10 SO2 CO NO2 O3_8h level year month warm
1 2014-01-01 85 良 46 120 98 0.9 53 56 2 2014 1 1
2 2014-01-02 205 重度污染 155 261 221 2.5 106 23 5 2014 1 1
3 2014-01-03 138 轻度污染 106 210 178 1.6 74 50 3 2014 1 1
4 2014-01-04 229 重度污染 179 333 171 3.0 87 27 5 2014 1 1
5 2014-01-05 274 重度污染 224 376 150 3.3 85 30 5 2014 1 1
6 2014-01-06 372 严重污染 322 467 150 4.3 85 22 6 2014 1 1
综上,我们得到了含有AQI、year、month、warm等变量的数据。这样就可以进行下面的分类了。
二、分类
2.1 使用ddply函数
ddply(data,variables,fun = NULL, …,progress = “none”,drop = TRUE, parallel = FALSE)
data : 要处理的数据框
variables :变量,以数据框的拆分,作为引用变量,公式或字符向量
drop :因变量的组合不会出现在输入数据被保存(FALSE)或下降(TRUE,默认情况下)
> library(plyr)
> a = ddply(sjz,c("year","warm"),summarise,mean = mean(AQI),length = length(AQI))
> class(a)
[1] "data.frame"
> a
year warm mean length
1 2014 0 131.85514 214
2 2014 1 198.65972 144
3 2015 0 93.99065 214
4 2015 1 165.17361 144
5 2016 0 102.68692 214
6 2016 1 186.37500 144
7 2017 0 117.07944 214
8 2017 1 152.25694 144
9 2018 0 97.78505 214
10 2018 1 120.75694 144
2.2 使用aggregate函数:
aggregate(x,by, FUN, …, simplify = TRUE, drop = TRUE)
x : 要分类汇总的数据,可以是各种形式,包括公式形式
by : 分类依据,必须是list形式
FUN : 汇总使用的函数
simplify : 默认为TRUE,表示汇总结果以简化形式表现
drop : 默认为TRUE,表示不存在的Level组合自动舍弃
> b = aggregate(x = sjz$AQI,by = list(sjz$year,sjz$warm),FUN = mean)
> class(b)
[1] "data.frame"
> b
Group.1 Group.2 x
1 2014 0 131.85514
2 2015 0 93.99065
3 2016 0 102.68692
4 2017 0 117.07944
5 2018 0 97.78505
6 2014 1 198.65972
7 2015 1 165.17361
8 2016 1 186.37500
9 2017 1 152.25694
10 2018 1 120.75694
2.3 使用split 函数
split(x, f,drop = FALSE, …)
x : 要进行划分的数据
f : 划分的依据,可以是list,表示按list中各变量的Level组合来划分
drop : 默认为FALSE,若为TRUE,当f为list时,各变量的Level组合为空时自动舍弃这一分组
> c = split(sjz$AQI,list(sjz$year,sjz$warm))
> class(c)
[1] "list"
> sapply(c,mean)
2014.0 2015.0 2016.0 2017.0 2018.0 2014.1 2015.1 2016.1 2017.1
131.85514 93.99065 102.68692 117.07944 97.78505 198.65972 165.17361 186.37500 152.25694
2018.1
120.75694
2.4 使用by函数
by(data, INDICES, FUN)
data : 数据框或矩阵
INDICES : 一个因子或因子组成的列表,定义了分组
FUN :任意函数
> d = by(sjz,list(sjz$year,sjz$warm), function(x) mean(x[,2]))
#fun这里用mean = sjz$AQI 显示错误是为啥
> class(d)
[1] "by"
> d
: 2014
: 0
[1] 131.8551
----------------------------------------------------------------------
: 2015
: 0
[1] 93.99065
----------------------------------------------------------------------
: 2016
: 0
[1] 102.6869
----------------------------------------------------------------------
: 2017
: 0
[1] 117.0794
----------------------------------------------------------------------
: 2018
: 0
[1] 97.78505
----------------------------------------------------------------------
: 2014
: 1
[1] 198.6597
----------------------------------------------------------------------
: 2015
: 1
[1] 165.1736
----------------------------------------------------------------------
: 2016
: 1
[1] 186.375
----------------------------------------------------------------------
: 2017
: 1
[1] 152.2569
----------------------------------------------------------------------
: 2018
: 1
[1] 120.7569
R语言基础之第一部分:5种数据对象类型
R语言基础之第二部分:操纵数据/取子集
R语言基础之第三部分:重要函数apply族函数的使用
R语言基础之第四部分 : 排序
R语言基础之第五部分 : 总结数据信息