连接池原来这么简单(一分钟系列)
应网友要求,写一写连接池实现细节。
一、如何通过连接访问下游
工程架构中有很多访问下游的需求,下游包括但不限于服务/数据库/缓存,其通讯步骤是为:
(1)与下游建立一个连接
(2)通过这个连接,收发请求
(3)交互结束,关闭连接,释放资源
这个连接是什么呢,通过连接怎么调用下游接口?服务/数据库/缓存,官方会提供不同语言的Driver、Document、DemoCode来教使用方建立连接与调用接口,以MongoDB的C++官方Driver API为例(伪代码):
DBClientConnection* c = new DBClientConnection();
c->connect(“127.0.0.1:8888”);
c->insert(“db.s”, BSON(”shenjian”));
c->close();
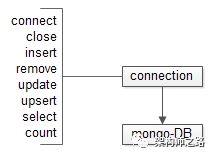
这个DBClientConnection就是一个与MongoDB的连接,官方Driver通过它提供了若干API,让用户可以对MongoDB进行连接,增删查改,关闭的操作,从而实现不同的业务逻辑。
二、为什么需要连接池
当并发量很低的时候,上述伪代码没有任何问题,但当服务单机QPS达到几百、几千的时候,建立连接connect和销毁连接close就会成为瓶颈,此时该如何优化?
结论也很简单,服务启动的时候,先建立好若干连接Array[DBClientConnection],当有请求过来的时候,从Array中取出一个,执行下游操作,执行完再放回,从而避免反复的建立和销毁连接,以提升性能。
而这个对Array[DBClientConnection]进行维护的数据结构,就是连接池。有了连接池之后,数据库操作的伪代码变为:
DBClientConnection* c = ConnectionPool::GetConnection();
c->insert(“db.s”, BSON(”shenjian”));
ConnectionPool::FreeConnection(c);
三、连接池核心接口与实现
通过上面的讨论,可以看到连接池ConnectionPool主要有三个核心接口:
(1)Init:初始化好Array[DBClientConnection],这个接口只在服务启动时调用一次
(2)GetConnection:请求每次需要访问数据库时,不是connect一个连接,而是通过连接池的这个接口来拿
(3)FreeConnection:请求每次访问完数据库时,不是close一个连接,而是把这个连接放回连接池
连接池核心数据结构:
(1)连接数组Array DBClientConnection [N]
(2)互斥锁数组Array lock[N]
连接池核心接口实现:
Init(){
for i = 1 to N {
Array DBClientConnection [i] = new();
Array DBClientConnection [i]->connect();
Array lock[i] = 0;
}
}
说明:把所有连接和互斥锁初始化
GetConnection()
for i = 1 to N {
if(Array lock[i] == 0){
Array lock[i] = 1;
return Array DBClientConnection[i];
}
}
}
说明:找一个可用的连接,锁住,并返回连接
FreeConnection(c)
for i = 1 to N {
if(Array DBClientConnection [i] == c){
Array lock[i] = 0;
}
}
}
说明:找到连接,把锁释放
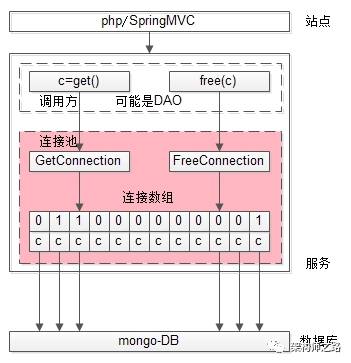
可以发现,简单的连接池管理并不是很复杂,基本原理即如上所述。
四、未尽事宜
上述伪代码忽略了一些细节,在实现连接池中是需要考虑的:
(1)如果连接全部被占用,是返回失败,还是让上游等待
(2)需要实施连接可用性检测
(3)为了让调用方更友好,可能还需要包装一层DAO层,让“连接”这个东西对调用方都是黑盒的
(4)通过freeArray,connectionMap可以让取连接和放回连接都达到O(1)时间复杂度
(5)可以通过hash实现id串行化
(6)负载均衡、故障转移、服务自动扩容都可以在这一层实现
希望这一分钟大家有收获。
==【完】==
相关阅读:
“id串行化”到底是怎么实现的?
消息“时序”与“一致性”为何这么难?