hadoop系列之yarn
YARN
-
- YARN 概述
 |
|
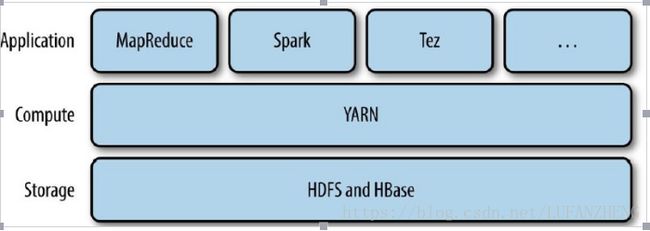
YARN,即 Yet Another Resource Negotiator 的缩写, 它是 Hadoop 资源管理系统,是在 Hadoop2 以后引入的。它在整个 Hadoop 中的位置如下:
-
- YARN 与 MapReduce1
MapReduce1 指 Hadoop1.x 中的 MapReduce 分布式执行框架,用以区别使用了 YARN 的 MapReduce2。
-
-
- MapReduce1 的机制
-
MapReduce1 由两类守护进程来控制作业的执行:一个 jobtracker 以及一个或多个 tasktracker。jobtracker 通过调度 tasktracker 上运行的任务来协调所有运行在系统上的作业。同时,tasktracker 在运行任务的同时会将运行进度上报给 jobtracker。
从上面的描述中可以看到,jobtracker 同时负责任务调度和进度监控。而在 YARN 架构中,这些职责是由不同的实体承担的。
-
-
- YARN 与 MapReduce1 对比
- 可扩展性
- YARN 与 MapReduce1 对比
-
由于 MapReduce1 总的 jobtracker 必须同时管理作业调度和任务跟踪,当集群的规模超过一定程度(比如节点数超过 4000,任务数超过 40000),MapReduce1 就会遇到扩展瓶颈。而在 YARN 中,作业调度由
ResourceManager 负责,任务的跟踪由 NodeManager 中的 Application Master 负责。YARN 利用资源管理器与
Application Master 分离的架构解决 了这个局限,可以扩展到近 10000 个节点和 100000 个任务。
-
-
-
- 可用性
-
-
由于 MapReduce1 中的 jobtracker 内存中包含大量快速变化的负责状态(比如任务的执行状态),这使得改进
jobtracker 让其具有高可用非常困难。
但 YARN 中将作业调度和跟踪职责划分之后,就变成了分别对资源管理器和 YARN 应用的高可用,而对
ResourceManager 高可用和 YARN 应用的高可用要容易得多。后面分别会有详细介绍。
-
-
-
- 利用率
-
-
MapReduce1 中为每个 tasktracker 分别的 slot 是固定长度的,而且区分了 map slot 和 reduce slot,这会导致两者任务不匹配的时候,其中的一类 slot 空闲,利用率不足。
而 YARN 中,一个节点管理器管理一个资源池,而不是固定数目的 slot。不会出现 MapReduce1 中的情况。
-
-
-
- 多租户
-
-
YARN 不仅仅适用于 MapReduce,它对外开放了 Hadoop,可以在 YARN 上运行包括 MapReduce1、
MapReduce2 以及其他应用,如 Spark 等。
-
- YARN 解析
- 架构剖析
- YARN 解析
YARN 按功能可分为资源管理器和任务的调度与监控,并将它们分别纳入两个独立的守护进程。基本思想为一个全局的 ResourceManager 和每个应用节点运行一个 NodeManager。
ResourceManager 全权负责整个集群的资源管理,而每个节点上的 NodeManager 则负责容器、监控该节点资源的使用并将它们报告给 ResourceManager 节点。
 |
|
ResourceManager 包含两个组件:即 Scheduler 和 ApplicationsManager。
Scheduler 负责资源的调度,它是可插拔的,比如支持 CapacityScheduler,FairScheduler 等。
ApplicationsManager 负责接受作业请求,协商第一个 Container 来启动应用特定 ApplicationMaster,并负责在
ApplicationMaster 失败的时候重启。
每个应用会有一个 ApplicationMaster,它负责向 ResourceManager 的 Scheduler 申请资源,并跟踪作业的状态和监控整个过程。
-
-
- 工作机制
-

YARN 的工作机制
YARN 作业的工作流程:
第一步:MapReduce 客户端程序中的 main 中执行 runjob,开始作业;
第二步:客户端程序向 RM 发送作业请求同时 RM 将作业 id 以及存放 jar 包的 hdfs 目录返回给客户端;
第三步:客户端会把切片信息、job 的配置信息以及 jar 包上传到上一步收到的 hdfs 目录下(三个文件分别为
job.split、job.xml、jar 包);
第四步:客户端应用提交给 RM;
第五步:RM 将其放入调度器,寻找一个空闲的 NM 创建第一个 Container 容器,并启动 MRAppMaster 进程;
第六步:NM 通过心跳机制接受调度器分配的任务,初始化一个 job;
第七步:MRAppMaster 从 HDSF 中获取需要的数据,如分片信息。这些数据在第三步中存入;
第八步:MRAppMaster 向 RM 申请运行 job 所需的资源,RM 选择一个拥有相应资源的 NM 返回; 第九步:MRAppMaster 告知选中的 NM,启动一个 YarnChild Container 容器;
第十步:YarnChild 从 HDFS 中获取运行 map 和 reduce 任务所需的资源; 第十一步:YarnChild 执行 MapTask 或者 Reduce Task
-
-
- 内置调度器
- FIFO 调度器
- 内置调度器
-
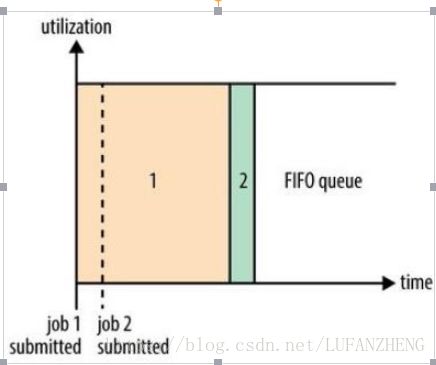
FIFO 为 First Input First Output 的缩写,先进先出。FIFO 调度器将应用放在一个队列中,按照先后顺序运行应用。这种策略较为简单,但不适合共享集群,因为大的应用会占用集群的所有资源,每个应用必须等待直到轮到自己。
-
-
-
- 容量调度器容量调度器 Capacity
-
-

-
-
-
- 公平调度器
-
-
公平调度器的目的就是为所有运行的应用公平分配资源。

-
- YARN HA
参考:http://hadoop.apache.org/docs/r2.7.3/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
-
-
- YARN HA 架构
-
YARN HA 主要是为了解决 YARN 中的 ResourceManager 的单点故障。ResourceManager 的 HA 是通过主备
(Active/Standby)方案来实现。
在任何时候,都只有一个 ResourceManager 是 Active 的,另外一个处于 Standby 状态,一旦 Active 节点出现故障,随时准备接管 Active 节点。主备的切换通常由管理员发起的命令或者集成的 failover-controller 来触发。
YARN HA 架构图
-
-
- 主备切换
-
手动切换/自动切换相关配置涉及 yarn-site.xml 中的 yarn.resourcemanager.ha.automatic-failover.enabled 配置项。默认情况下,当 yarn.resourcemanager.ha.enabled 为 true 的时候它就为 true。