C++20中的新特性
C++20中的新特性
- 概念(concepts)
-
- 模板参数的限制
- 概念的用法
- 范围(ranges)
-
- 概念
- 优点
- 使用
- 模块(modules)
-
- 模块初识
- 模块声明
- 导出规则
- 导入规则
- 可达与可见
- 模块的优点
- 协程(coroutines)
-
- 子例程(Subroutine)
- 什么是协程
- 协程的优势
- C++20中的协程
-
- 涉及到的概念
- 协程函数的近似实现
- 协程的用处
- 其他特性
-
- lamda表达式
- 原子(Atomic)智能指针
- std::atomic_ref
- 同步(Synchronization)库
- ...

概念(concepts)
模板参数的限制
在引入concepts之前,对于模板参数限制需要使用一些并不直观的写法,如,限制模板参数类型为int
//std::enable_if实现
template <typename T>
void print_int(std::enable_if_t<std::is_same_v<int, std::decay_t<T>>, T> v)
{
std::cout << v << std::endl;
}
int main()
{
print_int(1); //error C2783: “void"
//...: 未能为“T”推导模板参数
print_int<int>(1);
print_int<double>(1.0); //error C2672: “print_int”:
//未找到匹配的重载函数
}
如果采用concept,可以有更简洁的写法
//concept实现
template <class T>
concept IntLimit = std::is_same_v<int, std::decay_t<T>>;
//制约T塌陷后的类型必须与int相同
template <IntLimit T>
void print_int(T v)
{
std::cout << v << std::endl;
}
int main()
{
print_int(1);
print_int(1.0); //error C2672: “print_int”: 未找到匹配的重载函数
}
concpet可用于对模板类和函数的模板形参的约束,在编译期断言。
概念的用法
C++20引入了concept和requires关键字,相关功能的使用方法至少有四种,用法如下
template<typename T>
concept Integral = std::is_integral<T>::value;
//使用方法一:利用auto关键字
Integral auto Add(Integral auto a, Integral auto b)
{
return a + b;
}
//使用方法二:在template声明以后紧接着用requires关键字
template<typename T>
requires Integral<T>
T Add(T a, T b)
{
return a + b;
}
//使用方法三:在函数声明以后紧接着用requires关键字
template<typename T>
T Add(T a, T b) requires Integral<T>
{
return a + b;
}
//使用方法四:省略requires关键字,将concept的名字放入到模板参数前面
template<Integral T>
T Add(T a, T b)
{
return a + b;
}
限制类型需有前置++和后置++操作
template<typename T> concept Incrementable = requires(T x) {
x++; ++x;};
//使用方法一
void Foo(Incrementable auto t);
//使用方法二
template<typename T> requires Incrementable<T>
void Foo(T t);
//使用方法三
template<typename T>
void Foo(T t) requires Incrementable<T>;
//使用方法四
template<Incrementable T>
void Foo(T t);
限制方法具备size() 方法, 且返回size_t
//定义
template <typename T> concept HasSize = requires (T x){
{
x.size()} -> std::convertible_to<std::size_t>;
};
//使用
template<typename T>
requires Incrementable<T> && Decrementable<T>
void Foo(T t);
template<Incr_Decrementable T>
void Foo(T t);
...
concept和if constexpr结合使用
class A
{
public:
constexpr std::string_view name() const {
return "A"; }
};
class B
{
public:
constexpr std::string_view class_name() const {
return "B"; }
};
template <typename T>
concept CA = requires(T a)
{
a.name();
};
template <typename T>
concept CB = requires(T b)
{
b.class_name();
};
template <typename T>
void print_class(const T& t)
{
if constexpr (CA<T>)
{
std::cout << t.name() << std::endl;
}
else if constexpr (CB<T>)
std::cout << t.class_name() << std::endl;
}
int main()
{
A a;
B b;
print_class(a);
print_class(b);
return 0;
}
范围(ranges)
概念
ranges是C++20中增加的一大库。
通过增加了一种叫做view(视图)的概念,实现了Lazy Evaluation(惰性求值),并且可以将各种view的关系转化用符号“|”串联起来,提高了代码的表现力和可读性。ranges被称为STL2.0,提供了一些使用STL的更简洁的方法。
范围(range)
“项目集合”或“可迭代事物”的抽象。
最基本的定义只需要存在begin()和end()在范围内。
STL的大部分容器都是range。
Range代表一串元素, 或者一串元素中的一段,类似 begin/end 对。
视图(view)
其意义可以参考string_view,它的拷贝代价是很低的。
需要拷贝的时候直接传值即可,不必传引用。
view本身也符合range的特征,可以用迭代器遍历。
view对于数据的遍历都是lazy evaluation(惰性求值)。
C++ 17:string_view
范围适配器(range adaptor)
可以将一个range转换为一个view,也可以将一个view转换为另一个view。
范围适配器接受 viewable_range 为其第一参数并返回一个 view 。
范围通常是输入范围(可读)或输出范围(可写)或两者兼而有之。
参考迭代器的类型,输入范围可做以下精细划分
std::ranges::input_range //可以从头到尾重复至少一次
std::ranges::forward_range //可以从头到尾重复多次
std::ranges::bidirectional_range //迭代器还可以向后移动
std::ranges::random_access_range //可以恒定时间跳转到元素
std::ranges::contiguous_range //元素总是连续存储在内存中
优点
与迭代器相比,使用ranges有更简化的语法,更方便使用。
//迭代器与ranges使用对比:
std::sort(v.begin(), v.end());//迭代器
std::ranges::sort(v) //range
std::sort(v.begin() + 5, v.end());//迭代器
std::ranges::sort(std::views::drop(v, 5)); //ranges
std::sort(v.rbegin() + 5, v.rend());//迭代器
std::ranges::sort(std::views::reverse(v)) //ranges
可以看出,与迭代器相比,使用ranges至少有以下好处:
1)简化语法和方便使用
2)防止 begin/end 不配对
如果配合视图view和动作actions等,还能更加强大:
3)使变换/过滤等串联操作成为可能
范围库(C++20)
github:range-v3
使用
定义于头文件
namespace std {
namespace views = ranges::views;
}
示例1:串联视图
vector<int> data {
1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
auto result = data |
views::remove_if([](int i) {
return i % 2 == 1;}) |
views::transform([](int i) {
return to_string(i);});
// result = {"2", "4", "6", "8", "10" };
// 以上操作被延迟, 遍历result的时候才触发
示例2:串联actions
vector<int> data{
4, 3, 4, 1, 8, 0, 8};
vector<int> result = data | actions::sort | actions::unique;
//排序然后去重
//操作会原地对data进行更改, 然后返回
示例3:过滤和变换
int total = accumulate (
view::ints(1) |
view::transform([](int i) {
return i * i;}) |
view::take(10),
0);
//view::ints(1) 产生一个无限的整型数列
//求平方
//取前10个元素, 然后累加(accumulate)
//所有的计算延迟到accumulate累加遍历的时候发生
模块(modules)
模块初识
每个 Module 都是一个TU(Translation Unit,翻译单元),以模块为单位编译,在构建时得到更好的 Cache 编译的效果,缩短编译时间。
- Module Interface Unit,模块接口单元,导出模块中的成员。
- Module Implementation Unit ,模块实现单元,实现模块中的成员。
- Module Partition,把 Module拆分在多个.cpp文件中定义。
// animal.cpp
export module home;
export import :cat;
export import :dog;
// cat.cpp
export module home:cat;
export auto cat()
{
return "cat";
}
// dog.cpp
export module home:dog;
export auto dog()
{
return "dog";
}
// main.cpp
import animal;
int main()
{
auto cat= cat();
auto dog= dog();
}
带有export module,animal.cpp/cat.cpp/dog.cpp都为模板接口单元。
// animal.cpp
export module animal;
import :dog;
import :cat;
export auto cat();
export auto dog();
// cat.cpp
module animal:cat;
auto cat()
{
return "cat";
}
// dog.cpp
module animal:dog;
auto dog()
{
return "dog";
}
// main.cpp
import animal;
int main()
{
auto cat= cat();
auto dog= dog();
}
带有export module,animal.cpp为模板接口单元。
带有module,cat.cpp/dog.cpp为模板实现单元。
模板实现单元中不允许export,需要在接口单元中导出。
模块声明
export module M; // 模块接口,导出模块
module M; // 模块定义,实现模块
export module M:B; // 内部模块接口,在内部导出子模块
module M:B; // 子模块定义,实现子模块
模块声明方式
- 上述四种方式声明当前文件参与模块的组成。
- 带export的为模块接口单元,意味着导出模块中带export前缀的符号。
- export M意味着导出模块,可被其他模块导入使用
- export M:B意味着在模块内导出B,只能在模块内部被导入使用
- 不带export的只定义模块。
module partition
- 形如export module M:B,在模块内导出B,只能在模块内部被导入使用。
- 在模块M内部可以通过import :B来导入B。
- 导入之后可以使用M:B中加了export前缀的符号。
primary module interface unit
- 形如export module M,一个模块必须有且只有一个primary module interface unit。
- 作为模块对其他模块提供服务的接口。
- 必须直接或间接包含模块M的所有导出声明(带export前缀的符号)。
- 可直接包含,形如export int f()
- 可间接包含:形如export import :B,另一文件中:export module M:B; export int f()
模块名的规则
- 可以带点号:module M.foo
- 不能带关键字或module或import
- 不要用std或std接数字开头的名字,这些是给标准用的
- 不要用保留字(带双下划线 或 以下划线+大写字母开头的),这些是给编译器用的
模块声明的位置
- 必须写在文件开头。不过出于兼容性考虑,
- 如果一个模块要包含其他文件,可以在文件开头用module;这种语法:
module;
#include 模块声明之前包含的文件不属于这个模块,属于global module fragment。
global module fragment
不属于任何模块的东西组成了global module。 包括:
1)模块内的extern "C"/extern "C++"声明
2)replaceable allocation/deallocation function
3)namespace声明等
private module fragment
以module : private ;开头的代表private module fragment,
必须放在其他声明之后。
private module fragment之中的声明在模块外不可达。
export module foo;
export struct X;
export X& f();
module :private;
struct X {
};
X& f() {
static X a; return a; }
模块foo外的单元会把X的定义当成不存在,
所以X会被视作incomplete type(不能定义X类型的对象)。
而模块内则可以定义X类型的对象。
如果用了private module fragment,整个模块必须定义在一个单元里。
导出规则
1)使用export关键字导出
// Export everything within the block.
export
{
int some_number = 123;
class foo
{
public:
void invoke() {
}
private:
int count_ = 0;
};
}
// Export namespace.
export namespace demo::test
{
struct tips
{
int abc;
}
void free_func() {
}
}
// Export a free function.
export void here_is_a_function() {
}
// Export a global variable.
export int global_var = 123;
// Export a class.
export class test
{
};
2)不允许嵌套
export {
export int a(); } // 这样是不允许的
3)可以出现在普通的namespace之内
namespace ns {
export int a(); }
export namespace ns {
int a(); } // 效果和上一句一样
4)export类型别名(typedef或者using)是可以的,即使类型本身没有导出
export module M;
struct S; // 没有导出 S
export using T = S; // OK
struct S {
int n; };
export typedef S S; // OK,导出了类型别名S
5)export必须在第一次声明的时候就指定
export module M;
struct S; // 没有导出 S
struct S {
int n; };
export struct S; // 错误,struct S在第一次声明的时候没有用export
6)static变量或函数不能导出
// Cannot export static variables.
export static int static_variable = 123;
// Cannot export static functions.
export static void foo()
{
}
// OK, export a namespace.
export namespace test
{
// Error, cannot define static members in an exported namespace.
static int mine = 123;
// Error, as mentioned above.
static void geek() {
}
}
7)匿名空间不能导出
// Anonymous namespace cannot be exported.
export namespace
{
}
8)无名字不能导出
export using namespace N; //因为没有声明任何名字,所以不允许
export static_assert(true); //也是不可以的
//这导致export namespace foo { static_assert(true); }也不被允许
export using ns::foo; //ns::foo必须有external linkage
//不能是模块内未导出的名字
导入规则
import关键字用法如下:
import M; // 导入模块 M
import :B; // 导入当前模块的 module partition :B
import <vector>; // 导入头文件
导入位置
模块单元中import声明必须位于其他声明之前。
其他翻译单元对import的位置没有要求,为了直观最好放在开头。
import前可以加export
export import foo表示当前模块导出了翻译单元foo。
如果模块T之外的某个翻译单元导入了模块T,
那么它也同时导入了模块T中用export import导出的所有单元。
如果模块T之中的某个模块单元导入了同模块的另一个单元,
那么它也同时导入了那个单元import的所有单元。
此规则具有传递性。
导入头文件
使用import导入的头文件叫做header unit。
header unit默认导出里面的所有声明。
可达与可见
可达
-
模块的可达性:
1)在某一个位置P之前直接或间接导入的所有模块单元都是可达(reachable)的 -
模块中的声明的可达性:
1)在global module fragment里,没有被模块用到的声明会被当成不可达
2)在private module fragment里的声明,在模块外会被当成不可达最终,在某一个位置P,同一个翻译单元中所有位于P之前的声明是可达的;
并且所有可达的模块单元中可达的声明,也是可达(reachable)的。
可达(reachable)与可见(visible)
两者不同,如果一个声明没有被导出(export),那么它在模块外不可见,但它也许是可达的。比如:
export module foo;
struct X {
}; //没有export struct X;所以外部不能使用X这个类名,不可见
export X& f(); //但是auto x = f();是可以的,可达
模块的优点
没有头文件
声明实现仍然可分离, 但非必要
可以显式指定那些导出(类, 函数等)
不需要头文件重复引入宏 (include guards)
模块之间名称可以相同不会冲突
模块只处理一次, 编译更快 (头文件每次引入都需要处理)
预处理宏只在模块内有效
模块引入顺序无关紧要
协程(coroutines)
子例程(Subroutine)
子例程是为了完成某个特定的任务的程序指令序列。
在C++中,我们可以将子例程简单的理解为函数。
什么是协程
协程是一种可以被允许挂起和重新开始的子例程,支持非抢占性的多任务处理。
在C++20之前协程的实现需要采用栈+状态机来实现。
协程的优势
减少系统的参与,程序员可以自己实现类似时钟阻塞、 线程切换等功能。
有更大的灵活性,是对多线程的一个补充。
以生产者消费者模型解释协程的优势:
// 采用多线程的方式实现生产者消费者模型
std::deque<int> dq;
std::mutex mu;
std::condition_variable cond;
void produce(){
while(1){
std::unique_lock<std::mutex> locker(mu);
dq.push_front(1);
locker.unlock();
cond.notify_one();
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
void consume(){
while(1){
std::unique_lock<std::mutex> locker(mu);
cond.wait(locker, []{
return !dq.empty();});
std::cout<<"consume: "<<dq.front()<<std::endl;
dq.pop_front();
locker.unlock();
}
}
int main(){
std::thread t1(produce);
std::thread t2(consume);
t1.join();
t2.join();
return 0;
}
上面采用多线程加条件变量的方式实现生产者消费者模型。
当程序启动后,线程t2执行到cond.wait(locker, []{return !dq.empty();});的时候,就会阻塞下来。直到线程t1执行了cond.notify_one();,t2会被唤醒。这些都是由系统负责控制的。
下面采用协程方式实现:
var q := new queue
coroutine produce
loop
while q is not full
create some new items
add the items to q
yield to consume
coroutine consume
loop
while q is not empty
remove some items from q
use the items
yield to produce
假设produce先开始执行,当while 循环将q填满后,跳出while循环,
执行yield to consume,这句代码会挂起当前的协程,将当前的状态保留下来,
去执行consume。
consume会从q取一些东西,直到q为空,此时consume跳出while循环,
执行yield to produce,这句代码同样当前的协程挂起,保留其状态,
然后取执行produce。
在procude中,先恢复到之前保存的状态,从上次挂起的位置继续向下执行,
继续执行while q is not full。
以此重复整个过程。
可以看出,线程的挂起和重新开始是由系统来负责的,
而协程的的挂起和重新开始是由程序员控制的。
协程实现灵活性更大,且减少线程切换和锁开销。
C++20中的协程
具备如下关键字之一:
1)co_wait: 挂起协程, 等待其它计算完成
2)co_return: 从协程返回 (协程 return 禁止使用)
3)co_yield: 同python yield,弹出一个值,挂起协程,
下一次调用继续协程的运行
4)for co_await 循环体
//for co_await 循环体
for co_await (for-range-declaration: expression) statement
涉及到的概念
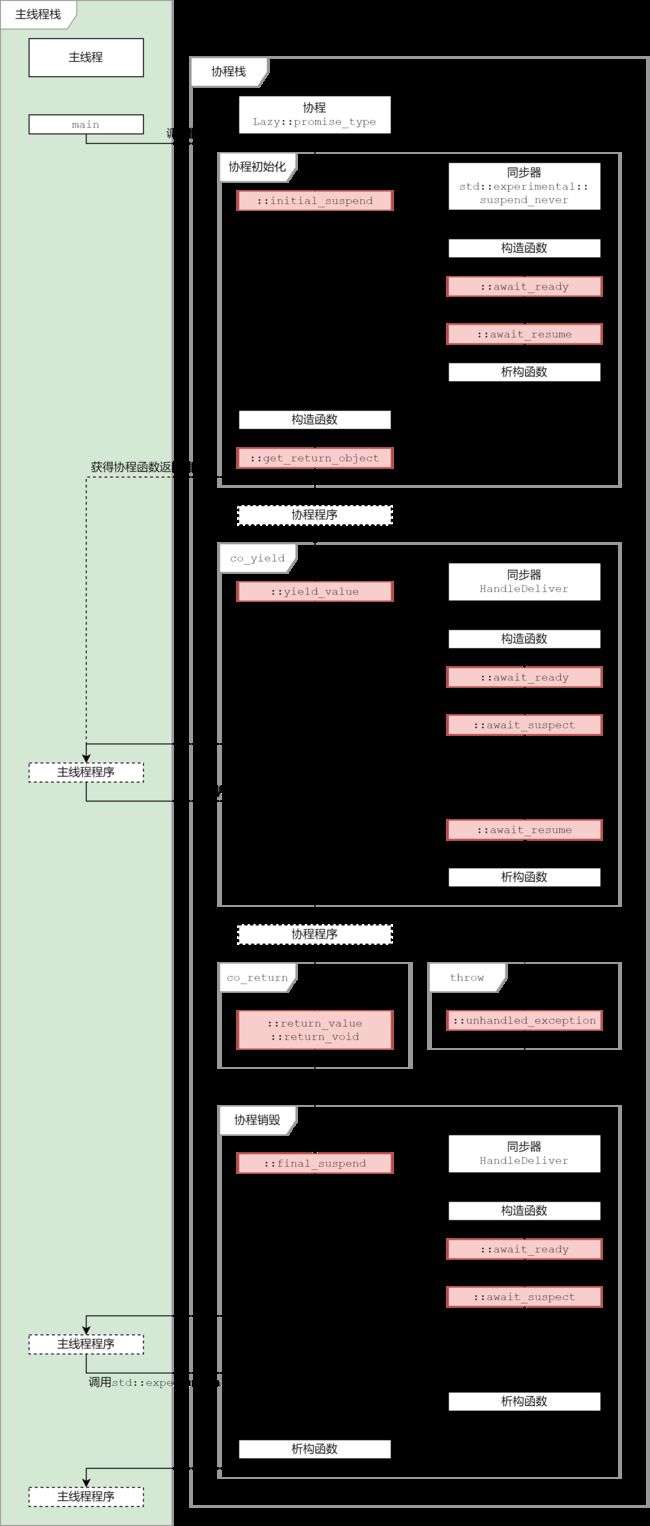
协程函数:
含co_yield或co_return或co_await表达式的函数。
函数调用后返回一个协程对象。
守护器:
promise_type的实例,一个协程有且只有一个守护器。
同步器:
awaiter,协程每次用co_await挂起时都要一个同步器。
协程对象:
守护器调用get_return_object后的返回值,
也是协程函数被调用后的直接返回值。
该返回值不同于协程运行结束后co_return的返回值.
协程中间对象:
即守护器,同步器,及协程对象。
挂起值,发送值:
即co_yield表达式所作用的对象。
恢复值,接收值:
即co_yield表达式的结果,协程外部称恢复值,协程内部称接收值。
返回值,协程返回值:
即co_return表达式所作用的对象。
直接返回值:
协程函数直接返回值,即协程对象。
主线程,协程外部,外部:
即建立并持有协程对象的外部的协程或主函数. (协程是可嵌套恢复的)。
协程挂起,挂起:
即协程暂停自身的运行,并将运行权移交到协程外部。
协程恢复,协程恢复:
即协程被外部通过调用其句柄的resume函数被唤醒,并重获运行权。
协程函数的近似实现
1)协程函数:
Lazy f(int a) {
for(int i = 0; i < a; ++i) {
co_yield i;
}
co_return 10;
}
//近似实现
Lazy f(int a) {
// 协程分配内存
std::coroutine_traits<Lazy, int>::promise_type promise;
// 按照C++标准 promise 应先构造再调用 initial_suspend
// 但 MSVC 的实际实现是颠倒的
auto initial_awaiter = promise.initial_suspend();
// initial_awaiter 在主线程栈上普通构造, 然后在协程栈上移动构造,
// 然后在主线程栈上析构, 最后实为协程栈上的对象
promise::promise_type();
auto __return__ = promise.get_return_object(); // __return__ 在
//主线程栈上普通构造
// 该 __return__ 对象将在本协程函数挂起后给主线程函数
//作为协程函数的返回值
co_await initial_awaiter; // 该 initial_awaiter 对象生命周期一直
//持续到协程结束
try {
for(int i = 0; i < a; ++i) {
co_await promise.yield_value(i);
// co_yield exp 转化为等价表达式 co_await promise.yield_value(exp)
}
promise.return_value(10);
goto final_suspend;
// co_return exp; 转化为等价表达式
// promise.return_value(exp); goto final_suspend;
// co_return; 转化为等价表达式
//promise.return_void(); goto final_suspend;
} catch(...) {
promise.unhandled_exception();
goto final_suspend;
}
final_suspend:
co_await promise.final_suspend();
// initial_awaiter 析构
// 实参 析构
// promise 析构
// 协程回收内存
}
2)co_await运算符:
//co_await是一个新的单目运算符. 运算符可重载.
//当其作用在对象上时, 例如下
co_await awaiter
//近似实现如下
((awaiter.await_ready() ? : awaiter.await_suspend(this_coroutine_handle)), \
awaiter.await_resume())
//整个表达式的类型由await_resume的返回类型决定.
//当awaiter.await_ready返回false之后, 协程将自身挂起,
//并将自身的句柄作为参数调用awaiter.await_suspend, 以方便未来恢复协程.
//不管有没有调用awaiter.await_suspend挂起, 调用完awaiter.await_ready(),
//返回true或者协程恢复后, 协程首先调用awaiter.await_resume,
//取其返回值作为co_await表达式的结果.
协程的用处
可用于简化如下问题的实现:
generator生成器
异步I/O
延迟计算
事件驱动的程序
//生成器例子,惰性求值
experimental::generator<int> GetSequenceGenerator(
int startValue,
size_t numberOfValues) {
for (int i = 0 startValue; i < startValue + numberOfValues; ++i){
time_t t = system_clock::to_time_t(system_clock::now());
cout << std:: ctime(&t); co_yield i;
}
}
int main() {
auto gen = GetSequenceGenerator(10, 5);
for (const auto& value : gen) {
cout << value << "(Press enter for next value)" << endl;
cin.ignore();
}
}
//co_yield xxx 会被转化为 co_await promise.yield_value(xxx)
//协程入口函数的返回值generator需满足Promise的规范
template <typename T>
struct generator {
struct promise_type {
suspend_never initial_suspend() {
return {
}; }
suspend_always final_suspend() {
return {
}; }
auto yield_value(T v) {
val.emplace(std::move(v));
return suspend_always();
}
auto get_return_object() {
return generator(this); }
void return_void() {
}
void unhandled_exception() {
throw; }
auto coro() {
return coroutine_handle<promise_type>::from_promise(*this); }
std::optional<T> val;
};
generator(generator&& source) : p(std::exchange(source.p, nullptr)) {
}
explicit generator(promise_type* p) :p(p) {
}
~generator() {
if (p) p->coro().destroy();
}
// 为了实现range based for和iterator,加上这些代码
struct EndSentinel{
};
auto end() {
return EndSentinel(); }
auto begin() {
struct Iter {
bool operator!=(EndSentinel) const {
return !p->coro().done(); }
void operator++() {
p->coro().resume(); }
T& operator*() const {
return *p->val; }
promise_type* p;
};,
return Iter{
p};
}
promise_type* p;
};
//异步编程
//使用多线程异步调用
using call_back = std::function<void(int)>;
void Add100ByCallback(int init, call_back f) //init是传入的初始值,
//add之后的结果由回调函数f通知
{
std::thread t([init, f]() {
std::this_thread::sleep_for(std::chrono::seconds(5)); // sleep一下,假装很耗时
f(init + 100); // 耗时的计算完成了,调用回调函数
});
t.detach();
}
Add100ByCallback(5, [](int value){
std::cout<< \
"get result: "<<value<<"\n"; });
//异步编程
//使用协程程异步调用
//协程的入口必须是在某个函数中,
//函数的返回值需要满足Promise的规范
struct Task
{
struct promise_type {
auto get_return_object() {
return Task{
}; }
auto initial_suspend() {
return std::experimental::suspend_never{
}; }
auto final_suspend() {
return std::experimental::suspend_never{
}; }
void unhandled_exception() {
std::terminate(); }
void return_void() {
}
};
};
//可co_wait(Awaitable)的对象需要实现三个函数
/* await_ready:返回Awaitable实例是否已经ready。
协程开始会调用此函数,如果返回true,表示想得到的结果已经得到了,
协程不需要执行了。所以大部分情况这个函数的实现是要return false。*/
/* await_suspend:挂起awaitable。该函数会传入一个coroutine_handle类型
的参数。这是一个由编译器生成的变量。在此函数中调用handle.resume(),
就可以恢复协程。*/
/* await_resume:当协程重新运行时,会调用该函数。
这个函数的返回值就是co_await运算符的返回值。*/
struct Add100AWaitable
{
Add100AWaitable(int init):init_(init) {
}
bool await_ready() const {
return false; }
int await_resume() {
return result_; }
void await_suspend(std::experimental::coroutine_handle<> handle)
{
// 定义一个回调函数,在此函数中恢复协程
auto f = [handle, this](int value) mutable {
result_ = value;
handle.resume(); // 这句是关键
};
Add100ByCallback(init_, f);
}
int init_; // 将参数存在这里
int result_; // 将返回值存在这里
};
Task Add100ByCoroutine(int init, call_back f)
{
int ret = co_await Add100AWaitable(init);
ret = co_await Add100AWaitable(ret);
ret = co_await Add100AWaitable(ret);
f(ret);
}
//启动一个协程
Add100ByCoroutine(10, [](int value){
std::cout<<"get result \
from coroutine: "<<value<<"\n"; });
C++ Coroutines
其他特性
lamda表达式
模板形式的lamda表达式
C++14中允许了泛型lamda表达式,让编译器自动推导类型和返回参数:
//C++14中的写法,让编译器自动推导类型和返回参数
auto lam = [](auto x, auto y)
{
return x + y;
};
//类似于以下定义
//区别在于
//Lambda表达式可以在函数内部定义,而C++的局部类不支持成员模板
struct
{
template<typename T1, typename T2>
auto operator() (T1 x, T2 y) -> decltype(x + y)
{
return x + y;
}
} lam;
而C++20中进一步,允许了模板形式的lambda表达式,
[]template<T>(T x) {
/* ... */};
[]template<T>(T* p) {
/* ... */};
[]template<T, int N>(T (&a)[N]) {
/* ... */};
有了模板形式的lamda表达式之后,
获取参数类型、类参数中的成员等特性更为直观自然:
//C++20之前: 获取 vector 元素类型, 你需要这么写
auto func = [](auto vec){
using T = typename decltype(vec)::value_type;
}
//C++20 你可以:
auto func = []<typename T>(vector<T> vec){
...
}
//方便获取通用lambda形参类型, 访问静态函数
//c++20 以前
auto func = [](auto const& x){
using T = std::decay_t<decltype(x)>;
T copy = x; T::static_function();
using Iterator = typename T::iterator;
}
//C++20 开始
auto func = []<typename T>(const T& x){
T copy = x; T::static_function();
using Iterator = typename T::iterator;
}
//完美转发
//C++20之前
auto func = [](auto&& ...args) {
return foo(std::forward<decltype(args)>(args)...);
}
//C++20之后
auto func = []<typename …T>(T&& …args){
return foo(std::forward(args)...);
}
原子(Atomic)智能指针
智能指针(shared_ptr)的线程安全性
引用计数控制单元线程安全, 保证对象只被释放一次。
但对于数据的读写没有线程安全,需要使用mutex控制智能指针的访问
或使用全局非成员原子操作函数访问, 诸如: std::atomic_load(), atomic_store(), …
在C++20中,提供了原子智能指针,来保证智能指针的安全:
template<typename T>
class concurrent_stack {
struct Node {
T t;
shared_ptr<Node> next;
};
atomic_shared_ptr<Node> head;
// C++11: 去掉 "atomic_" 并且在访问时, 需要用
// 特殊的函数控制线程安全, 例如用std::atomic_load
public:
class reference {
shared_ptr<Node> p;
<snip>
};
auto find(T t) const {
auto p = head.load(); // C++11: atomic_load(&head)
while (p && p->t != t)
p = p->next;
return reference(move(p));
}
auto front() const {
return reference(head);
}
void push_front(T t) {
auto p = make_shared<Node>();
p->t = t; p->next = head;
while (!head.compare_exchange_weak(p->next, p)){
} // C++11: atomic_compare_exchange_weak(&head, &p->next, p); }
void pop_front() {
auto p = head.load();
while (p && !head.compare_exchange_weak(p, p->next)) {
} // C++11: atomic_compare_exchange_weak(&head, &p, p->next);
}
};
std::atomic_ref
头文件
Atomic 引用
通过引用访问变为原子操作, 被引用对象可以为非原子类型
同步(Synchronization)库
信号量(Semaphore)
头文件
轻量级的同步原语
可用来实现任何其他同步概念, 如: mutex, latches, barriers, …
两种类型:
多元信号量(counting semaphore): 建模非负值资源计数
二元信号量(binary semaphore): 只有一个插孔, 两种状态, 最适合实现mutex
std::atomic
等待和通知接口
等待/阻塞在原子对象直到其值发生改变, 通过通知函数发送通知
比轮训(polling)来的更高效
方法
wait()
notify_one()
notify_all()
锁存器(Latch)和屏障(Barrier)
辅助线程条件同步
锁存器(Latches)
头文件
线程的同步点
线程将阻塞在这个位置, 直到到达的线程个数达标才放行, 放行之后不再关闭
锁存器只会作用一次
屏障(Barriers)
头文件
多个阶段,每个阶段中
一个参与者运行至屏障点时被阻塞,需要等待其他参与者都到达屏障点,
当到达线程数达标之后,阶段完成的回调将被执行
线程计数器被重置,开启下一阶段,线程得以继续执行
…
moderns c++/c++20
cppreference/c++20