2020美赛数模代码留存
前言
上午八点半提交了论文,虽然模型建得不怎么好,但好在我编写的代码提取特征and画图还算奏效,现在写下来留存一下,以后可能还会用到。
由于比赛以代码效率为主,因此在下面的一些代码中总是将提取的属性列单独存储到一个临时文件,再由队友手动把那几列更新到文件。
代码主要有以下模块
1.日期处理
2.句子分词、去符号、去停用词、词性筛除
3.实现TF-IDF模型提取关键词
4.统计月度数据
5.使用长短期记忆网络LSTM进行走势预测
代码及功能
1 .日期处理
美赛官网发放的C题数据中,日期的格式是DD/MM/YYYY,在excel中排序总是得不到正确结果。尝试在excel里更改日期格式为年月日,发现并不能奏效。由于后面要对日期按照年月日的顺序排序,所以干脆自己写了个日期格式强制转换的程序。
# *_* utf-8 *_*
import numpy as np
import pandas as pd
# 下面是用于选择日期的文件夹
fromPath = r'C:\Users\nbyuh\Desktop\test_date.csv'
# 下面是用于写入改动后日期的文件夹
toPath = r'test_date.csv'
file_name = fromPath
pdx = pd.read_csv(file_name, usecols=['review_date'], dtype=str) # 'review_body'
outputs = open(toPath, 'w', encoding='utf-8')
sent = np.array(pdx)
# print(sent)
res = []
for i in range(len(sent)):
print(sent[i,0])
sp = str(sent[i,0]).split(r'/')
length = len(sp) - 1
outputs.write(sp[2]+'/'+sp[0]+'/'+sp[1]+'\n')
outputs.close()
2 .NLP的一些流程
具体包括:句子分词、去符号、去停用词、词性筛除(只保留某类词如形容词)
由于时间原因,词形还原等没有实现、有些符号还是不能筛除、如果以后能用到再去改吧
这有一篇不错的介绍
导出数据绘制词云
part 1
# *-* coding:utf-8 *-*
import jieba
import nltk
# 创建停用词list
from nltk.corpus import stopwords
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 对句子进行分词
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist(r'C:\Users\nbyuh\Desktop\stopwords.txt') # 这里加载停用词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr
if __name__ == '__main__':
inputs = open('file_transfer/pacifier_after_devise.txt', 'r', encoding='UTF-8')
outputs = open('file_transfer/pacifier_adj.txt', 'w', encoding='UTF-8')
text = inputs.read().lower()
text_list = nltk.word_tokenize(text)
#去掉标点符号
english_punctuations = [',', '.', ':', ';', '?', '(', ')', '[', ']',
'&', '!', '*', '@', '#', '$', '%', '>', '<', '/', '``', 'br', '\"', '\'', "\'\'",
"【", "】", "★", "《", "》"]
text_list = [word for word in text_list if word not in english_punctuations]
#去掉停用词
stops = set(stopwords.words("english"))
text_list = [word for word in text_list if word not in stops]
# print(text_list)
# print((nltk.pos_tag(text_list))[0][1])
tp = nltk.pos_tag(text_list)
# 只留下名词
# nounArr = ['NN', 'NNS', 'NNP', 'NNPS']
# 只留下形容词
nounArr = ['JJ','JJR','JJS']
for i in range(len(tp)):
# NN, NNS, NNP, NNPS
if tp[i][1] in nounArr:
outputs.write(tp[i][0] + ' ')
outputs.close()
"""
for i in range(len(text_list)):
#print(text_list[i] + ' ')
outputs.write(text_list[i] + '\n')
outputs.close()
"""
#print(text_list)
#outputs.write(text_list)
"""
for line in inputs:
line_seg = seg_sentence(line) # 这里的返回值是字符串
outputs.write(line_seg + '\n')
outputs.close()
#tmp = open('./output.txt', 'w')
#st = tmp.read()
inputs.close()
"""
part 2
import numpy as np
import pandas as pd
from textblob import TextBlob
# polarity[-1, 1]
# subjectivity[0, 1]
def getEmotionScore(fromPath, toPath):
file_name = fromPath
pdx = pd.read_csv(file_name, usecols=['review_body'], dtype=str) # 'review_body'
sent = np.array(pdx)
print(len(sent))
df = pd.DataFrame()
data_arr = []
for i in range(len(sent)):
wiki = TextBlob(str(sent[i,0]))
score = round(wiki.sentiment.polarity, 3)
data_arr.append(score)
np_data = np.array(data_arr)
pd_data = pd.DataFrame(np_data)
# pd_data = pd_data.reset_index(drop=True)
#print(pd_data)
pd_data.to_csv(toPath)
def read_top15(fromPath, toPath, dicPath):
pdx = pd.read_csv(fromPath, usecols=['review_body'], dtype=str) # 'review_body'
sent = np.array(pdx)
inputs = open(dicPath, 'r')
outputs = open(toPath, 'w')
# print(inputs.read())
st = inputs.read()
ls = st.split()
print(ls)
# 写表头
for i in range(len(ls)):
outputs.write(ls[i] + ',')
outputs.write('proportion')
outputs.write('\n')
# 遍历评论统计
total_sum = 15.0
for i in range(len(sent)):
tmp = str(sent[i,0])
# 字典中是否有评论中的某个词
cnt = 0.0
for j in range(len(ls)):
if ls[j] in tmp:
cnt += 1
outputs.write('1' + ',')
else:
outputs.write('0' + ',')
outputs.write(str(round(cnt/total_sum, 3)))
outputs.write('\n')
outputs.close()
if __name__ == "__main__":
""" fromPath = r'D:\python_project\\untitled\pacifier.csv'
toPath = r'pacifier_score.csv'
# 情感打分
getEmotionScore(fromPath, toPath)
fromPath = r'D:\python_project\\untitled\microwave.csv'
toPath = r'microwave_score.csv'
getEmotionScore(fromPath, toPath)
# 读取名词 top15 并统计 0/1 出现次数 计算比率
fromPath = r'D:\python_project\\untitled\hair_dryer.csv'
dicPath = r'D:\python_project\\untitled\noun_top15\hairdryer_noun_top15.txt'
toPath = r'D:\python_project\\untitled\noun_top15\HFWordMatrix_hairdryer.csv'
read_top15(fromPath, toPath, dicPath)
"""
3 .实现TF-IDF模型提取关键词
这部分主要是使用了现有的工具包,不得不说,jieba、NLTK这些工具包是真的好用
# *_* coding:utf-8 *_*
import jieba.analyse
text = ""
inputs = open(r'file_transfer/microwave_noun.txt', encoding='utf-8')
text = inputs.read()
# 参数:文本,选择前topK个输出,是否带有权重
keywords = jieba.analyse.extract_tags(text, topK=25, withWeight=True, allowPOS=())
print(keywords)
4.统计月度数据
(1)生成的csv中属性格式形如:年份/月份, 数据总和
(2)重新生成连续月份的数据,比如原始数据是这样的:
月份,销售量
2019/12, 33
2020/3, 56
新生成的数据就是这样:
1,33
2,0
3,0
4,56
(3)将三种类别的统计数据在一个图表中
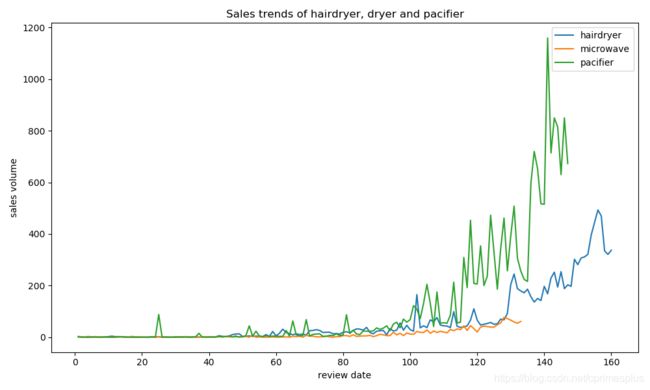
import pandas as pd
import re
import numpy as np
import matplotlib.pyplot as plt
def count_date_cnt():
ls = ['hair_dryer', 'microwave', 'pacifier']
for i in range(3):
fromPath = ls[i] + '_md.csv'
toPath = ls[i] + '_rating_md.csv'
outputs = open(toPath, 'w', encoding='utf-8')
pdx = pd.read_csv(fromPath, usecols=['review_date','emtion_score_bz'], dtype=str) # 'review_body'
sent = np.array(pdx)
cnt = 0.
st = 0
pastDate = str(sent[0, 0])
# print(sent)
outputs.write('review_date,emtion_score_bz\n')
for j in range(len(sent)):
# print(str(sent[j, 0]))
if str(sent[j, 0])[:7] == pastDate[:7]:
cnt += float(sent[j, 1])
st += 1
else:
# 计数器回退到初始数值
if pastDate[6] == '/':
outputs.write(pastDate[:6] + ',' + str(cnt/st) + '\n')
else:
outputs.write(pastDate[:7] + ',' + str(cnt/st) + '\n')
cnt = float(sent[j,1])
st = 1
pastDate = str(sent[j, 0])
# break
outputs.close()
# 重新生成月份-销量表
def regenerate_date():
ls = ['microwave', 'hairdryer', 'pacifier']
for i in range(3):
cnt_month = 1
fromPath = ls[i] + '_rating_md.csv'
toPath = 'reg_count_' + ls[i] + '_rating_md.csv'
outputs = open(toPath, 'w', encoding='utf-8')
# 在整个日期列,依次判断下一月是否是连续的
pdx = pd.read_csv(fromPath, usecols=['review_date','emtion_score_bz'], dtype=str) # 第二个标签换成分值
sent = np.array(pdx)
outputs.write('review_date,emtion_score_bz\n')
for j in range(len(sent)-1):
cur_date = int(str(sent[j,0]).split('/')[1])
next_date = int(str(sent[j+1,0]).split('/')[1])
# 先将当前月份的数据写入
outputs.write(str(cnt_month)+','+str(sent[j,1])+'\n')
# 再在cur_date 和 next_date日期差间补0数据
# d表示补0的个数
d = 0
if cur_date < next_date:
d = next_date - cur_date - 1
else:
d = 11 + next_date - cur_date
# 补0
for k in range(d):
cnt_month += 1
tmp = str(sent[j-1,1])
outputs.write(str(cnt_month)+','+str(tmp)+'\n')
cnt_month += 1
# break
def draw_predict():
ls = ['hairdryer', 'microwave', 'pacifier']
fig = plt.figure(facecolor='white',figsize=(10, 6))
ax1 = fig.add_subplot()
fromPath = 'reg_count_' + 'hairdryer' + '_rating.csv'
df = pd.read_csv(fromPath, encoding='utf-8')
df = df.set_index(['review_date'], drop=True)
plt.plot(df['star_rating_avg'],label='star_rating average')
fromPath = 'reg_count_hair_dryer_rating_md.csv'
df = pd.read_csv(fromPath, encoding='utf-8')
df = df.set_index(['review_date'], drop=True)
plt.plot(df['emtion_score_bz'], label='emotion score average')
plt.xlabel('review date')
plt.ylabel('score')
plt.title('trends of star_rating & score average')
plt.grid()
plt.legend()
plt.show()
if __name__ == '__main__':
count_date_cnt()
regenerate_date()
draw_predict()
5 .使用长短期记忆网络LSTM进行走势预测
这里使用的是其他博主的代码,原地址《简单粗暴LSTM:LSTM进行时间序列预测》
在数据集上的预测结果
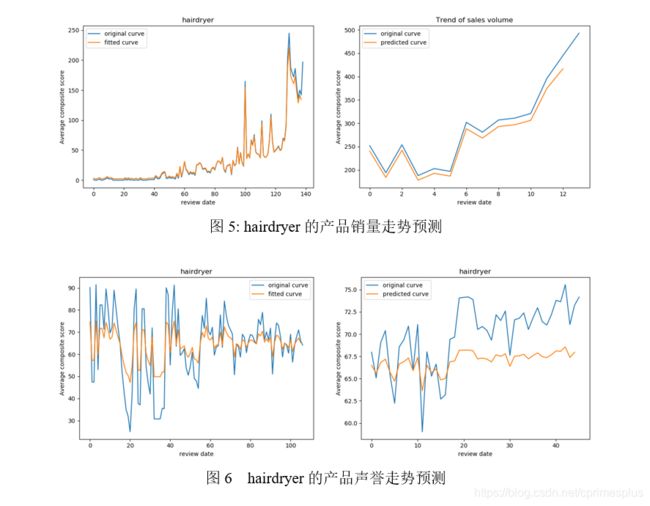
import math
import numpy
import matplotlib.pyplot as plt
from keras.losses import mean_squared_error
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
import pandas as pd
import os
from keras.models import Sequential, load_model
from sklearn.preprocessing import MinMaxScaler
dataframe = pd.read_csv('file_transfer/reg_count_hairdryer.csv', usecols=[1], engine='python', skipfooter=3)
dataset = dataframe.values
# 将整型变为float
dataset = dataset.astype('float32')
#归一化 在下一步会讲解
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
train_size = int(len(dataset) * 0.90)
trainlist = dataset[:train_size]
testlist = dataset[train_size:]
def create_dataset(dataset, look_back):
#这里的look_back与timestep相同
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return numpy.array(dataX),numpy.array(dataY)
#训练数据太少 look_back并不能过大
look_back = 1
trainX,trainY = create_dataset(trainlist,look_back)
testX,testY = create_dataset(testlist,look_back)
trainX = numpy.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1))
testX = numpy.reshape(testX, (testX.shape[0], testX.shape[1] ,1 ))
# create and fit the LSTM network
model = Sequential()
model.add(LSTM(4, input_shape=(None,1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# model.save(os.path.join("DATA","Test" + ".h5"))
# make predictions
#model = load_model(os.path.join("DATA","Test" + ".h5"))
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
#反归一化
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % trainScore)
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % testScore)
plt.xlabel('review date')
plt.ylabel('Average composite score')
plt.title('Trend of sales volume')
plt.plot(trainY,label="original curve")
plt.plot(trainPredict[1:],label="fitted curve")
plt.legend()
plt.show()
plt.xlabel('review date')
plt.ylabel('Average composite score')
plt.title('Trend of sales volume')
plt.plot(testY,label="original curve")
plt.plot(testPredict[1:],label="predicted curve")
plt.legend()
plt.show()