3构建SVHN数据集的数字识别网络
pytorch 网络构建
import torch
torch.manual_seed(0)
torch.backends.cudnn.deterministic= False
torch.backends.cudnn.benchmark = True
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
一、pytorch常用网络
1.Linear介绍 [全连接层]
nn.Linear(input_feature,out_feature,bias=True)
2.卷积介绍 [2D卷积层]
nn.Conv2d(in_channels,out_channels,kernel_size,stride=1,padding=0,
dilation=1,groups,bias=True,padding_mode='zeros')
##kernel_size,stride,padding 都可以是元组
## dilation 为在卷积核中插入的数量
3.转置卷积介绍 [2D反卷积层]
nn.ConvTranspose2d(in_channels,out_channels,kernel_size,stride=1,
padding=0,out_padding=0,groups=1,bias=True,dilation=1,padding_mode='zeros')
##padding是输入填充,out_padding填充到输出
4.最大值池化层 [2D池化层]
nn.MaxPool2d(kernel_size,stride=None,padding=0,dilation=1)
4.批量归一化层 [2D归一化层]
nn.BatchNorm2d(num_features,eps,momentum,affine=True,
track_running_stats=True)
affine=True 表示批量归一化的α,β是被学到的
track_running_stats=True 表示对数据的统计特征进行关注
https://www.jianshu.com/p/a646cbc913b4
二 pytorch 创建模型的四种方法
假设创建
卷积层–》Relu层–》池化层–》全连接层–》Relu层–》全连接层
# 导入包
import torch
import torch.nn.functional as F
from collections import OrderedDict
1.自定义型[定义在init,前向过程在forward]
class Net1(torch.nn.Module):
def __init__(self):
super(Net1, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 32, 3, 1, 1)
self.dense1 = torch.nn.Linear(32 * 3 * 3, 128)
self.dense2 = torch.nn.Linear(128, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv(x)), 2)
x = x.view(x.size(0), -1)
x = F.relu(self.dense1(x))
x = self.dense2(x)
return x

2.序列集成型[利用nn.Squential(顺序执行的层函数)]
访问各层只能通过数字索引
class Net2(torch.nn.Module):
def __init__(self):
super(Net2, self).__init__()
self.conv = torch.nn.Sequential(
torch.nn.Conv2d(3, 32, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2))
self.dense = torch.nn.Sequential(
torch.nn.Linear(32 * 3 * 3, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 10)
)
def forward(self, x):
conv_out = self.conv(x)
res = conv_out.view(conv_out.size(0), -1)
out = self.dense(res)
return out

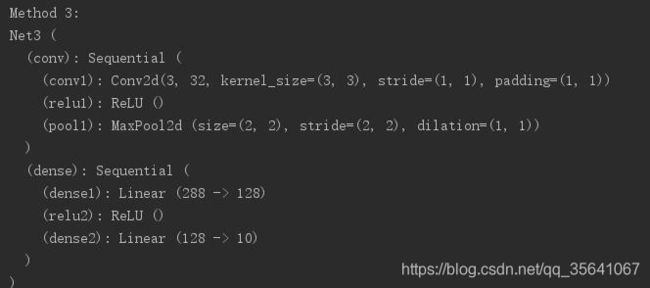
3.序列添加型[利用Squential类add_module顺序逐层添加]
给予各层的name属性
class Net3(torch.nn.Module):
def __init__(self):
super(Net3, self).__init__()
self.conv=torch.nn.Sequential()
self.conv.add_module("conv1",torch.nn.Conv2d(3, 32, 3, 1, 1))
self.conv.add_module("relu1",torch.nn.ReLU())
self.conv.add_module("pool1",torch.nn.MaxPool2d(2))
self.dense = torch.nn.Sequential()
self.dense.add_module("dense1",torch.nn.Linear(32 * 3 * 3, 128))
self.dense.add_module("relu2",torch.nn.ReLU())
self.dense.add_module("dense2",torch.nn.Linear(128, 10))
def forward(self, x):
conv_out = self.conv(x)
res = conv_out.view(conv_out.size(0), -1)
out = self.dense(res)
return out
4.序列集成字典型[OrderDict集成模型字典【‘name’:层函数】]
name为key
lass Net4(torch.nn.Module):
def __init__(self):
super(Net4, self).__init__()
self.conv = torch.nn.Sequential(
OrderedDict(
[
("conv1", torch.nn.Conv2d(3, 32, 3, 1, 1)),
("relu1", torch.nn.ReLU()),
("pool", torch.nn.MaxPool2d(2))
]
))
self.dense = torch.nn.Sequential(
OrderedDict([
("dense1", torch.nn.Linear(32 * 3 * 3, 128)),
("relu2", torch.nn.ReLU()),
("dense2", torch.nn.Linear(128, 10))
])
)
def forward(self, x):
conv_out = self.conv1(x)
res = conv_out.view(conv_out.size(0), -1)
out = self.dense(res)
return out

三 pytorch 对模型参数的访问,初始化,共享
1.访问参数
- 访问层
1.如果采用序列集成型,序列添加型或者字典集成性,都只能使用id索引访问层
eg:net[1]
2.如果想以网络的name访问,
eg:net.layer_name
- 访问参数【权重参数名:层名_weight/bias】
1.layer.params----访问该层参数字典
2.layer.weight , layer.bias-----访问该层权重和偏置
3.layer.weight.data()/grad() ------访问该层权重的具体数值/梯度【bias也使用】
4.net.collect_params() ----返回该网络的所有参数,返回一个由参数名称到实例的字典
2.初始化[若非首次初始化,force_reinit=True]
- 常规初始化【网络初始化】
- 1.init 利用各种分布初始化
net.initialize(init=init.Normal(sigma=0.1),force_reinit=True)
- 2.init 对网络参数进行常数初始化
net.initialize(init=init.Constant(1))
- 特定参数初始化
(某参数).initialize(init=init.Xavier(),force_reinit=True)
- 自定义初始化
继承init的Initialize类,并实现函数_init_weight(self,name,data)
def _init_weight(self, name, data):
print('Init', name, data.shape)
data[:] = nd.random.uniform(low=-10, high=10, shape=data.shape)
# 表示一半几率为0,一半几率为[-10,-5]U[5,10]的均匀分布
data *= data.abs() >= 5
# 调用自定义初始化函数1
net.initialize(MyInit(), force_reinit=True)
3.参数共享
- 1.参数共享,梯度共享,但是梯度计算的所有共享层的和
- 2.梯度共享,且梯度只更新一次
共享机制介绍
net = nn.Sequential()
shared = nn.Dense(8, activation='relu')
net.add(nn.Dense(8, activation='relu'),
shared,
nn.Dense(8, activation='relu', params=shared.params),
nn.Dense(10))
net.initialize()
X = nd.random.uniform(shape=(2, 20))
net(X)
net[1].weight.data()[0] == net[2].weight.data()[0]
Out[14]:
[1. 1. 1. 1. 1. 1. 1. 1.]
4.pytorch在SVHN网络构建实战
- 1.构建网络模型:继承nn.Module函数的__init__ 函数,重定义前向传播函数forward
- 2.构造优化器
- 3.构造损失函数
- 4.训练 确定几个epoch【若运用数据增广,随机增广epoch次达到多样性】
- 5.对每个batch损失函数后向传播,优化器更新参数
optimizer.zero_grad() 清空梯度
loss.backward()
optimizer.step()
4.1 普通自建网络
class SVHN_model(nn.Module):
def __init__(self):
super(SVHN_model,self).__init__()
self.cnn = nn.Squential(
nn.Conv2d(3,16,kernel_size=(3,3),stride=(2,2)), #3X64X128--> 16X31X63
nn.Relu(),
nn.MaxPool2d(2), #16X31X63--> 16X15X31
nn.Conv2d(16,32,kernel_size=(3,3),stride=(2,2)),#16X15X31--> 32X7X15
nn.Relu(),
nn.MaxPool2d(2) #32X7X15--> 32X3X7
)
# 并行五次字符预测
self.fc1 = nn.Linear(32*3*7,11)
self.fc2 = nn.Linear(32*3*7,11)
self.fc3 = nn.Linear(32*3*7,11)
self.fc4 = nn.Linear(32*3*7,11)
self.fc5 = nn.Linear(32*3*7,11)
def forward(self,x):
cnn_result = self.cnn(x)
cnn_result = cnn_result.view(cnn_result.shape[0],-1)
f1 = fc1(cnn_result)
f2 = fc2(cnn_result)
f3 = fc3(cnn_result)
f4 = fc4(cnn_result)
f5 = fc5(cnn_result)
return f1,f2,f3,f4,f5
4.2 利用resnet预训练模型
class SVHN_resnet_Model(nn.Module):
def __init__(self):
super(SVHN_resnet_Model,self).__init__()
resnet_conv = models.resnet18(pretrain=True)
resnet_conv.avgpool = nn.AdaptiveAvgPool2d(1)
resnet_conv = nn.Sequential(*list(resnet_conv.children()[:-1]))
self.cnn = model_conv
self.fc1 = nn.Linear(512,11)
self.fc2 = nn.Linear(512,11)
self.fc3 = nn.Linear(512,11)
self.fc4 = nn.Linear(512,11)
self.fc5 = nn.Linear(512,11)
def forward(self):
cnn_result = cnn(x)
cnn_result.view(cnn_result.shape[0],-1)
f1 = fc1(cnn_result)
f2 = fc2(cnn_result)
f3 = fc3(cnn_result)
f4 = fc4(cnn_result)
f5 = fc5(cnn_result)
return f1,f2,f3,f4,f5