RNN系列的目标检测
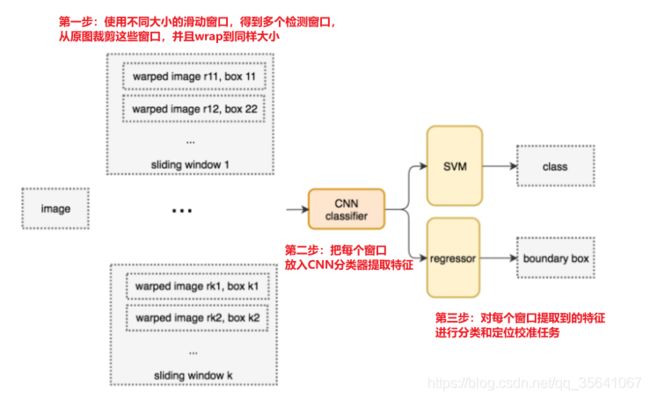
基于滑窗的CNN网络目标检测

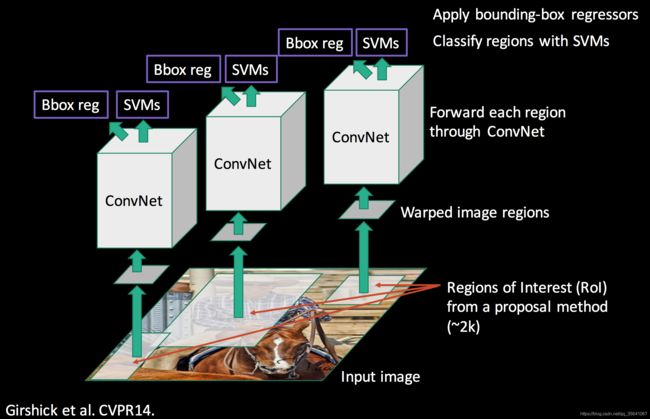
RCNN
因为基于滑动窗口的检测产生的窗口很多都是无用的窗口(不包含物体或者没有完整包含物体),所以RCNN在此基础改进窗口的获取方式,(使用selective_search产生窗口)
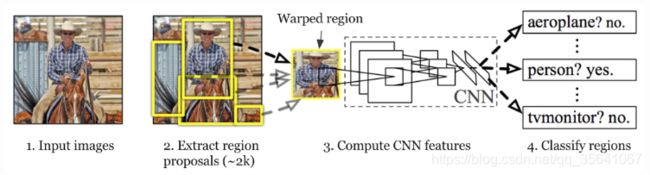
RCNN的四个步骤
1.输入图像
2.使用selective_search提取一系列的检测窗口,并从原图裁剪之后warp到固定大小记作warped region(大约2k个)
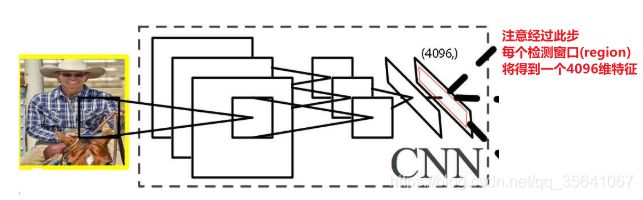
3.每个wraped region都会放入CNN分类器提取特征
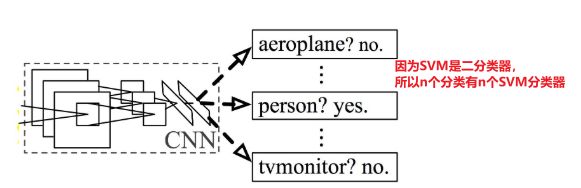
4.提取到的特征连接SVM和坐标回归器进行分类与检测
selective search
方法: 初始一张图像被划分为很多初始小区域,之后使用贪心算法不断合并两个相邻的区域,不断合并直到整张图像的每个区域合并完成。
合并原则: S ( a , b ) = S t e x t u r e ( a , b ) + S s i z e ( a , b ) S(a,b) = S_{texture}(a,b)+S_{size}(a,b) S(a,b)=Stexture(a,b)+Ssize(a,b)
其中 S t e x t u r e S_{texture} Stexture测量两个区域的相似度, S s i z e S_{size} Ssize是为了避免大区域不断吞并小区域,而是保证尽可能多的合并为小区域和更小的区域合并。

warping

从CNN分类器提取每个region的特征
SVM分类
Bounding box regressor
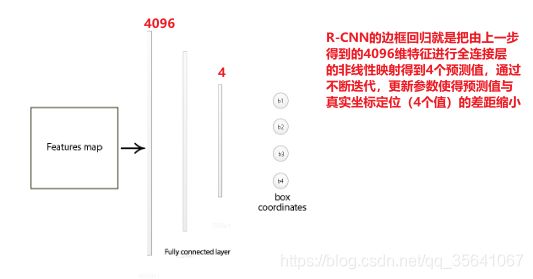
这种边框回归的过程相当于边框微调,详细回归的方法可参考一文看懂——检测模型中的边框回归

整合整个RCNN的流程
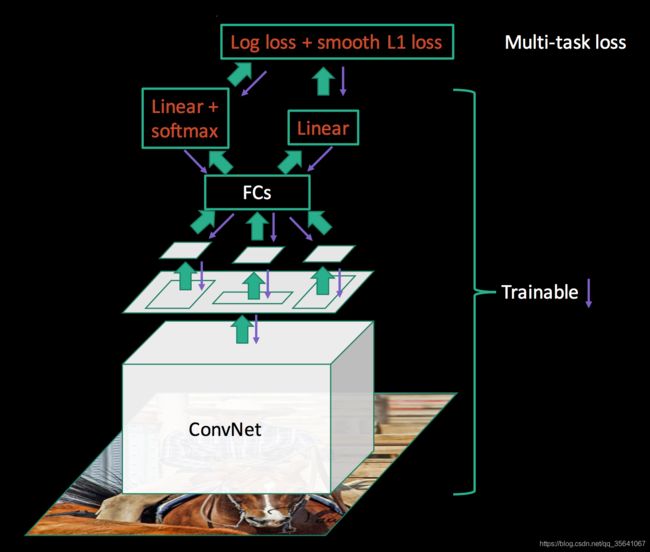
Fast RCNN
在RNN基础上的改进:
1.不使用svms分类器,改用softmax分类器
2.合并定位损失加分类损失作为总损失去更新检测网络
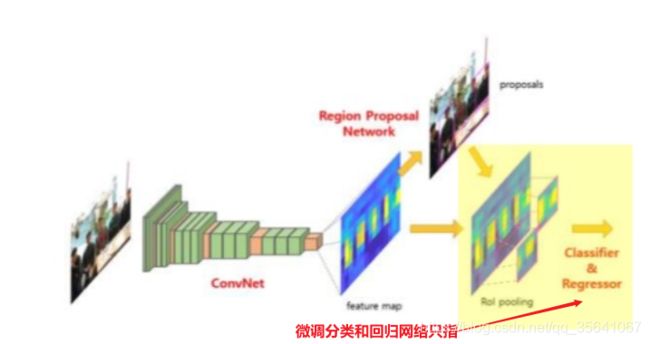
3.对于一张图像的多个region不再进行多次CNN网络提取特征,而是先对整张图像进行一次CNN网络特征提取得到特征图(feature map),在此特征图找到每个region对应的特征region
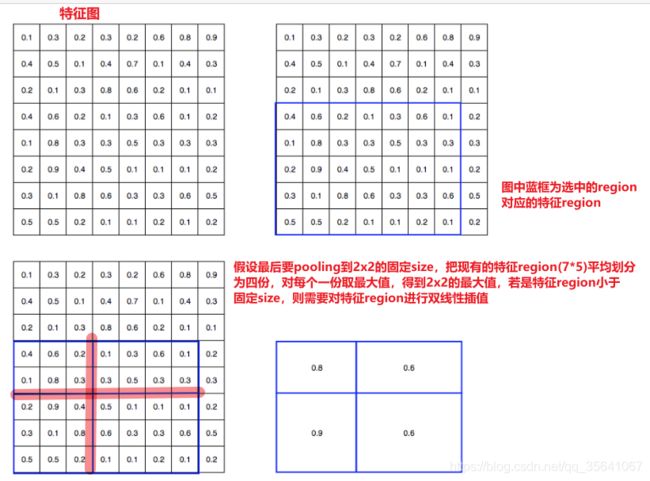
4.增加ROI(region of interest)pooling 层,此步的目的是把特征region最大池化到固定大小,原因是后面分类和回归用的全连接层只接受固定维度的输入变量
5.类别增加1类,称作背景类
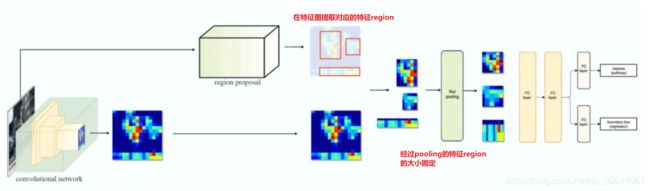
ROI pooling
合并总的损失

fast RCNN的工作流
1.预训练CNN提取网络,得到提取的特征图
2.使用selective search提取大量的ROI(大约2k)
3.在特征图上提取每个ROI对应的特征region
4.把特征region使用ROI pooling layer固定为统一的大小
5.把固定大小的特征region传入全连接进行分类和定位任务
Faster RCNN
重大改进: 不使用selective search生成ROI,而是使用一个叫做RPN(region proposal network)的网络自动生成ROI
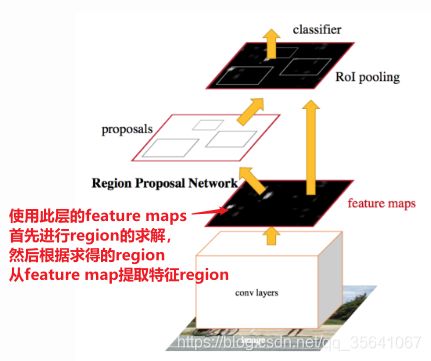
网络训练流程
1.预训练CNN特征提取网络
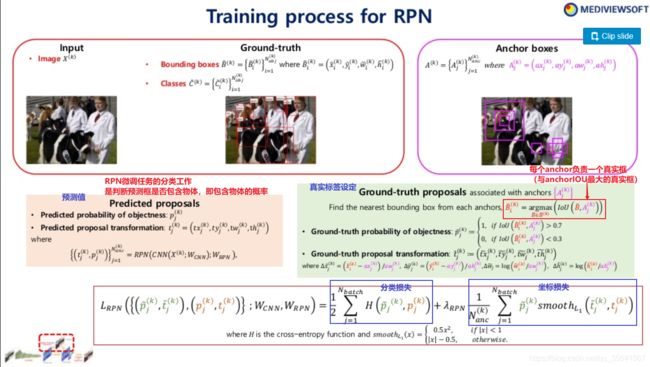
2.微调RPN网络进行region求取。任务为定位任务+正负样本区分任务(正样本:与真实框IOU为0.7【标签为region内有物体】,负样本(背景):与真实框IOU为0.3【标签为region内无物体】)
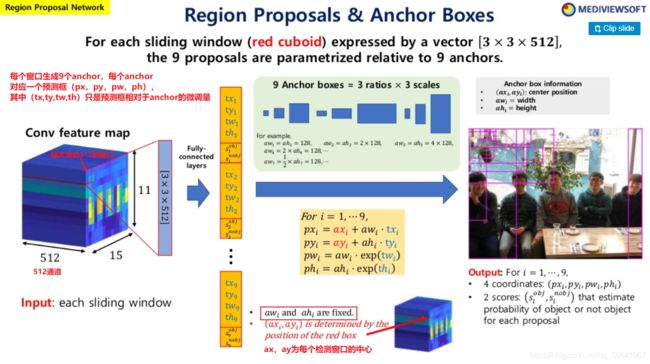
在步骤1提取到的特征图进行nxn滑动窗口,对于得到的每个检测窗口,以窗口中心为anchor的中心生成3种长宽比,3种大小总共3*3=9个anchor,而ROI就是在anchor上进行微调得到的。
3.用RPN生成的ROI训练FasterR-CNN的定位和分类(分n+1类:背景类+n类)网络
4.使RPN网络分类与定位,分类与定位网络共享同一特征提取层,对RPN网络特定的层进行参数微调
5.在第4步的基础再微调Faster-RCNN中除了特征提取网络,RPN网络之外的网络
6.如果有需要,可重复进行4,5训练FasterR-CNN和RPN网络
anchor
anchor指以检测窗口的中心为中心,生成一系列给定长宽比和大小的检测框。
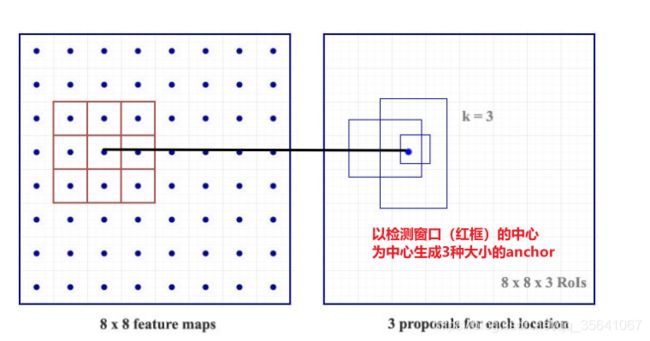
FasterRCNN引入了先验框的概念,对于待检测的物体肯定存在长宽比和大小的规律,而anchor正是输入给网络的先验知识。而预测框则是在anchor的基础上进行微调
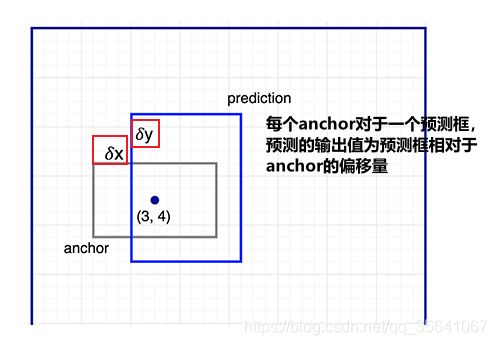
图像的anchor通过长宽比(图像大小:特征图大小)与特征图的anchor一一对应
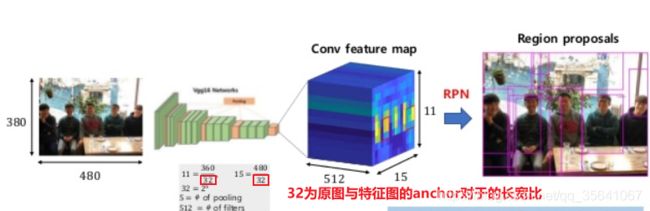
RPN
RPN的训练
微调分类(n+1类)和回归网络
直接使用FPN产生的所有预测框进行分类和回归肯定不行,因为预测框存在负样本和对同一物体进行预测的重复框,所以在进行分类和回归之前,先对预测框进行筛选。下图提到的NMS在此不做讲解。
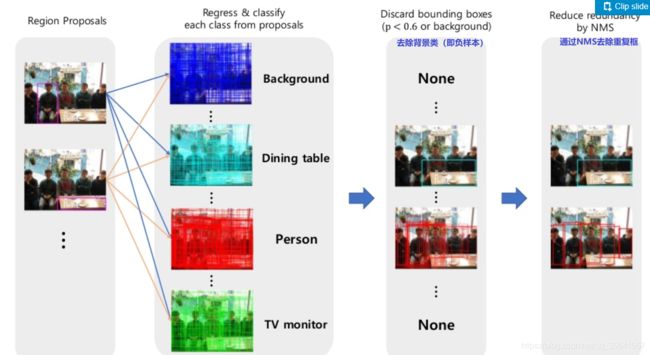
损失函数

two stage 的体现
1.先利用RPN网络生成预测框;(进行了·是否有物体判断)
2.再利用RPN网络生成的预测框进行分类与坐标回归任务。
参考文章
Object Detection for Dummies Part 3: R-CNN Family
Tutorial on Object Detection (Faster R-CNN)
What do we learn from region based object detectors (Faster R-CNN, R-FCN, FPN)?
Fast R-CNN and Faster R-CNN
深度学习目标检测算法对比详述(RCNN,FAST-RCNN,FASTER-RCNN,YOLO,SSD)