小记:记一次sort merge join导致的数据倾斜
场景
同事的一张订单表,三年共2亿条左右数据,在join多张维度表后,写回hive中。发现每次任务都耗时三小时左右。而我的另一张表,数据量也在2亿左右,同样join了多张维度表,耗时仅6分钟。
同事的任务:
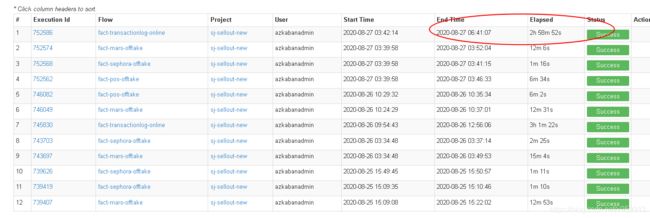
我的任务:

数据量
![]()
排查
首先到spark的历史服务web页面,找到这条任务,查看时哪个job耗时比较长,发现有个job耗时2小时:
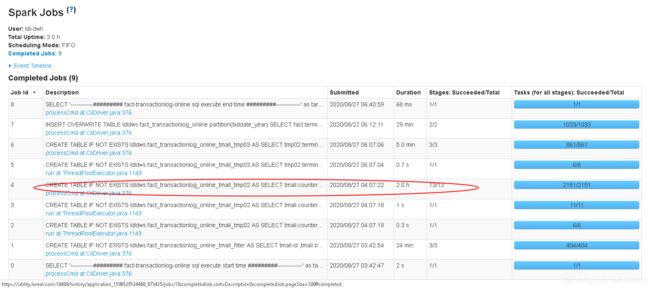
查看这个job的执行计划,发现左边的大表有99G数据,而右边的小表仅16M数据,但是使用了sort merge join。在spark conf中已经设置了数据量小于40M时自动广播join,但是没有生效。
spark.sql.autoBroadcastJoinThreshold=41485760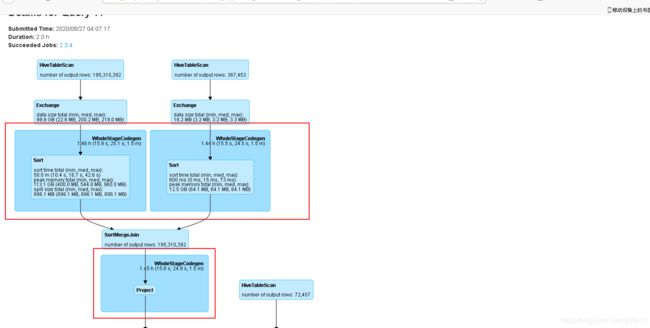 Caption
Caption
查看event time时发现,所有数据都在一个task中,其他task完全没有数据,难怪耗时这么长。

查看代码,并未发现有任何group by、distinct等聚合操作,仅有join。
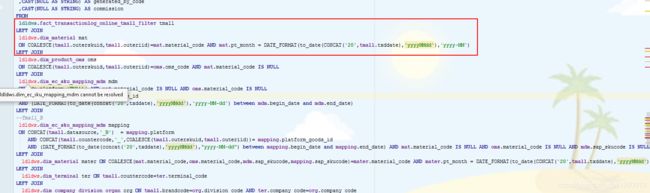
但是发现他在join其他表时,都是以整张表进行join的,正常来说,在左表join右表时,应该先对左右表进行查询,只取需要用到的列(select),并先过滤掉不需要的行(where)。这样一来可以使代码更具可读性;二来当数据量较大时,可以大大减少数据传输和运算、存储时占用的时间和内存;三来提前做子查询,spark能够感知数据量大小,当数据量小时会自动使用广播join,否则会使用sort merge join。
如一张material维度表,共有200多个字段,而实际上在这次计算中只需要用到4个字段,提前select出这四列,相当于数据量减少了98%。
我的代码:
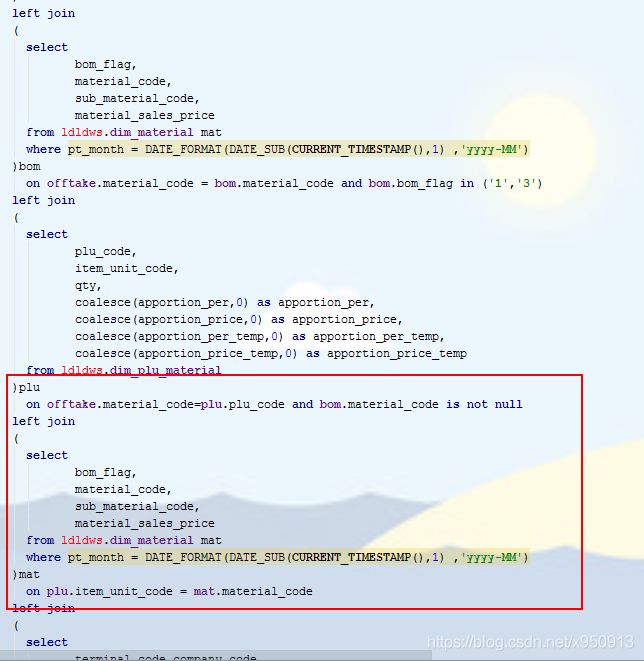
判断
看情况是所有数据都到一个task中了,但是代码中没有聚合操作,原数据(hdfs中文件大小)虽然有些倾斜(大部分为1.1G,小部分为400+M),但是也不会导致这种情况。猜测在sort merge join时,数据重新分区,导致所有数据都到一个task了,虽然这种情况很极端,但目前来看,也没有其他解释。
措施
如果将所有关联维度表都改为子查询,代码改动量大,建议同事使用broadcast关键字手动指定广播维度表,如需广播多个表,用逗号隔开。如:
SELECT
/*+ BROADCAST(mat,oms,mdm,mapping,ter,org,scs) */
tmall.countercode AS terminal_code
...
...
...
FROM
fact_transactionlog_online_tmall_filter tmall
LEFT JOIN
ldldws.dim_material mat
ON tmall.material_code=mat.material_code AND mat.pt_month = tmall.txddate_month
LEFT JOIN
ldldws.dim_product_oms oms
ON tmall.material_code=oms.oms_code AND mat.material_code IS NULL
LEFT JOIN
...
...
...
结果
修改代码后,spark执行计划如图:
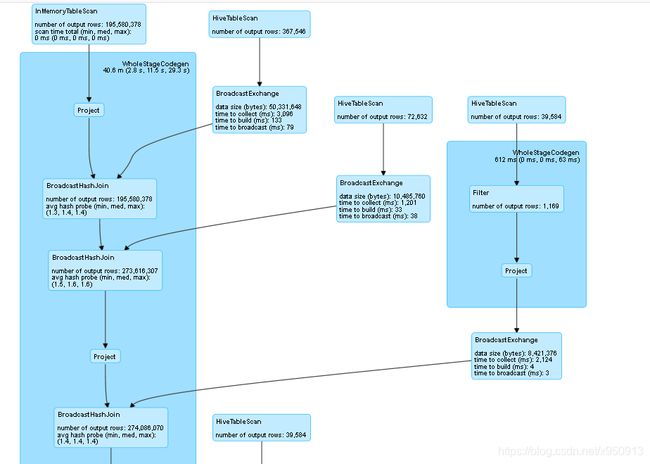
event time:
 Caption
Caption
执行总时间:
修改后执行时间减小2小时。因为同事在sql中使用create as建了中间表,数据落盘加大了运行时间,其实如果不是必要的话,最好直接做子查询,不要建立中间表,这样运行时间还可以再缩短。
总结
1.任何shuffle行为都可能发生数据倾斜,包括join。
2.任何表之间join前,应先对表做子查询,过滤多余的行或列,减小数据量。