AJAX自动化测试
AJAX自动化测试
(使用集成selenium的SigmationTF自动化测试框架对EXTJS
进行自动化测试)
1 技术背景
本文主要介绍如何利用SigmationTF的Selenium插件进行基于ExtJS及类似框架的Web GUI的自动化测试。
l SigmationTF作为成都杰华科技的旗舰产品,已经为不同领域的许多客户实现了多类产品测试自动化。这其中包括防火墙、路由器、交换机、无线Mesh以及网管产品生产设备厂商。SigmationTF作为一个通用平台,集成了大量开源软件辅助用户完成自动化测试。
l Selenium 支持录制回放,多浏览器的Web自动化测试工具
l Ext JS是一种用JavaScript编写的功能强大的Ajax框架,可用于开发绚丽多彩的富客户端Ajax应用。
阅读本文的读者最好需要了解以下技术或编程脚本语言:selenium + perl
SigmationTF: http://www.sigma-rt.com
Selenium: http://seleniumhq.org/
2 问题与挑战
随着网络技术的发展,良好的用户体验及丰富的客户端功能已经成为Web程序所共同追求的目标,并扮演非常重要的一环。基于AJAX应用的盛行,Prototype,ExtJS, ZK, Yui等越来越多的第三方开源JavaScript Library开始涌现,并为大众所广泛利用。虽然这极大地增加了我们对Web应用的扩展可能性,但同时也为我们的WebGUI自动化提出了新的难题。
2.1 动态ID
通过Selenium对ExtJS类似框架页面进行测试的最大障碍是这些框架大量利用了大量动态的div、iframe,并且包含了大量非标准的HTML元素。事实上,ExtJS通过大量冗余的元素来使页面看起来更美观,提升用户体验,但却极大的干扰了Selenium IDE录制生成脚本的可维护性。如下所示利用Selenium IDE录制的Google Mail的脚本,如果用户想要通过Selenium IDE简单录制生成的脚本对象进行回归和自动化,确实是相当困难。
当用户通过Selenium IDE来录制在浏览器内的操作并自动生成相应的命令和定位器时,Selenium将主要基于HMTL元素的IDs。但事实上,几乎绝大部分的可点击的元素、按钮,它们的ID都是由ExtJS统一自动生成的。因而我们可以通过分析工具(Firebug)看到很多类似于”ext-gen-123”的元素ID,同时细心的用户还会发现,在不同的浏览器内,页面元素的ID是不一样的。页面稍微改动,ID同样会发生变化。甚至于ID会由于我们点击页面元素的顺序差异而发生变化,但此时,是没有人进行过任何代码修改的。由此可想而知,通过Selenium IDE录制生成脚本的可靠性。
2.2 事件触发
通过selenium IDE 录制到的点击操作为click, 但是到实际用selenium RC 来执行$sel->click($locator)的命令,却发现click后事件并未触发。
2.3 等待页面加载
Selenium提供了一系列用于执行用户操作并等待页面装载和响应的*AndWait函数。但是,由于AJAX使用部分页面装载技术以增加用户体验,因而,这些命令将不再适用于非同步装载的AJAX页面。
2.4 选择执行效率高的locator
Selenium支持多个浏览器,也提供多种locator的格式来实现页面元素的定位。但是选择一个执行效率高的locator类型是我们要讨论的。
3 解决方案
3.1 定位动态ID
3.1.1选择页面分析工具
既然不能完全依靠录制,我们又如何了解和分析页面呢?这里我们推荐大家使用基于Internet Explorer IEDevtoolbar或者基于Firefox的插件Firebug。
- IEDevToolbar
http://www.microsoft.com/downloadS/details.aspx?familyid=E59C3964-672D-4511-BB3E-2D5E1DB91038&displaylang=en
- Firebug
https://addons.mozilla.org/en-US/firefox/addon/1843

从个人 角度来说,Firebug更易于使用。在任何情况下,用户在Firefox浏览器中只需要点击右键并选择”Inspect Element”,则会自动呼出Firebug窗口,并显示页面上当前鼠标位置所在元素的相关属性。本文基于页面元素分析的抓图都将使用Firebug。
HTML DOM 把 HTML 文档呈现为带有元素、属性和文本的树结构(节点树)。通过DOM,我们还可以充分利用JavaScript的灵活性。
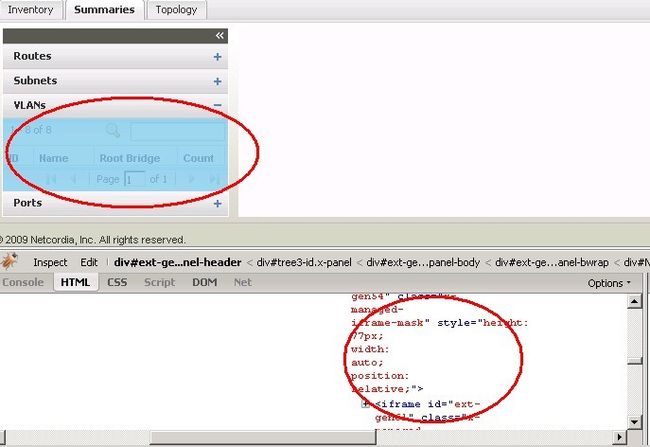
如图所示,这个页面中面板套面板,且数据都是动态生成的。像这里点击”VLANS”之后,其对应数据区的IFRAME才开始装载。我们如果要获取该数据区的内容,按照Selemium的约定,我们必须先切换到该IFRAME。ID是动态生成的,我们不能使用,通过class,这里有多个IFRAME。那应该怎么办呢?
我们通过Firebug分析发现,每个抬头(Routes, Subnets, VLANs)都对应有各自的IFRAME。首先我们可以通过:
$locator=”css=.x-panel-header-text:contains(‘VLANs’)”
找到VLANS这个元素对象,再按照dom树回溯父节点两次后取第一项,我们就可以得到这个IFRAME.
假设e为VLANS元素对象,那么IFRAME应该是
e.parentNode.parentNode.getElementsByTagName(‘iframe’)[0];
但这完全是两个定位方法,我们如何组合他们呢?
这里我们需要擎出Selenium内部的API 了:
sub extjs_select_header_frame {
my ($browser, $header) = @_;
my $locator = “dom=var header=this.browserbot.findElement(‘css=.x-panel-header-text:contains(\\'$header\\')');” .
“header.parentNode.parentNode.getElementsByTagName(‘iframe’)[0]”;
if (!$browser->is_element_present($locator)) {
die(“Can not find iframe for tab header `$header’”);
}
$browser->select_frame($locator);
print “Now switch to frame of tab header `$header’, and location is “ .
$browser->get_location() . “\n”;
}
这里我们通过selenium对象的browserbot属性中的findElement方法首先通过CSS 定位器找到抬头对象,然后再通过回溯DOM树得到IFRAME。
充分利用DOM和Selenium Core本身的特性,我们不仅可以高效率的精确定位页面元素,同时也可以保证脚本的可读性和易维护性
上一小节我们见识了DOM与JavaScript结合的威力。实际上,灵活运用JavaScript,它的能力远不止此。本节将以获取结构化的ExtJS 网格(Grid)控制数据为例,向用户展示更多活用JavaScript的例子。
我们先抛开分页信息,只管取当前页面的数据。这里是一个示意的页面图片。
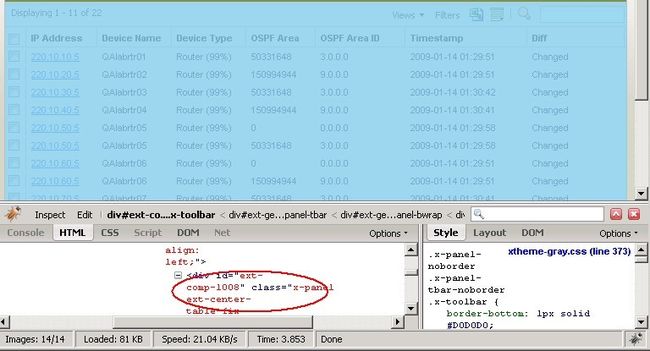
通过Firebug,我们可以首先找到class(CSS locator)为x-grid-panel的div节点,它会有个类似于“ext-comp-1008”的ID,这个ID是ExtJS的组件ID,它不同于”ext-gen12”类似ID,是不会改变的。同时这个ID也可以由Web developer定义。借助于Firebug,我们可以看到,网格中的数据都在这个里面了。
再分析节点下的数据:

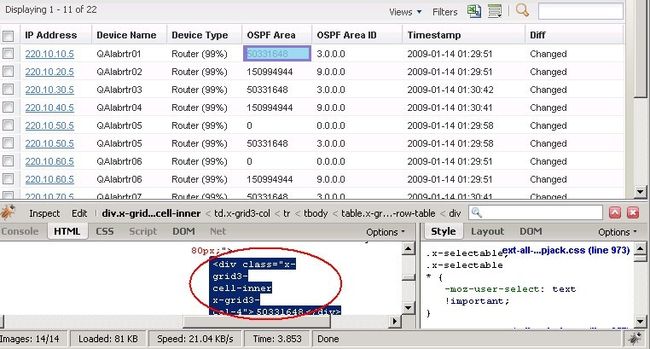
网格中的每一记录,都存放在一个class为“x-grid3-row-table”的表格中
看看每一列的情况:
有了这些,可以先写个函数取网格中的每行数据了:
sub extjs_get_grid_row {
my ($browser, $grid, $row) = @_;
my $script = "var doc = this.browserbot.getCurrentWindow().document;\n" .
"var grid = doc.getElementById('$grid');\n" .
"var table = grid.getElementsByTagName('table');\n" .
"var result = '';\n" .
"var row = 0;\n" .
"for (var i = 0; i < table.length; i++) {\n" .
" if (table[i].className == 'x-grid3-row-table') {\n".
" row++;\n" .
" if (row == $row) {\n" .
" var cols_len = table[i].rows[0].cells.length;\n" .
" for (var j = 0; j < cols_len; j++) {\n" .
" var cell = table[i].rows[0].cells[j];\n" .
" if (result.length == 0) {\n" .
" result = getText(cell);\n" .
" } else { \n" .
" result += '|' + getText(cell);\n" . ## 把每行数据通过“|”串行来,当然,如果网格中数据包含有“|”,那就只能换别的了。
" }\n" .
" }\n" .
" }\n" .
" }\n" .
"}\n" .
"result;\n"; ## get_eval获取的是最后一个表达式的结果。
my $result = $browser->get_eval($script); ##拿到我们想要的数据了,:)
my @res = split('\|', $result);
return @res;
}
依葫芦画瓢,再加个取当前页面网格行数的:
sub extjs_get_grid_row_num {
my ($browser, $grid) = @_;
my $script = "var doc = this.browserbot.getCurrentWindow().document;\n" .
"var grid = doc.getElementById('$grid');\n" .
"var table = grid.getElementsByTagName('table');\n" .
"var row = 0;\n" .
"for (var i = 0; i < table.length; i++) {\n" .
" if (table[i].className == 'x-grid3-row-table') {\n".
" row++;\n" .
" }\n" .
"}\n" .
"row;\n";
my $result = $browser->get_eval($script);
return $result;
}
有了这两个基础的API,对用户来说,获取当前页面指定网格的所有数据,并以二维数组的形式返回结果,自然不是什么难事。
看过了上面的介绍,让我们来看看网格的分页信息。顺便再次回顾一次CSS定位器。
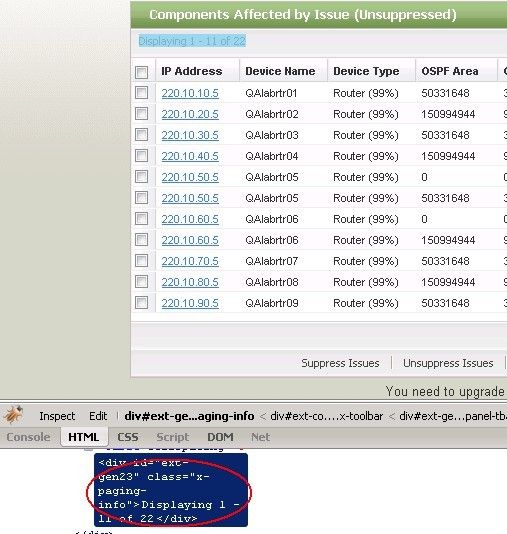
用我们提到的CSS,把页面的分页信息拿下:
sub extjs_get_paging_info {
my ($browser) = @_;
my $locator = “css=.x-paging-info”;
my $paging = $browser->get_text($locator); # 取到 “Displaying 1 – 11 of 22”
my @matches = $paging =~ /([0-9]+) - ([0-9]+) of ([0-9]+)/; #处理一下,只拿我们所关心的起始记录和总记录数
return @matches;
}
当然了,翻页的按钮肯定得找到:

sub extjs_goto_next_page {
my ($browser) = @_;
my @pages = extjs_get_paging_info($browser);
# 打印当前页数
print “Current page: “ . $browser->get_text("css=.x-tbar-page-number") . “\n”;
# 点击“下一页”按钮
if (@pages[1] < @pages[2]) {
$browser->click("css=.x-tbar-page-next");
} else {
print “Reach to ending page\n”;
}
}
3.2 等待页面加载
3.2.1 wait_for_element_present替代wait_for_page_to_load
因为Wait_for_page_to_load 函数失效, 建议用户多使用wait_for_element_present。在Selenium RC的Perl 驱动中,未提供有waitForElementNotPresent 的接口,但是我们可以通过执行Javascript来调用或者自行进行扩展。
示例:
$browser->wait_for_element_present($locator);
$browser->click($locator);
3.2.2 自己封装等待页面加载函数
EXT-JS为局部页面加载,需要遍历整张HTML的表格中的frame, iframe 的readaystate的状态,可以写一个递归函数来实现,限于篇幅就不具体说明。
3.3 解决事件触发问题
一些基于ExtJS页面的HTML元素不能为”click”命令所触发。比如ExtJS中面板的Tab,但是我们可以模拟鼠标点击操作。
$browser->mouse_down_at(“css=.x-tab-strip-text:contains('Options')”, “0,0”);
如果遇到click触发事件失败,请结合使用mouse_down, mouse_up, mouse_down_at此类函数使用
3.4选择执行效率高的locator
根据以往经验,在不同浏览器上,xpath, CSS的执行效率都低于dom, javascripts. 所以如果要支持多个版本的浏览器,建议选择DOM 和javascsripts.