NLP入门_Datawhale
1.背景
参加了Datawhale NLP入门学习,天池链接:https://tianchi.aliyun.com/competition/entrance/531810/information
2.解题思路赛题
思路分析:赛题本质是一个文本分类问题,需要根据每句的字符进行分类。但赛题给出的数据是匿名化的,不能直接使用中文分词等操作,这个是赛题的难点。
因此本次赛题的难点是需要对匿名字符进行建模,进而完成文本分类的过程。由于文本数据是一种典型的非结构化数据,因此可能涉及到特征提取和分类模型两个部分。为了减低参赛难度,我们提供了一些解题思路供大家参考:
思路1:TF-IDF + 机器学习分类器
直接使用TF-IDF对文本提取特征,并使用分类器进行分类。在分类器的选择上,可以使用SVM、LR、或者XGBoost。
思路2:FastText
FastText是入门款的词向量,利用Facebook提供的FastText工具,可以快速构建出分类器。
思路3:WordVec + 深度学习分类器
WordVec是进阶款的词向量,并通过构建深度学习分类完成分类。深度学习分类的网络结构可以选择TextCNN、TextRNN或者BiLSTM。
思路4:Bert词向量
Bert是高配款的词向量,具有强大的建模学习能力。
2.数据读取与数据分析
2.1 数据读取
![]()
这里的read_csv由三部分构成:
- 读取的文件路径,这里需要根据改成你本地的路径,可以使用相对路径或绝对路径;
- 分隔符sep,为每列分割的字符,设置为\t即可;
- 读取行数nrows,为此次读取文件的函数,是数值类型(由于数据集比较大,建议先设置为100);
2.2 描述性分析
在读取完成数据集后,我们还可以对数据集进行数据分析的操作。虽然对于非结构数据并不需要做很多的数据分析,但通过数据分析还是可以找出一些规律的。
此步骤我们读取了所有的训练集数据,在此我们通过数据分析希望得出以下结论:
- 赛题数据中,新闻文本的长度是多少?
- 赛题数据的类别分布是怎么样的,哪些类别比较多?
- 赛题数据中,字符分布是怎么样的?
句子长度分析
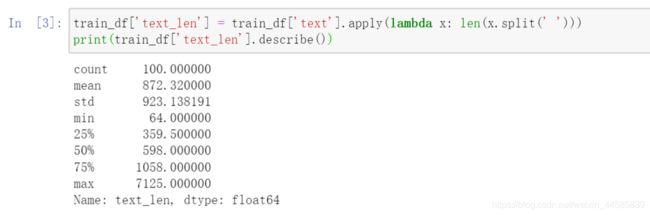
这里使用lambda表达式快速添加句子长度列,值得学习
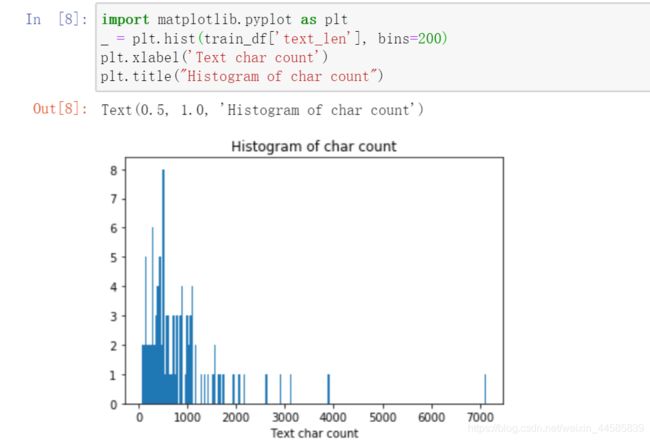
新闻类别分布
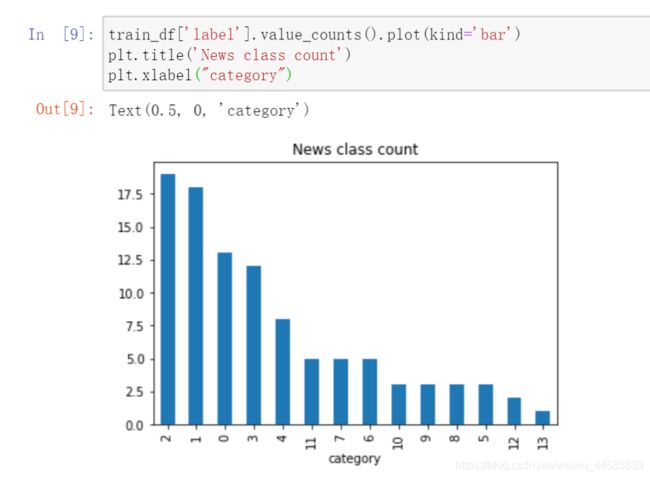
字符分布统计
2.3 数据分析结论
通过上述分析我们可以得出以下结论:
- 赛题中每个新闻包含的字符个数平均为1000个,还有一些新闻字符较长;
- 赛题中新闻类别分布不均匀,科技类新闻样本量接近4w,星座类新闻样本量不到1k;
- 赛题总共包括7000-8000个字符;
通过数据分析,我们还可以得出以下结论:
- 每个新闻平均字符个数较多,可能需要截断;
- 由于类别不均衡,会严重影响模型的精度;
3. 基于机器学习的文本分类
机器学习是对能通过经验自动改进的计算机算法的研究。机器学习通过历史数据训练出模型对应于人类对经验进行归纳的过程,机器学习利用模型对新数据进行预测对应于人类利用总结的规律对新问题进行预测的过程。
3.1 文本表示方法
One-hot:与数据挖掘任务中的操作是一致的,即将每一个单词使用一个离散的向量表示。具体将每个字/词编码一个索引,然后根据索引进行赋值。会形成稀疏矩阵,在深度学习训练过程中会出现收敛慢的现象。
Bag of Words:也称为Count Vectors,每个文档的字/词可以使用其出现次数来进行表示,可以直接使用CountVectorizer实现
N-gram:N-gram与Count Vectors类似,不过加入了相邻单词组合成为新的单词,并进行计数,加入N个相邻单词。
3.2 基于机器学习的文本分类
# Count Vectors + RidgeClassifier
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import f1_score
train_df = pd.read_csv('../data/train_set.csv', sep='\t', nrows=15000)
vectorizer = CountVectorizer(max_features=3000)
train_test = vectorizer.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
# 0.74
# TF-IDF + RidgeClassifier
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import f1_score
train_df = pd.read_csv('../data/train_set.csv', sep='\t', nrows=15000)
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=3000)
train_test = tfidf.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
# 0.87