Python-泰坦尼克号生存率预测
链接: kaggle算法泰坦尼克号生存率预测.
1. 准备工具
# 导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
#准备前置工作
sns.set(style='darkgrid') #使用画图风格
warnings.filterwarnings('ignore') #忽略警告
%matplotlib inline
2. 读取数据
train_data = pd.read_csv(r'titanic\train.csv')
test_data = pd.read_csv(r'titanic\test.csv')
3. 先观察数据内容
先观察训练集数据:
train_data.head()

- PassengerId:旅客序号,对生存率无影响
- Survived:生存(目标值)(“0”代表死亡,“1”代表生存)
- Pclass:阶层,社会地位 (分为1,2,3阶层,1阶层地位最高)
- Name:旅客姓名
- Sex:性别
- Age:年龄
- SibSp:船上的兄弟姐妹和配偶数量;
- Parch:船上的父母子女数量;
- Ticket:船票
- Fare:票价
- Cabin:船舱
- Embarked:登船点
查看数据基本描述
train_data.describe()
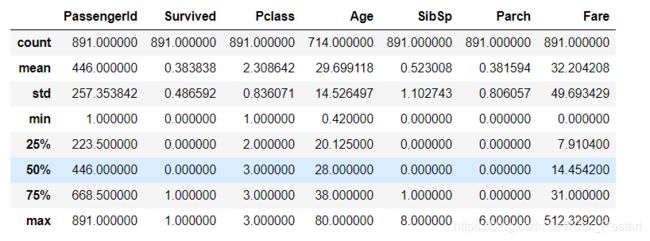
训练集一共有891人,很明显“年龄”存在缺失值,再具体查看哪些特征值还包含缺失值。
train_data.isnull().sum()
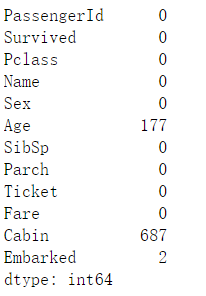
训练集:“Age”缺失177个,“Cabin”缺失687个,“Embarked”缺失2个。由于“Cabin”缺失数量比较多,该特征值难以填补,预测时将会删除。
再看看测试集特征值缺失情况(方便分析中一起填补):
test_data.isnull().sum()

测试集:“Age”缺失86个,“Cabin”缺失327个,“Fare”缺失1个。
4. 观察各特征值因素对生存率的影响
4.1 幸存者总体情况
fig,ax=plt.subplots(1,2,figsize=(16,7))
train_data.Survived.value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True,fontsize=13)
ax[0].set_title('Survived',fontsize=13)
ax[0].set_ylabel('')
sns.countplot('Survived',data=train_data,ax=ax[1])
ax[1].set_title('Survived',fontsize=13)
for y, x in enumerate(train_data.Survived.value_counts()):
plt.text(y, x , x, fontsize=13)
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
plt.show()

训练集中总人数为891人,其中幸存者342人,占比38.4%,生存率比较低。
4.2 性别因素影响的情况
pd.crosstab(train_data['Sex'],train_data['Survived'],margins=True).style.background_gradient(cmap='Greens')
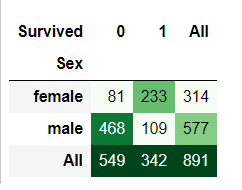
pd.crosstab(train_data['Sex'],train_data['Survived'],normalize=0,margins=True).style.background_gradient(cmap='Greens')

fig,ax = plt.subplots(1,2,figsize=(18,8))
train_data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived vs Sex',fontsize=13)
sns.countplot('Sex',hue='Survived',data=train_data,ax=ax[1])
ax[1].set_title('Sex:Survived vs Dead',fontsize=13)
plt.show()

登船人数中,女性一共314人,男性577人,女性生存率为74.20%,男性为18.89%,女性生存率远高于男性。该特征值为重要特征值。
4.3 社会地位因素影响的情况
pd.crosstab(train_data['Pclass'],train_data['Survived'],margins=True).style.background_gradient(cmap='Greens')

pd.crosstab(train_data['Pclass'],train_data['Survived'],normalize=0,margins=True).style.background_gradient(cmap='Greens')

fig,ax=plt.subplots(1,2,figsize=(18,8))
train_data['Pclass'].value_counts().plot.bar(color=['darkgreen','lightseagreen','skyblue'],ax=ax[0])
ax[0].set_title('Number of Passengers By Pclas',fontsize=13)
ax[0].set_ylabel('Count')
sns.countplot('Pclass',hue='Survived',data=train_data,ax=ax[1])
ax[1].set_title('pclas:Survived vs Dead',fontsize=13)
plt.show()

1阶层生存率最高,约63%;3阶层人数最多,生存率最低,约24%;2阶层比较均衡。特征值为重要特征值。
4.4 性别与社会地位因素共同影响的情况
pd.crosstab([train_data.Sex,train_data.Survived],train_data.Pclass,margins=True).style.background_gradient(cmap='Greens')

sns.factorplot('Pclass','Survived',hue='Sex',data=train_data)
plt.show()
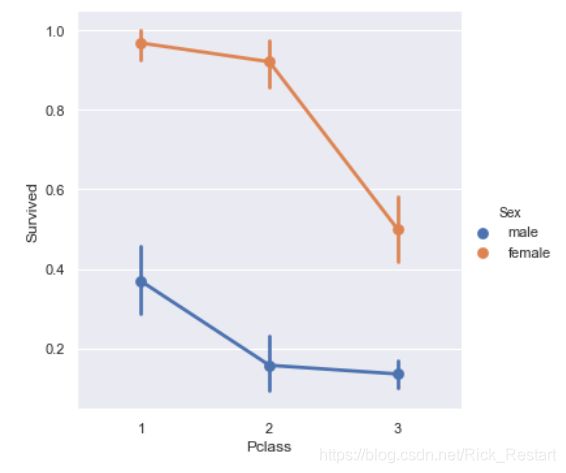
无论处于哪个阶层,女性的生存率始终比男性高,两因素相比,“性别”特征值的重要性大于“阶层”。(女士优先)
4.5 年龄因素影响的情况
年龄存在缺失值,先观察年龄的基本情况。
train_data.Age.describe()

最小值为0.42岁(5个多月?),最大值为80岁。缺失177个数据。
fig,ax=plt.subplots(1,2,figsize=(18,8))
sns.violinplot('Pclass','Age',hue='Survived',data=train_data,split=True,ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived',fontsize=13)
ax[0].set_yticks(range(0,110,10))
sns.violinplot('Sex','Age',hue='Survived',data=train_data,split=True,ax=ax[1])
ax[1].set_title('Sex and Age vs Survived',fontsize=13)
ax[1].set_yticks(range(0,110,10))
plt.show()

年龄分布基本集中在20-38岁之间,从上图数据观测,年龄偏小的生存率比年龄偏大的生存率高。(小孩优先)
填充年龄缺失值
根据名字中的称呼分组,计算各组年龄均值作为缺失值填充依据。
训练集
train_data['Initial']=train_data.Name.str.extract('([A-Za-z]+)\.')
pd.crosstab(train_data.Sex,train_data.Initial)

各称谓年龄分布
pd.pivot_table(train_data,index=["Initial"],values=["Age"],aggfunc=[np.mean,len],margins=True)

train_data.Initial.value_counts().plot.bar()
plt.title("train_data['Initial'].count")
fig=plt.gcf()
fig.set_size_inches(18,5)
plt.show()

头衔的解读:(归类)
-
Mr:既可以用于已婚男性,也可以用于未婚男性
-
Mrs:已婚女士
-
Miss:称呼未婚女士,有时也用于自己不了解的年龄较大的妇女
-
Master:男童或男婴
-
Don:大学老师
-
Rev:牧师
-
Dr:医生或者博士
-
Mme:女士
-
Ms:既可以用于已婚女士也可以用于未婚女士
-
Major:陆军少校
-
Lady:公侯伯爵的女儿
-
Sir:上级长官
-
Mile:小姐
-
Col:上校(常用于陆空军)
-
Capt:船长
-
Countess:伯爵夫人
-
Jonkheer:乡绅
再观察训练集缺失值的称谓:
train_data[train_data.Age.isnull()].groupby('Initial')['Initial'].count()

训练集的称谓分布基本集中在:Mr,Miss,Mrs,Master,缺失值也基本集中在这些称谓中。
测试集
test_data['Initial']=test_data.Name.str.extract('([A-Za-z]+)\.')
pd.crosstab(train_data.Sex,train_data.Initial).style.background_gradient(cmap='Greens')

pd.pivot_table(test_data,index=["Initial"],values=["Age"],aggfunc=[np.mean,len],margins=True)
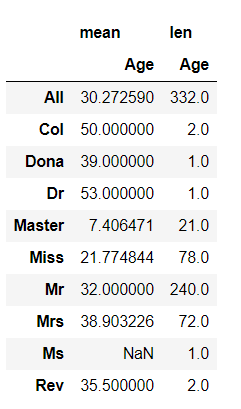
test_data.Initial.value_counts().plot.bar()
plt.title("test_data['Initial'].count")
fig=plt.gcf()
fig.set_size_inches(18,5)
plt.show()

再观察测试集缺失值的称谓:
test_data[test_data.Age.isnull()].groupby('Initial')['Initial'].count()

测试集的称谓分布基本集中在:Mr,Miss,Mrs,Master,缺失值也基本集中在这些称谓中。
缺失值填充按训练集与测试集数据拼接后的平均值进行填充。
train_AI = train_data[['Age','Initial']]
test_AI = test_data[['Age','Initial']]
tt_AI = pd.concat((train_AI,test_AI))
pd.pivot_table(tt_AI,index=["Initial"],values=["Age"],aggfunc=[np.mean,len],margins=True)

Age缺失值填充
训练集Age缺失值填充
train_data.loc[(train_data.Age.isnull())&(train_data.Initial=='Dr'),'Age']=44
train_data.loc[(train_data.Age.isnull())&(train_data.Initial=='Master'),'Age']=6
train_data.loc[(train_data.Age.isnull())&(train_data.Initial=='Miss'),'Age']=22
train_data.loc[(train_data.Age.isnull())&(train_data.Initial=='Mr'),'Age']=33
train_data.loc[(train_data.Age.isnull())&(train_data.Initial=='Mrs'),'Age']=28
测试集Age缺失值填充
test_data.loc[(test_data.Age.isnull())&(test_data.Initial=='Master'),'Age']=6
test_data.loc[(test_data.Age.isnull())&(test_data.Initial=='Miss'),'Age']=22
test_data.loc[(test_data.Age.isnull())&(test_data.Initial=='Mr'),'Age']=33
test_data.loc[(test_data.Age.isnull())&(test_data.Initial=='Mrs'),'Age']=37
test_data.loc[(test_data.Age.isnull())&(test_data.Initial=='Ms'),'Age']=28
检查数据是否填充成功
In: train_data.Age.isnull().sum()
Out:0
In: test_data.Age.isnull().sum()
Out:0
填充数据后再观察数据:
fig=plt.figure(figsize=(18,16))
ax1=fig.add_subplot(2,2,1)
sns.violinplot('Pclass','Age',hue='Survived',data=train_data,split=True,ax=ax1)
ax1.set_title('Pclass and Age vs Survived(Comparison with the original data)',fontsize=13)
ax2=fig.add_subplot(2,2,2)
sns.violinplot('Sex','Age',hue='Survived',data=train_data,split=True,ax=ax2)
ax2.set_title('Sex and Age vs Survived(Comparison with the original data)',fontsize=13)
ax3=fig.add_subplot(2,2,3)
x1=list(range(0,85,5))
ax3.set_xticks(x1)
train_data[train_data['Survived']==0].Age.plot.hist(ax=ax3,bins=20,edgecolor='black',color='darkred')
ax3.set_title('Survived= 0',fontsize=13)
ax4=fig.add_subplot(2,2,4)
train_data[train_data['Survived']==1].Age.plot.hist(ax=ax4,color='darkgreen',bins=20,edgecolor='black')
ax4.set_title('Survived= 1',fontsize=13)
x2=list(range(0,85,5))
ax4.set_xticks(x2)
plt.show()
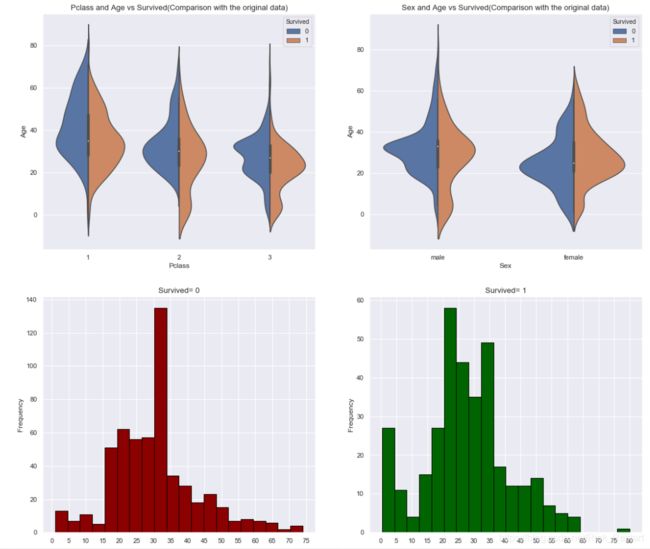
Age缺失值填充完与原数据(含缺失值)在形态上并没太大出入。死亡人数与生存人数基本集中在15-35岁之间,这与船上人员的年龄分布相符合,值得注意的是0-15岁之间获救的人数也比较多。
结合社会地位观察主要年龄段(称谓)生存率的趋势
train_Initial_find=train_data[(train_data.Initial=='Miss')|(train_data.Initial=='Mr')|(train_data.Initial=='Mrs')|(train_data.Initial=='Master')]
sns.factorplot('Pclass','Survived',col='Initial',data=train_Initial_find)
plt.show()

几乎各年龄段的社会地位越低,生存率越低。
4.6 登船点因素影响的情况
pd.crosstab([train_data.Embarked],train_data.Survived,margins=True).style.background_gradient(cmap='Greens')
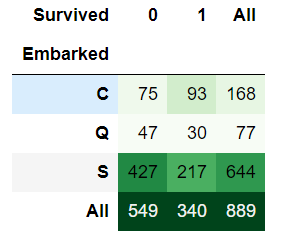
fig = plt.figure(figsize=(18,6))
ax1 = fig.add_subplot(1,3,1)
ax1 = sns.countplot('Embarked',data=train_data)
for y, x in enumerate(train_data.Embarked.value_counts()):
plt.text(y, x , x, fontsize=13,horizontalalignment='center')
ax1.set_title('Embarked Total number of people')
ax2 = fig.add_subplot(1,3,2)
ax2 = sns.countplot('Embarked',hue='Survived',data=train_data)
ax2.set_title('Embarked vs Survived Total number of people')
ax3=fig.add_subplot(1,3,3)
ax3 =sns.barplot('Embarked','Survived',data=train_data)
ax3.set_title('Embarked survival rate')
ax4 = fig.add_subplot(1,3,3)
ax4 = sns.factorplot('Embarked','Survived',data=train_data)
plt.show()

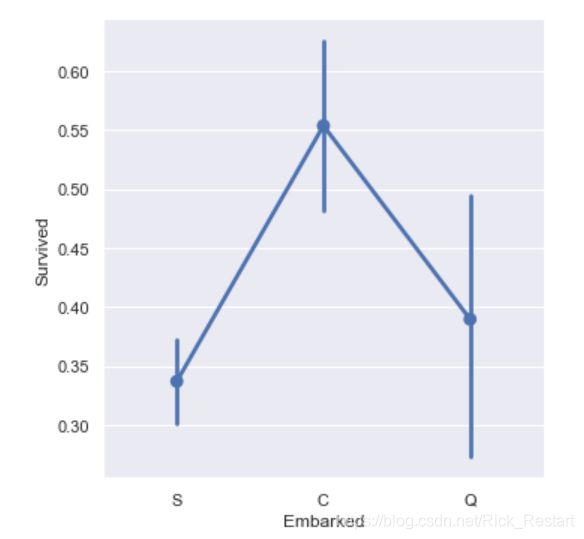
S港口的登船人数最多,幸存者人数也最多,但生存率最低。
fig,ax = plt.subplots(1,3,figsize=(18,8))
train_data[train_data.Embarked=='S'].groupby(['Sex'])['Embarked'].count().plot.pie(explode=[0,0.1],labels=['female, 203','male, 441'],
autopct='%1.1f%%',shadow=True,fontsize=12,ax=ax[0])
ax[0].set_title('Embarked=S',fontsize=13)
ax[0].set_ylabel('')
train_data[train_data.Embarked=='Q'].groupby(['Sex'])['Embarked'].count().plot.pie(explode=[0,0.1],labels=['female, 36','male, 41'],
autopct='%1.1f%%',shadow=True,fontsize=12,ax=ax[1])
ax[1].set_title('Embarked=Q',fontsize=13)
ax[1].set_ylabel('')
train_data[train_data.Embarked=='C'].groupby(['Sex'])['Embarked'].count().plot.pie(explode=[0,0.1],labels=['female, 73','male, 95'],
autopct='%1.1f%%',shadow=True,fontsize=12,ax=ax[2])
ax[2].set_title('Embarked=C',fontsize=13)
ax[2].set_ylabel('')
plt.show()
每个登船点的男女比例:

sns.factorplot('Pclass','Survived',hue='Sex',col='Embarked',data=train_data)
plt.show()
性别+社会地位对生存率的影响
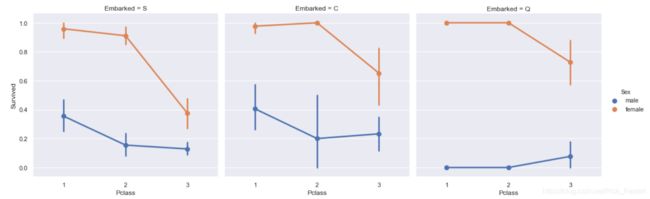
每个登船点人数男性比女性多,但是每个登船点无论是哪个阶层都是女性的生存率比男性高。S登船点阶层1的生存率>阶层2的生存率>阶层3的生存率,但C、Q登船点的男性生存率却不符合这一规则,这可能是C,Q登船点的阶层1阶层2的基数很小导致的。
pd.pivot_table(train_data,index=['Embarked','Pclass','Sex'],values=['Survived'],aggfunc=[len,sum],margins=True)

sns.countplot('Embarked',hue='Pclass',data=train_data)
plt.show()

从以上数据看出,C登船点的阶层2人数很少,Q登船点机会没有阶层1跟阶层2的,这就符合我们之前的判断了。
登船点缺失值填补
登船点缺失值有两个,先看看这两个缺失值对应的社会地位。
train_data[train_data.Embarked.isnull()]

两个缺失值都是阶层1的,阶层1人数最多的登船点是S港,这里的缺失值填补将直接使用“S”值填充。
train_data.Embarked[train_data.Embarked.isnull()]="S"
再检查一下缺失值:
In:train_data.Embarked.isnull().sum()
Out:0
缺失值填充完成
4.7兄弟姐妹数量(sibsip)和 父母和孩子数量(Parch)因素影响的情况
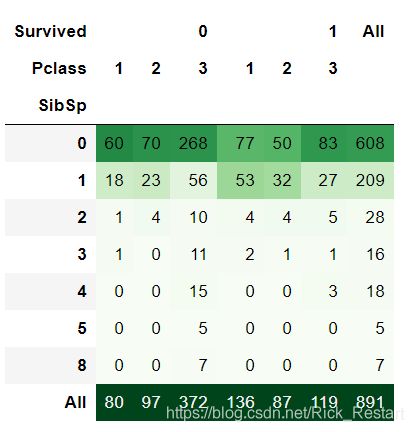
pd.crosstab(train_data.SibSp,[train_data.Survived,train_data.Pclass],margins=True).style.background_gradient(cmap='Greens')
pd.crosstab(train_data.Parch,[train_data.Survived,train_data.Pclass],margins=True).style.background_gradient(cmap='Greens')
先看基本情况

fig,ax = plt.subplots(1,2,figsize=(18,8))
sns.factorplot('SibSp','Survived',data=train_data,ax=ax[0])
sns.factorplot('Parch','Survived',data=train_data,ax=ax[1])
plt.close(1)
plt.show()


可以看到,SibSp人数在1-2个内生存率有所提高,Parch人数在1-3个生存率也也有提高。再结合社会地位看看生存率情况。
fig,ax = plt.subplots(1,2,figsize=(20,8))
sns.barplot('SibSp','Survived',hue='Pclass',data=train_data,ax=ax[0])
ax[0].set_title('SibSp&Pclass vs Survived')
sns.barplot('Parch','Survived',hue='Pclass',data=train_data,ax=ax[1])
ax[1].set_title('Parch&Pclass vs Survived')
plt.show()
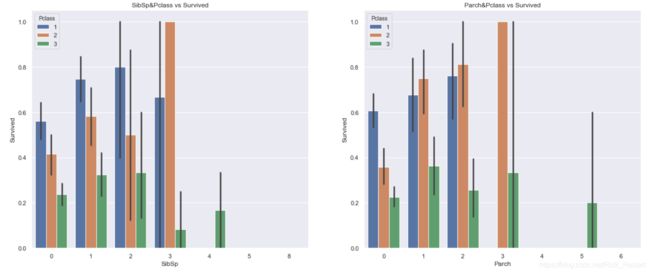
无论哪个阶层,SibSp数量在1-2个内比0个生存率高,阶层1和阶层3在SibSp生存率也比0个高,而阶层3就骤然下降。Parch数量在1-3个内比0个生存率高。从数据看出,SibSp和Parch数量大于3生存率都不高,并且数量大于3这种大家庭几乎都在阶层3。
4.8船票价格因素的影响
先看基本描述:
train_data.Fare.describe()

最大值为512.3292,最小值为0
社会地位对应的票价分布
f,ax=plt.subplots(1,3,figsize=(20,8))
sns.distplot(train_data[train_data['Pclass']==1].Fare,ax=ax[0])
ax[0].set_title('Fares in Pclass 1')
sns.distplot(train_data[train_data['Pclass']==2].Fare,ax=ax[1])
ax[1].set_title('Fares in Pclass 2')
sns.distplot(train_data[train_data['Pclass']==3].Fare,ax=ax[2])
ax[2].set_title('Fares in Pclass 3')
plt.show()

可以看到阶层1的票价普遍高于阶层2票价高于阶层3票价。再看看每个价格段对应的生存率,这里将票价分成12份,主要是这样分出来的人数比较均匀。
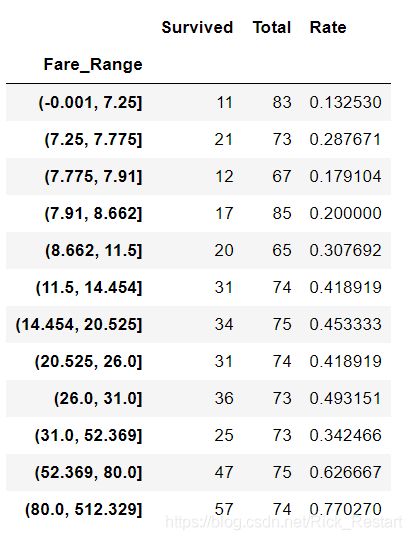
train_data['Fare_Range']=pd.qcut(train_data.Fare,12)
Fare_S = train_data.groupby('Fare_Range')['Survived'].sum() #每个分段存活人数
Fare_T = train_data.groupby('Fare_Range')['Survived'].count() #每个分段总人数
Fare_STR = pd.concat([Fare_S,Fare_T],axis=1)
Fare_STR.columns = ['Survived','Total']
Fare_STR['Rate']= (Fare_S/Fare_T)
Fare_STR
plt.figure(figsize=(18,5))
plt.scatter(range(12),Fare_STR.Rate,color="green")
plt.plot(range(12),Fare_STR.Rate)
plt.xticks(range(12),Fare_STR.index)
plt.show()

基本上票价高的比票价低有更高的生存率。
处理测试集:
由于测试集的Fare存在缺失值,
先查看缺失值信息:阶层3,男性
test_data[test_data.Fare.isnull()]
填补策略按阶层和性别的平均值填补。
test_data.groupby(['Pclass','Sex'])['Fare'].mean()

test_data.Fare[test_data.Fare.isnull()]=11.830688
填补完成后,按训练集的方法同样处理测试集
test_data['Fare_Range']=pd.qcut(test_data.Fare,12)
4.9船票号码因素的影响(最后的结果显示,加了这步得分更低,决定放弃)
由于船票号存在相同号码,于是我做了个统计,船票不相同(count=1)有547张,生存人数有163人,生存率为0.297989,详细见下图。
table=pd.pivot_table(train_data,index=['Ticket'],values=['Survived'],aggfunc=[len,sum],margins=True)
tf = pd.DataFrame(table)
tf.columns = ['count','Survived']
Ticket_count = pd.concat([tf.groupby('count')['Survived'].sum(),tf.groupby('count')['count'].sum()],axis=1)
Ticket_count['Rate']=tf.groupby('count')['Survived'].sum()/tf.groupby('count')['count'].sum()
Ticket_count

将票号出现的次数插入到train_data表里
train_data = pd.merge(train_data,table['count'],on="Ticket")
train_data.rename(columns={'count':'Ticket_count'},inplace=True) #改列名
train_data.head()
sns.factorplot('Ticket_count','Survived',data=train_data)
plt.show()

可以看Ticket_count数量在2-4张之间的生存率要比1张高,大于4张后生存率下降。
同样处理测试集
table_test=pd.pivot_table(test_data,index=['Ticket'],values=['PassengerId'],aggfunc=len,margins=True)
tf_test = pd.DataFrame(table_test)
tf_test.columns = ['count']
test_data = pd.merge(test_data,tf_test['count'],on="Ticket")
test_data.rename(columns={'count':'Ticket_count'},inplace=True)
test_data.groupby('Ticket_count')['Ticket_count'].count()

票号相同的数据也是不少的。
概况特征值影响状况:
- 性别因素对生存率的影响:女性>男性
- 社会地位因素对生存率的影响: 阶层1>阶层2>阶层3
- 年龄因素对生存率的影响:0-15岁有较高的生存率,大于60岁生存率较低,幸存者集中在15-35岁之间。
- 登船点因素对生存率的影响:S港口登船人数最多,也是阶层3登船人数最多的一个港口,生存率最低。该因素其实不是很重要。
- 兄弟姐妹数量与父母孩子数量对生存率的影响:SibSp人数在1-2个内生存率有所提高,Parch人数在1-3个生存率也也有提高。
- 船票价格因素对生存率的影响:高昂的船票价格生存率比低价的船票生存率普遍要高。
- 船票号码因素对生存率的影响:有2-4张船票号码相同的能提高生存率。(类似SibSp和Parch分析)
5.特征工程和数据清洗
5.1 年龄分段
先观察年龄分布
plt.figure(figsize=(18,8))
train_data.Age.plot.hist(bins=80)
plt.xlim(0,80)
plt.xticks(range(81))
plt.show()

将年龄分为5份:每份组距16。
train_data['Age_band']=0
train_data.loc[train_data['Age']<=16,'Age_band']=0
train_data.loc[(train_data['Age']>16)&(train_data['Age']<=32),'Age_band']=1
train_data.loc[(train_data['Age']>32)&(train_data['Age']<=48),'Age_band']=2
train_data.loc[(train_data['Age']>48)&(train_data['Age']<=64),'Age_band']=3
train_data.loc[train_data['Age']>64,'Age_band']=4
同样处理测试集
test_data['Age_band']=0
test_data.loc[test_data['Age']<=16,'Age_band']=0
test_data.loc[(test_data['Age']>16)&(test_data['Age']<=32),'Age_band']=1
test_data.loc[(test_data['Age']>32)&(test_data['Age']<=48),'Age_band']=2
test_data.loc[(test_data['Age']>48)&(test_data['Age']<=64),'Age_band']=3
test_data.loc[test_data['Age']>64,'Age_band']=4
5.2 家庭总人数
将SibSp和Parch合在一起,构成一个新的特征值
train_data['Family_Size']=0
train_data['Family_Size']=train_data['Parch']+train_data['SibSp'] #family size
train_data['Alone']=0
train_data.loc[train_data.Family_Size==0,'Alone']=1 #Alone
test_data['Family_Size']=0
test_data['Family_Size']=test_data['Parch']+test_data['SibSp'] #family size
test_data['Alone']=0
test_data.loc[test_data.Family_Size==0,'Alone']=1 #Alone
5.3 船票价格
处理训练集
train_data['Fare_cat']=0
train_data.loc[train_data['Fare']<=7.91,'Fare_cat']=0
train_data.loc[(train_data['Fare']>7.91)&(train_data['Fare']<=14.454),'Fare_cat']=1
train_data.loc[(train_data['Fare']>14.454)&(train_data['Fare']<=31),'Fare_cat']=2
train_data.loc[(train_data['Fare']>31)&(train_data['Fare']<=513),'Fare_cat']=3
处理测试集
test_data['Fare_cat']=0
test_data.loc[test_data['Fare']<=7.91,'Fare_cat']=0
test_data.loc[(test_data['Fare']>7.91)&(test_data['Fare']<=14.454),'Fare_cat']=1
test_data.loc[(test_data['Fare']>14.454)&(test_data['Fare']<=31),'Fare_cat']=2
test_data.loc[(test_data['Fare']>31)&(test_data['Fare']<=513),'Fare_cat']=3
5.4转换特征值
处理训练集
train_data['Sex'].replace(['male','female'],[0,1],inplace=True)
train_data['Embarked'].replace(['S','C','Q'],[0,1,2],inplace=True)
train_data['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Mr','Mr','Mr','Mr','Mr','Mr'],inplace=True)
train_data['Initial'].replace(['Mr','Mrs','Miss','Master'],[0,1,2,3],inplace=True)
处理测试集
test_data['Sex'].replace(['male','female'],[0,1],inplace=True)
test_data['Embarked'].replace(['S','C','Q'],[0,1,2],inplace=True)
test_data['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don','Dona'],['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Mr','Mr','Mr','Mr','Mr','Mr','Mrs'],inplace=True)
test_data['Initial'].replace(['Mr','Mrs','Miss','Master'],[0,1,2,3],inplace=True)
5.5 删除多余特征值
处理训练集
train_data.drop(['Name','Age','Ticket','Fare','Cabin','PassengerId','Ticket_count'],axis=1,inplace=True)
处理测试集
test_data.drop(['Name','Age','Ticket','Fare','Cabin','PassengerId','Ticket_count'],axis=1,inplace=True)
显示处理后的效果
train_data

sns.heatmap(train_data.corr(),annot=True,cmap='RdYlGn',linewidths=0.2) #data.corr()-->correlation matrix
fig=plt.gcf()
fig.set_size_inches(10,8)
plt.show()
6.机器学习建模
#importing all the required ML packages
from sklearn.linear_model import LogisticRegression #logistic regression
from sklearn import svm #support vector Machine
from sklearn.ensemble import RandomForestClassifier #Random Forest
from sklearn.neighbors import KNeighborsClassifier #KNN
from sklearn.naive_bayes import GaussianNB #Naive bayes
from sklearn.tree import DecisionTreeClassifier #Decision Tree
from sklearn.model_selection import train_test_split #training and testing data split
from sklearn import metrics #accuracy measure
from sklearn.metrics import confusion_matrix #for confusion matrix
from sklearn.model_selection import KFold #for K-fold cross validation
from sklearn.model_selection import cross_val_score #score evaluation
from sklearn.model_selection import cross_val_predict #prediction
kfold = KFold(n_splits=10, random_state=22) # k=10, split the data into 10 equal parts
xyz=[]
accuracy=[]
std=[]
classifiers=['Linear Svm','Radial Svm','Logistic Regression','KNN','Decision Tree','Naive Bayes','Random Forest']
models=[svm.SVC(kernel='linear'),svm.SVC(kernel='rbf'),LogisticRegression(),KNeighborsClassifier(n_neighbors=9),DecisionTreeClassifier(),GaussianNB(),RandomForestClassifier(n_estimators=100)]
for i in models:
model = i
cv_result = cross_val_score(model,X,Y, cv = kfold,scoring = "accuracy")
cv_result=cv_result
xyz.append(cv_result.mean())
std.append(cv_result.std())
accuracy.append(cv_result)
new_models_dataframe2=pd.DataFrame({'CV Mean':xyz,'Std':std},index=classifiers)
new_models_dataframe2

得分最高的是Radial Svm模型,着重对Svm模型进行调参。
from sklearn.model_selection import GridSearchCV
C=[0.05,0.1,0.2,0.3,0.25,0.4,0.5,0.6,0.7,0.8,0.9,1]
gamma=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]
kernel=['rbf','linear']
hyper={'kernel':kernel,'C':C,'gamma':gamma}
gd=GridSearchCV(estimator=svm.SVC(),param_grid=hyper,verbose=True)
gd.fit(X,Y)
print(gd.best_score_)
print(gd.best_estimator_)

训练模型,输出结果:
submission = pd.read_csv(r'titanic\gender_submission.csv')
model=svm.SVC(kernel='rbf',C=0.6,gamma=0.1,random_state=30)
model.fit(train_X,train_Y)
prediction1=model.predict(test_X)
print('Accuracy for rbf SVM is ',metrics.accuracy_score(prediction1,test_Y))
pred= model.predict(test_data)
submission['Survived']=preds
submission.to_csv('prediction.csv',index=None)
最后得分:0.78947 。(尝试了很多次调整数据,都无法突破0.8,等学完深度学习再看看)
![]()
方法参考“黑马python人工智能”