目标检测-用爬虫爬取百度图库获得自己想要的图片数据集-python代码
在百度图片中爬取自己想要的数据集
如果你复制了此代码,能不能给我点个赞!
1.问题描述
最近在做一个垃圾分类的项目,需要大量的数据集,自己拍又太麻烦,于是想到了利用百度图片来根据关键字查找生产自己要想的图片数据集
2.代码
两个代码功能一样的,2的话爬的速度更快,但是会导致部分图片无法正常打开
基本的注释我都有在代码中补充
2.1爬虫代码1
import requests
import os
def getManyPages(keyword, pages):
params = []
for i in range(30, 30 * pages + 30, 30):
params.append({
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': 0,
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': 1,
'fr': '',
'pn': i,
'rn': 30,
'gsm': '1e',
'1488942260214': ''
})
url = 'https://image.baidu.com/search/acjson'
urls = []
for i in params:
urls.append(requests.get(url, params=i).json().get('data'))
return urls
def getImg(dataList, localPath):
if not os.path.exists(localPath): # 新建文件夹
os.mkdir(localPath)
x = 0
for list in dataList:
for i in list:
if i.get('thumbURL') != None:
print('正在下载中:%s' % i.get('thumbURL'))
ir = requests.get(i.get('thumbURL'))
open(localPath + '%d.jpg' % x, 'wb').write(ir.content)
x += 1
else:
print('该图片链接不存在')
if __name__ == '__main__':
dataList = getManyPages('单个易拉罐', 2) # 参数1:关键字,参数2:要下载的页数
getImg(dataList, '/home/cheng/test/') # 参数2:指定保存的路径
需要修改的地方有
倒数第二行 指定要爬取的关键字。
dataList = getManyPages('单个易拉罐', 2) # 参数1:关键字,参数2:要下载的页数
倒数第一行 指定爬取图片的保存地址
运行结果如下

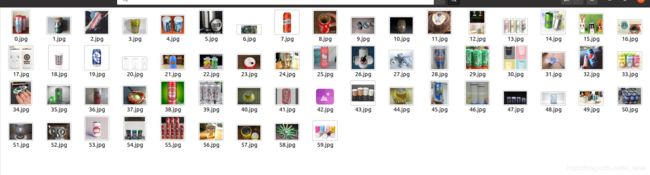
如下,这样我们就获得了相当多的图像,然后再人工筛选一下不合格的图片即可
2.2爬虫代码2
这个代码比较适合爬取海量数据,比如你可能需要上万张图片,启用了多线程,速度很快,但是有一个BUG就是会导致下载的部分图片打不开。也是需要人工筛选。
import requests
from threading import Thread
import re
import time
import hashlib
class BaiDu:
"""
爬取百度图片
"""
def __init__(self, name, page):
self.start_time = time.time()
self.name = name
self.page = page
#self.url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&rn=60&'
self.url = 'https://image.baidu.com/search/acjson'
self.header = {
}# 添加为自己的
self.num = 0
def queryset(self):
"""
将字符串转换为查询字符串形式
"""
pn = 0
for i in range(int(self.page)):
pn += 60 * i
name = {
'word': self.name, 'pn': pn, 'tn':'resultjson_com', 'ipn':'rj', 'rn':60}
url = self.url
self.getrequest(url, name)
def getrequest(self, url, data):
"""
发送请求
"""
print('[INFO]: 开始发送请求:' + url)
ret = requests.get(url, headers=self.header, params=data)
if str(ret.status_code) == '200':
print('[INFO]: request 200 ok :' + ret.url)
else:
print('[INFO]: request {}, {}'.format(ret.status_code, ret.url))
response = ret.content.decode()
img_links = re.findall(r'thumbURL.*?\.jpg', response)
links = []
# 提取url
for link in img_links:
links.append(link[11:])
self.thread(links)
def saveimage(self, link):
"""
保存图片
"""
print('[INFO]:正在保存图片:' + link)
m = hashlib.md5()
m.update(link.encode())
name = m.hexdigest()
ret = requests.get(link, headers = self.header)
image_content = ret.content
filename = '/home/image/' + name + '.jpg'
with open(filename, 'wb') as f:
f.write(image_content)
print('[INFO]:保存成功,图片名为:{}.jpg'.format(name))
def thread(self, links):
"""多线程"""
self.num +=1
for i, link in enumerate(links):
print('*'*50)
print(link)
print('*' * 50)
if link:
# time.sleep(0.5)
t = Thread(target=self.saveimage, args=(link,))
t.start()
# t.join()
self.num += 1
print('一共进行了{}次请求'.format(self.num))
def __del__(self):
end_time = time.time()
print('一共花费时间:{}(单位秒)'.format(end_time - self.start_time))
def main():
name = input('请输入你要爬取的图片类型: ')
page = input('请输入你要爬取图片的页数(60张一页):')
baidu = BaiDu(name, page)
baidu.queryset()
if __name__ == '__main__':
main()
如图,这个代码运行后需要你键入一些信息,或者你干脆直接在代码里写好。
参数
def saveimage(self, link)函数中,有一个filename = '/home/image/' + name + '.jpg'
在这里将 ‘/home/image’ 的地址 替换为你自己的地址,如上所示我的图片就是存储在/home/image文件夹下。
运行结果如下



爬取结果如下,你会发现图片的名字是乱码。
这里提供一个重命名工具
2.3重命名工具
# --** coding="UTF-8" **--
import os
import re
import sys
fileList = os.listdir(r"image/易拉罐")
print("start...")
# 得到进程当前工作目录
currentpath = os.getcwd()
# 将当前工作目录修改为待修改文件夹的位置
os.chdir(r"image/易拉罐")
# 名称变量
num = 1
# 遍历文件夹中所有文件
for fileName in fileList:
# 文件重新命名
os.rename(fileName, ('易拉管' + str(num) + '.jpg'))
# 改变编号,继续下一项
num = num + 1
print("end...")
# 改回程序运行前的工作目录
os.chdir(currentpath)
# 刷新
sys.stdin.flush()
fileList = os.listdir(r"image/易拉罐")与fileList = os.listdir(r"image/易拉罐")
分别替换
fileList = os.listdir(r"/home/image")与fileList = os.listdir(r"/home/image")
即可对我们爬取的图像重命名
os.rename(fileName, ('易拉管' + str(num) + '.jpg')) 为我们重命名格式
运行如下

重命名成功!
3.补充
根据关键字爬取的数据集存在大量脏数据, 我自己用的话可能100张里面只有20张符合我的要求。
于是后面我发现,利用百度识图爬取的图片,图像质量更高,更符合“我想要的图片”样式
这两天我会再发布一个百度识图版本的爬虫代码,使用和调试起来有点困难,会发布详细的配置使用教程!