Web端UI自动化测试框架设计结合PO设计思想
一、把每个页面作为一个类(以下称为:页面类),把页面中的功能点封装成函数
1.编写测试脚本其实很简单,无非是:定位到元素、对元素进行操作、把元素操作串联起来形成业务场景。
2.比如下图中的添加日报功能。我们需要先定位所有输入框->然后输入合法字符或选择列表中选项->最后点击暂存按钮。这样一个添加日报的业务场景就完成了。

3.如下图所示,在工作日报界面中,添加日报只是一个功能点,还有草稿列表中的查看、修改、删除和查询等功能点。那么我们可以把工作日报界面封装成一个类,把添加日报、查看、修改、删除和查询等功能点分别封装成函数。
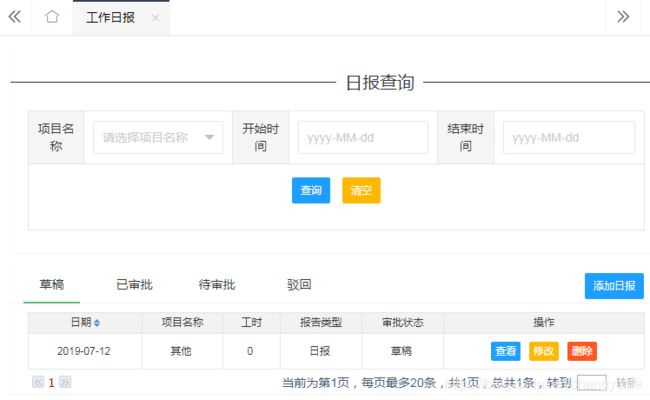
二、对页面类进行分层设计,分别是:元素管理层、操作管理层和业务管理层
1.元素管理层:管理页面元素。我用的是xml文档管理。activity标签中的name代表一个页面,比如:工作日报页面;element标签是每个元素的定位方式,下面的三个子元素分别是:元素描述、元素定位方式和值。同一个页面的所有元素均写到一个activity标签即可,多个页面就添加多个activity标签。
添加日报按钮
XPATH
//*[@id="ext-gen3"]/div[1]/div/div[2]/div/ul/div/a
填写日期
ID
date
2.操作管理层:该层叫基本类。封装了对元素进行操作的方法。比如:点击、输入、定位frame、处理浏览器弹窗、获取xml(即1中所述文档)中元素等方法。每个页面类都要继承基本类。基本类和页面类脚本如下:
'''
基本类
'''
from time import sleep
from common.get_log import *
from xml.etree import ElementTree
from selenium.common.exceptions import NoSuchElementException
import os
import time
import csv
class BaseView(object):
# 初始化driver
def __init__(self, driver):
# 读取日志
self.log = get_log()
self.driver = driver
# 从xml文件读取元素
def set_xml(self):
self.activity = {}
if len(self.activity) == 0:
# 获取配置文件
file_path = path.join(path.dirname(path.abspath(__file__)), '../config/OA.xml')
tree = ElementTree.parse(file_path)
# 从activity标签开始遍历
for ac in tree.findall("activity"):
ac_name = ac.get("name")
element = {}
# for el in ac.getchildren():
for el in list(ac):
element_id = el.get("id")
name = {}
for data in list(el):
name[data.tag] = data.text
element[element_id] = name
self.activity[ac_name] = element
# 把需要获取的元素信息放在字典里
def get_el_dict(self, activity_name, element_name):
self.set_xml()
activity_dict = self.activity.get(activity_name).get(element_name)
return activity_dict
# 获取具体的元素值,并赋值给两个全局变量,方便其他函数调用
def get_element(self, activity_name, element_name):
self.activity = activity_name
self.element = element_name
element_dict = self.get_el_dict(self.activity, self.element)
self.pathType = element_dict.get('pathType')
self.pathValue = element_dict.get("pathValue")
# 定位元素
def locate_element(self):
try:
if self.pathType == 'ID':
element = self.driver.find_element_by_id(self.pathValue)
return element
if self.pathType == 'XPATH':
element = self.driver.find_element_by_xpath(self.pathValue)
return element
if self.pathType == 'CLASSNAME':
element = self.driver.find_element_by_class_name(self.pathValue)
return element
if self.pathType == 'NAME':
element = self.driver.find_element_by_name(self.pathValue)
return element
if self.pathType == 'LinkText':
element = self.driver.find_element_by_link_text(self.pathValue)
return element
if self.pathType == "IFRAME":
self.driver.switch_to.frame(self.pathValue)
except NoSuchElementException:
return None
# 判断元素是否存在
def is_exist(self):
try:
if self.pathType == 'ID':
self.driver.find_element_by_id(self.pathValue)
return True
if self.pathType == 'XPATH':
self.driver.find_element_by_xpath(self.pathValue)
return True
if self.pathType == 'CLASSNAME':
self.driver.find_element_by_class_name(self.pathValue)
return True
if self.pathType == 'NAME':
self.driver.find_element_by_name(self.pathValue)
return True
if self.pathType == 'LinkText':
self.driver.find_element_by_link_text(self.pathValue)
return True
except NoSuchElementException:
return False
# 点击
def click(self):
element = self.locate_element()
sleep(2)
element.click()
# 输入
def send_key(self, key):
element = self.locate_element()
sleep(2)
# element.click()
element.clear()
element.send_keys(key)'''
页面类:工作日报
'''
from baseView.base_view import BaseView
from baseView.browser_view import Browser
from common.get_configInfo import get_config
from businessView.login import LoginView
from time import sleep
# 继承了BaseView类
class DailyReportPage(BaseView):
# 新增并暂存日报
def save(self, date, content, hours):
# 点击添加日报按钮,进入新增日报界面
self.log.info("点击添加日报按钮")
self.get_element("daily_report", "add")
self.click()
# 输入日报信息并暂存
# 输入时间,用js去掉readonly属性,待优化!!!
self.get_element("daily_report", "date")
Date = 'document.getElementById("date").removeAttribute("readonly");'
self.driver.execute_script(Date)
# 输入日报时间
self.log.info("输入日报时间")
self.send_key(date)
# 点击选择所属项目:由于控件的特殊性,需要先点击输入框,再点击选择项目名称
self.log.info("点击选择所属项目")
self.get_element("daily_report", "project")
self.click()
self.get_element("daily_report", "project_list")
self.click()
# 填写今日工作
self.log.info("填写今日工作")
self.get_element("daily_report", "content")
self.send_key(content)
# 输入工时
self.log.info("输入工时")
self.get_element("daily_report", "hours")
self.send_key(hours)
# 点击暂存按钮
self.log.info("点击暂存按钮")
self.get_element("daily_report", "save")
self.click()
sleep(2)
# 添加断言,检查新增日报是否成功
self.check_save()3.业务管理层:把元素操作串联成业务场景,即2中“页面类:工作日报”中的save函数。
三、浏览器驱动和测试代码的结合
1.基本类里有一个driver参数,这个参数的值从哪来呢?我专门封装了浏览器的打开和关闭操作作为一个类,其中打开浏览器函数有个返回值,基本类的driver参数就是这个返回值。这个driver实际上是某个浏览器的驱动类对象,比如谷歌浏览器:driver = webdriver.Chrome(),代码如下:
from common.get_configInfo import get_config
from selenium import webdriver
from common.get_log import *
from time import sleep
class Browser(object):
def __init__(self):
self.log = get_log()
# 打开浏览器
def open_browser(self):
browser = get_config("browserType", "browserName")
self.log.info("You had select %s browser." % browser)
if browser == "Firefox":
self.driver = webdriver.Firefox()
self.log.info("Starting firefox browser.")
elif browser == "Chrome":
self.driver = webdriver.Chrome()
self.log.info("Starting Chrome browser.")
elif browser == "IE":
self.driver = webdriver.Ie()
self.log.info("Starting IE browser.")
url = get_config("testServer", "URL")
# self.log.info("The test server url is: %s" % url)
self.driver.get(url)
self.log.info("Open url: %s" % url)
# self.driver.maximize_window()
# self.log.info("Maximize the current window.")
# 设置窗口固定大小
self.driver.set_window_size(1300, 1000)
return self.driver
# 打开url
def open_url(self, url):
self.driver.get(url)
sleep(2)
# 关闭浏览器
def close_browser(self):
# quit关闭浏览器后,会自动删除临时文件夹,不要用close
self.driver.quit()
self.log.info("Close the browser.")2.在配置文件中可配置你要测试的浏览器和url信息,我用的是ini文件,如下:
[browserType]
browserName = Chrome
# browserName = Firefox
# IE驱动要下载32位的,64位的运行很缓慢
# browserName = IE
# 要测试的网址
[testServer]
URL = XXX3.基本类接收了driver后,页面类再继承基本类,就可以对浏览器执行各种操作。
四、测试用例继承unittest.Testcase类,且依赖页面类
1.写完工作日报的新增日报方法后,就可以作为一个测试用例运行了。此时要引入工作日报页面类,调用新增日报的方法作为一个测试用例,代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
caseName:工作日报
'''
import unittest
from businessView.daily_report import DailyReportPage
from baseView.browser_view import Browser
from common.get_configInfo import get_config
from businessView.login import LoginView
import ddt
from common.get_log import get_log
log = get_log()
save_data = (("2019-07-03", "测试数据01", "0"), )
update_data = (("2019-07-01", "测试数据-修改", "0"), )
@ddt.ddt
class DailyReport(unittest.TestCase):
'''
1、setUp():每个测试方法运行前运行,测试前的初始化工作。
2、setUpClass():所有的测试方法运行前运行,为单元测试做前期准备,
但必须使用@classmethod装饰器进行修饰,整个测试过程中只执行一次
'''
@classmethod
def setUpClass(cls):
# 打开浏览器和url
browser = Browser()
cls.driver = browser.open_browser()
# 登录(以下用例的前置条件一致,均需要登录,所以放到该方法中)
username = get_config("accountInfo", "username")
password = get_config("accountInfo", "password")
lv = LoginView(cls.driver)
lv.login_action(username, password)
lv.into_report_page()
# 初始化工作日报界面类
cls.drp = DailyReportPage(cls.driver)
@classmethod
def tearDownClass(cls):
log.info("Close the browser.")
# quit关闭浏览器后,会自动删除临时文件夹,不要用close
cls.driver.quit()
# 暂存日报用例
@ddt.data(*save_data)
@ddt.unpack
def test_save(self, date, content, hours):
log.info("******** 01-用例名称:暂存日报 ********")
self.drp.save(date, content, hours)
if __name__ == "__main__":
# unittest执行测试用例,默认是根据ASCII码的顺序加载测试用例
unittest.main()
2.其中测试数据我用的ddt来管理
3.登录操作专门封装了一个类,原理与工作日报类一样
五、讲解一下UI自动化框架搭建过程:
1.首先是针对web端页面,每个页面作为一个类,每个页面的中的单个功能点作为一个函数
2.每个页面元素定位方式和值用一个xml文档存储
3.页面元素操作方法放在一个基本类里,每个页面类都要继承该基本类。页面操作方法包括:解析xml文档获取元素定位
、点击、输入、切换iframe,截图等
4.测试某页面功能时,需要启动浏览器和打开测试地址,并进行登录。
其中浏览器类型和测试地址均放在一个ini配置文件中,登录操作也封装成一个类,与页面类一样,继承基本类。
5.浏览器的打开、关闭、设置窗口大小等操作专门封装成一个类
6.运行某页面类的函数时,要引入浏览器操作类,登录类,实例化该页面类,然后运行函数
7.创建测试用例类,继承unittest.Testcase,并引入页面类,在该类中创建测试用例
8.测试用例中用到的测试数据用ddt管理,每组数据代表一个测试用例
9.用unittest中的discover方法加载要测试的测试用例
10.结合测试报告,生成测试报告文档