重构设计模式_重构设计
在“ 测试驱动的设计,第1部分 ”和“ 测试驱动的设计,第2部分 ”中,我介绍了测试如何为新项目带来更好的设计。 在“ 组合方法和SLAP ”中,我谈到了两种关键模式-组合方法和单一级别的抽象原理-为您的代码结构提供了一个总体目标。 记住这些模式。 拥有现有软件项目后,发现和收获设计元素的途径就在于重构。 在他的经典著作《 重构》中 ,马丁·福勒(Martin Fowler)将重构定义为“一种用于重组现有代码主体,改变其内部结构而不改变其外部行为的有纪律的技术”(请参阅参考资料 )。 重构是具有目标的结构转换。 任何项目的一个值得称赞的目标是易于重构的代码库。 在本文中,我将讨论如何使用重构来发现隐藏在代码中的未充分利用的设计潜伏。
单元测试代表主要的安全网,可让您随意重构代码库。 如果您的项目具有100%的代码覆盖率,则可以不受惩罚地重构代码。 如果您尚未进行该级别的测试,那么积极的重构将更加危险。 本地化更改很容易应用,您可以看到它们的立竿见影的效果,但是遥不可及的副作用破坏了您的视线。 软件会导致意外的耦合点,并且对代码的一部分进行很小的更改会在代码库中引起波动,从而导致错误发生,并且远离更改的几百行代码。 更改代码并找到那些错误的信心是普遍的单元测试的标志。 在一个为期2年的ThoughtWorks项目中,技术负责人在项目上线前一天对代码进行了53次不同的重构。 他这样做充满了自信,因为该项目具有全面的代码覆盖范围。
如何在可能进行大型重构的地方获得代码库? 一种选择是拒绝编写更多代码,直到您花时间将测试添加到整个项目中。 一旦提出这一建议,您将被解雇,并且可以去一家重视单元测试的公司工作。 这种方法可能不是最佳的。 下一个最好的选择是让团队中的其他人意识到测试的价值,并开始缓慢地在代码中最关键的部分周围添加测试。 在沙子上画一条线,并在不久的将来声明一个日期:“从下星期四开始,我们的代码覆盖率将永远提高。” 每次编写新代码时,都添加一个测试,并且每次修复错误时,都编写一个测试。 通过围绕最敏感的部分(新功能和故障区域)逐渐添加测试,可以在最有效的部分添加测试。
单元测试验证原子行为。 但是,如果您的代码库不遵循理想的组合方法怎么办? 换句话说,如果您的所有方法都有数十行或数百行代码,并且每个方法执行大量任务,该怎么办? 您可以使用单元测试框架围绕这些方法编写粗粒度的功能测试,主要涉及方法输入和输出状态的转换。 这些不如单元测试好,因为它们不能验证每个小小的行为,但是总比没有好。 对于代码中非常关键的部分,您可以在开始重构之前考虑添加一些功能测试作为安全网。
重构的机制很简单,现在所有主要的IDE都提供了出色的重构支持。 困难在于找到与重构的内容 。 这就是本文其余部分的内容。
耦合到基础设施
Java世界中的每个人都使用框架来启动开发并提供最佳类型的关键基础结构(您无需编写基础结构)。 但是商业和开放源代码框架中都隐含着一种危险:它们总是试图使您与它们过于亲密地耦合在一起,这会使查看隐藏在代码中的设计变得更加困难。
框架和应用程序服务器具有帮助程序类,它们可以使您走上一条更简单的开发道路:如果仅导入和使用它们的某些类,则完成特定任务会容易得多。 一个典型的例子是Struts,这是一种非常受欢迎的开源Web框架。 Struts包括一组帮助程序类,可以为您处理常见的杂务。 例如,如果允许您的域类扩展Struts ActionForm类,则Struts会自动从请求中填充表单字段,处理验证和生命周期事件,并执行其他方便的行为。 换句话说,Struts提供了一个折衷方案:使用我们的课程,您的开发工作将变得更加容易。 它鼓励您创建一种如图1所示的结构:
图1.使用Struts ActionForm类
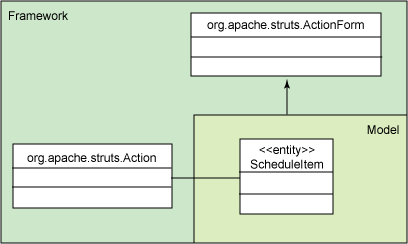
黄色框包含您的域类,但是Struts框架鼓励您从ActionForm扩展其有用的行为。 但是,您现在已经无可救药地将代码耦合到Struts框架。 您只能在Struts应用程序中使用域类。 这也损害了域类的设计,因为该实用程序类现在必须位于对象层次结构的顶部,不允许您使用继承来巩固常见行为。
图2显示了一种更好的方法:
图2.改进的设计,使用合成与Struts分离
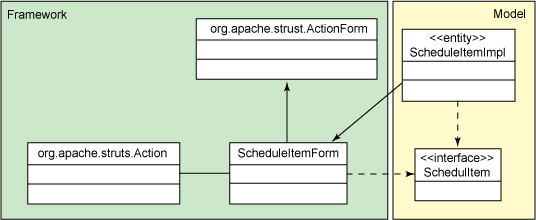
在此版本中,您的域类不依赖于Struts ActionForm 。 而是,一个接口为您的域类和ScheduleItemForm类定义了语义,这充当了您的域和框架之间的桥梁。 ScheduleItemImpl和ScheduleItemForm实现该接口,并且ScheduleItemForm类通过组合(而不是继承)保存对您的域类的引用。 Struts帮助程序可以保留对类的依赖关系,但是反之则不成立:您不应让您的类对框架具有依赖关系。 现在,您可以在其他类型的应用程序(Swing应用程序,服务层等)中自由使用ScheduleItem 。
在许多应用程序中,与基础架构的耦合非常容易,通用且普遍。 当您导入框架时,框架使利用它们的服务变得更加容易。 你应该抵抗诱惑。 如果框架的表面贴图覆盖了所有内容,则很难在代码中发现惯用模式(在先前的文章中定义为应用程序中出现的小模式)。
违反DRY
在The Pragmatic Programmer一书中,Andy Hunt和Dave Thomas定义了DRY原则:不要重复自己(请参阅参考资料 )。 代码中违反DRY的两个方面-复制粘贴代码和结构重复-会影响设计。
复制和粘贴代码
代码中的重复内容会使设计模糊不清,因为您找不到惯用的模式。 复制和粘贴代码在一个地方到另一个地方有细微的差别,使您无法确定某个方法或方法集合的实际用法。 而且,当然,每个人都知道,复制和粘贴编码始终会最终伤害您,因为您不可避免地必须更改行为,并且很难跟踪所有复制和粘贴代码的位置。
您如何找到已渗入代码库的重复项? IDE包括重复检测器(如IntelliJ一样)或将它们作为插件提供(如Eclipse一样)。 也存在独立工具,包括开源(例如CPD,复制/粘贴检测器)和商业工具(例如Simian)(请参阅参考资料 )。
CPD项目是PMD来源分析工具的一部分。 它是一个基于Swing的应用程序,可以分析单个文件内以及多个文件中可配置数量的令牌。 我需要一个不平凡的受害者代码库作为示例,因此我选择了上述的Struts项目。 在Struts 2代码库上运行CPD产生的结果如图3所示:
图3.基于Struts 2代码库的CPD结果
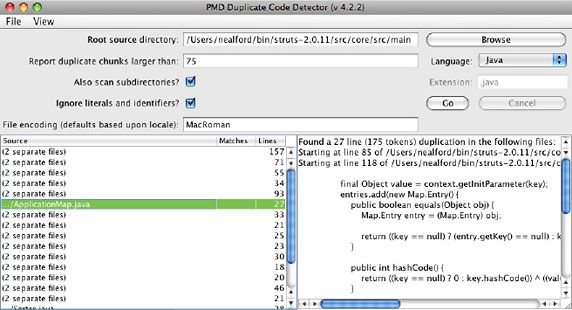
CPD在Struts代码库中发现了许多重复项。 他们中的许多人都围绕向Struts添加portlet支持。 实际上,大多数跨文件复制都存在于Portlet XXX和XXX之间(例如PortletApplicationMap和ApplicationMap )。 这表明Portlet支持的设计不当。 每当您具有大量重复的代码以向现有框架添加其他行为时,这就是主要的代码味道。 继承或组合都提供了一种更清洁的方式来扩展框架,如果两者都不可行,则是更大的要求。
此代码库中的另一个常见复制问题位于ApplicationMap.java和Sorter.java文件中。 ApplicationMap.java包含27行重复代码块,如清单1所示:
清单1. ApplicationMap.java中的重复代码
entries.add(new Map.Entry() {
public boolean equals(Object obj) {
Map.Entry entry = (Map.Entry) obj;
return ((key == null) ?
(entry.getKey() == null) :
key.equals(entry.getKey())) && ((value == null) ?
(entry.getValue() == null) :
value.equals(entry.getValue()));
}
public int hashCode() {
return ((key == null) ?
0 :
key.hashCode()) ^ ((value == null) ?
0 :
value.hashCode());
}
public Object getKey() {
return key;
}
public Object getValue() {
return value;
}
public Object setValue(Object obj) {
context.setAttribute(key.toString(), obj);
return value;
}
});除了多次使用嵌套三元运算符(总是一个很好的指示作业安全性的指标,因为其他人都无法读取该代码)之外,此重复代码的有趣部分不是代码本身。 这是在重复发生的两种方法中此代码之前出现的序言。 第一个如清单2所示:
清单2.首次出现代码的序言
while (enumeration.hasMoreElements()) {
final String key = enumeration.nextElement().toString();
final Object value = context.getAttribute(key);
entries.add(new Map.Entry() {
// remaining code elided, shown in Listing 1清单3显示了第二次重复的序言:
清单3.复制代码的第二个序言
while (enumeration.hasMoreElements()) {
final String key = enumeration.nextElement().toString();
final Object value = context.getInitParameter(key);
entries.add(new Map.Entry() {
// remaining code elided, shown in Listing 1 在整个唯一的区别while循环是调用context.getAttribute(key)在清单2与context.getInitParameter(key)在清单3 。 显然,可以对其进行参数化,从而允许将重复的代码折叠成自己的方法。 Struts的这个示例很好地说明了免费复制和粘贴代码,该代码不仅不必要,而且易于修复。
实际上,这说明Struts代码库中惯用的模式是收集条目并将其添加到属性集的方式。 允许几乎相同的代码驻留在多个位置中,这掩盖了一个事实,那就是Struts一直需要做这件事,从而阻止了将代码汇总到更具表现力的位置。 清理Struts代码库中多个类的设计的一种方法是认识到存在这种惯用模式并巩固该行为。
结构重复
重复的另一种形式更难发现,因此更加隐蔽: 结构重复 。 使用有限数量的语言(尤其是具有贫乏的元编程支持的语言,例如Java和C#)进行开发的开发人员很难看到此问题。 我的同事Pat Farley使用一个短语来最好地概括结构化重复: 相同的空格,不同的值 。 换句话说,您复制的代码实际上是相同的(即,空格是相同的),但是变量的值不同。 这种重复不会出现在CPD之类的工具中,因为重复基础结构的每个实例中的值确实是唯一的,但这仍然会损害您的代码。
这是一个例子。 假设我有一个带有几个字段的简单雇员类,如清单4所示:
清单4.一个简单的雇员类
public class Employee {
private String name;
private int salary;
private int hireYear;
public Employee(String name, int salary, int hireYear) {
this.name = name;
this.salary = salary;
this.hireYear = hireYear;
}
public String getName() { return name; }
public int getSalary() { return salary;}
public int getHireYear() { return hireYear; }
} 给定这个简单的类,我希望能够对类的任何字段进行排序。 Java语言具有通过创建实现Comparator接口的Comparator器类来区分排序顺序的机制。 清单5中显示了name和salary比较器:
清单5. name和salary比较器
public class EmployeeNameComparator implements Comparator {
public int compare(Employee emp1, Employee emp2) {
return emp1.getName().compareTo(emp2.getName());
}
}
public class EmployeeSalaryComparator implements Comparator {
public int compare(Employee emp1, Employee emp2) {
return emp1.getSalary() - emp2.getSalary();
}
} 对于Java开发人员来说,这看起来很自然。 但是,请考虑图4中的代码视图,其中我将两个比较器叠加在一起:
图4.叠加比较器

如您所见, 相同的空格,不同的值表达式非常适用。 大多数代码是重复的; 唯一的唯一部分是返回值。 因为我以一种“自然的”方式(即语言设计者所打算的方式)使用比较基础结构,所以很难自然地看到重复,但是很明显。 也许只有三个属性并没有那么糟糕,但是如果它增加了很多属性会怎样呢? 您在什么时候决定对这种重复进行攻击,以及如何进行?
我将使用反射创建一个通用的排序基础结构,该基础结构没有太多重复的样板代码。 为此,我创建了一个类来自动处理每个字段的比较器的排序和生成。 清单6显示了EmployeeSorter类:
清单6. EmployeeSorter类
public class EmployeeSorter {
public void sort(List employees, String criteria) {
Collections.sort(employees, getComparatorFor(criteria));
}
private Method getSelectionCriteriaMethod(String methodName) {
Method m;
methodName = "get" + methodName.substring(0, 1).toUpperCase() +
methodName.substring(1);
try {
m = DryEmployee.class.getMethod(methodName);
} catch (NoSuchMethodException e) {
throw new RuntimeException(e.getMessage());
}
return m;
}
public Comparator getComparatorFor(final String field) {
return new Comparator() {
public int compare(DryEmployee o1, DryEmployee o2) {
Object field1, field2;
Method method = getSelectionCriteriaMethod(field);
try {
field1 = method.invoke(o1);
field2 = method.invoke(o2);
} catch (Exception e) {
throw new RuntimeException(e);
}
return ((Comparable) field1).compareTo(field2);
}
};
}
} sort()方法使用Collecions.sort()方法,传递雇员列表和生成的比较器,并调用此类的第三个方法。 getComparatorFor()方法用作根据传入的标准动态生成匿名比较器类的工厂。 它通过getSelectionCriteriaMethod()使用反射从雇员类中检索正确的get方法,在正在比较的两个实例中的每个实例上调用该方法,然后返回结果。 清单7中的单元测试在几个字段中展示了此类的实际应用:
清单7.通用比较器的测试
public class TestEmployeeSorter {
private EmployeeSorter _sorter;
private ArrayList _list;
@Before public void setup() {
_sorter = new EmployeeSorter();
_list = new ArrayList();
_list.add(new DryEmployee("Homer", 20000, 1975));
_list.add(new DryEmployee("Smithers", 150000, 1980));
_list.add(new DryEmployee("Lenny", 100000, 1982));
}
@Test public void name_comparisons() {
_sorter.sort(_list, "name");
assertThat(_list.get(0).getName(), is("Homer"));
assertThat(_list.get(1).getName(), is("Lenny"));
assertThat(_list.get(2).getName(), is("Smithers"));
}
@Test public void salary_comparisons() {
_sorter.sort(_list, "salary");
assertThat(_list.get(0).getSalary(), is(20000));
assertThat(_list.get(1).getSalary(), is(100000));
assertThat(_list.get(2).getSalary(), is(150000));
}
} 像这样使用反射代表了一个权衡:复杂性与简洁性。 最初,基于反射的版本较难理解,但是它提供了许多好处。 首先,它会自动处理Employee类的任何属性,包括当前和将来。 使用此代码,您可以安全地向Employee添加新属性,而不必担心创建比较器来对它们进行排序。 其次,这可以更有效地处理大量属性。 如果结构重复性不是很出色,那么它很容易容忍。 但是您必须问自己:使用反射解决此问题的合理属性阈值数量是多少? 是10、20或50个属性? 此数字在开发人员和团队之间会有所不同。 但是,如果您正在寻找一个或多或少的客观衡量指标,为什么不衡量反射版本与各个比较器之间的复杂程度呢?
在“ 测试驱动的设计,第2部分 ”中,我介绍了圈复杂度度量标准,它是一种单一方法相对复杂度的简单度量。 一个很好的开源工具,措施,为Java语言圈复杂度是开源JavaNCSS工具(请参阅相关的主题 )。 如果我在单个比较器类之一上运行JavaNCSS,则返回1,这并不奇怪:该类中的单个方法只有一行,没有任何块。 当我在整个EmployeeSorter类上运行JavaNCSS时,所有方法的循环复杂度之和为8。这表明,要移至反射的属性数量的合理阈值为9;对于阈值而言,这是一个合理的阈值。 那就是结构的复杂性超过基于反射的版本的复杂性的时候。 如果反射使您感到不安,则可以为恶心因素再加一些积分!
无论如何,每种解决方案都有其成本和收益,这取决于您是否需要权衡。 我习惯于用Java语言和其他语言进行反思,所以我倾向于更积极地朝该解决方案发展,因为我不喜欢软件中的各种重复。
摘要
在本期中,我开始了有关使用重构作为工具来帮助理解和识别紧急设计的讨论。 我介绍了与基础架构的耦合以及它对您的设计造成的损害。 文章的大部分内容都以几种不同的形式介绍了重复项。 重构设计是一个广阔的领域。 在下一部分中,通过讨论度量标准如何帮助您找到最需要重构的代码部分,从而最有可能包含惯用模式等待发现,来继续本次对话。
翻译自: https://www.ibm.com/developerworks/java/library/j-eaed5/index.html