https://opentalk.upyun.com/334.html
2017 年 10 月 29 日,又拍云 Open Talk 联合 Spring Cloud 中国社区成功举办了“进击的微服务实战派北京站”。华为技术专家吴晟作了题为《使用 Skywalking 实现全链路监控》的分享,以下是分享实录:
一、分布式追踪
(一)三种场景
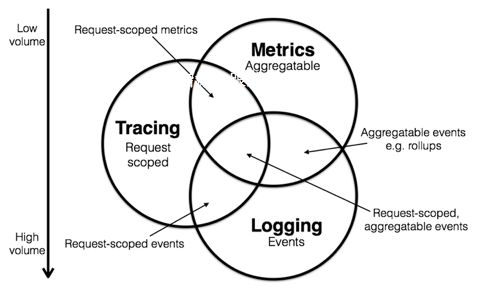
1、Metrics 指标性统计
比如说我们会去做一个服务的 TBS 的正确率、成功率、流量等,这是我们常见的针对单个指标或者某一个数据库的,这就是 Metrics 单指标分析。
2、Tracing 分布式追踪
这里提到的是一次请求的范围,也就是我们从浏览器或者手机端发起任何的一次调用,甚至我们可以再推广一点,是一次业务教育,比如说一次订购的过程,从浏览商品到最后下定单、支付、物流、最后交到我们的手上。这是一个流程化的东西,我们需要轨迹,需要去追踪。
3、 Logging 日志记录
我们程序在执行的过程中间发生了一些日志,会一帧一帧地跳出来给大家去记录这个东西,这是日志记录。
如果你做一个监控的产品, 你需要明确自己的定位,每个领域实际上要关心的事情是不一样的,而且这些领域之间会有交叉点。比如 Metrics 和 Logging 可能是之于某个指标的统计,但你通过日志的方式去做了一个搜集,最后统计了这些 Metrics 的信息,以及这些 Metrics 信息和对应的 Logging 的关系,那么你走的可能是 Metrics 和 Logging 之间的范围。如果你要去做 Metrics 和 Logging 中间的这些点,你需要清楚你是不是要付出这么大的代价。因为你每去占到这个圆中的一个部分,你的系统复杂度、内存的开销、后端的存储都需要付出相应的代价。随着指标数、内容的加入,你所要投入的研发技术难度也在逐步
上升。
所以大家在选择使用某一个分布式监控系统的时候,一定要明确你使用它的目的是什么,精确地了解它们的定位!
(二)什么是分布式追踪

上图是常见的微服务的框架,4 个实例,2 个 MySQL、1 个 Redis。实际上它有两次完全不同的请求进来:有一次的一个请求会访问 Redis,再去访问 MySQL;另外一个可能走到另外的服务上,然后直接去 MySQL。整个分布式追踪的目的是什么?是为了让我们最终在页面上、UI上、和数据上能够复现这个过程。我们要拿到整个完整的链路,包括精确的响应时间,访问的方法、访问的 circle,访问的 Redis 的 key等,这些是我们在做分布式追踪的时候需要展现的一个完整的信息。
(三)什么是 OpenTracing
开发和工程团队因为系统组件水平扩展、开发团队小型化、敏捷开发、CD(持续集成)、解耦等各种需求,正在使用现代的微服务架构替换老旧的单片机系统。 也就是说,当一个生产系统面对真正的高并发,或者解耦成大量微服务时,以前很容易实现的重点任务变得困难了。过程中需要面临一系列问题:用户体验优化、后台真是错误原因分析,分布式系统内各组件的调用情况等。 当代分布式跟踪系统(例如,Zipkin, Dapper, HTrace, X-Trace等)旨在解决这些问题,但是他们使用不兼容的API来实现各自的应用需求。尽管这些分布式追踪系统有着相似的API语法,但各种语言的开发人员依然很难将他们各自的系统(使用不同的语言和技术)和特定的分布式追踪系统进行整合,OpenTracing 通过提供平台无关、厂商无关的 API,使得开发人员能够方便的添加(或更换)追踪系统的实现。 OpenTracing 提供了用于运营支撑系统的和针对特定平台的辅助程序库。
OpenTracing 是一个规范,它不是一个数据结构,能提供的是语音和概念。OpenTracing 要涵盖的是中间的一层,它是要实现的是一套 API 的套件。你需要按照 OpenTracing 的规范向用户提供 API,实现把数据下送到 API 的探针或者 Tracer 的探针。OpenTracing 的主旨是在做手动埋点,程序的开发者要主动调用 Tracing 的 API 。我们这里主要是在讲 java ,而不是在讲例如 go、c++、c 等不太好写自动探针的语言。
二、Skywalking
SkyWalking 是针对分布式系统的 APM 系统,也被称为分布式追踪系统
- 全自动探针监控,不需要修改应用程序代码。查看支持的中间件和组件库列表:https://github.com/apache/incubator-skywalking
- 支持手动探针监控, 提供了支持 OpenTracing 标准的SDK。覆盖范围扩大到 OpenTracing-Java 支持的组件。查看OpenTracing组件支持列表:https://github.com/opentracing-contrib/meta
- 自动监控和手动监控可以同时使用,使用手动监控弥补自动监控不支持的组件,甚至私有化组件。
- 纯 Java 后端分析程序,提供 RESTful 服务,可为其他语言探针提供分析能力。
- 高性能纯流式分析。
Skywalking 是去搜集数据,给出分析的结果,然后你可以去做自动化运维或者 DveOps 。我们搜集的是 JVM 数据,然后去做自动的、应用的 Top 发现,以及服务的依赖。所以当你去做服务的时候,实际上服务会变成一颗服树。而不是简单的单个服务点,后面还会搜集服务访问的指标以及成功率、服务的数量等,下一阶段会提供 Alerting 报警。
Skywalking 的系统指标,做了一个压测,在 5000 tps 的应用上,我们消耗 10% 左右的 CPU。内存没有写,因为内存取决于采集到的数据,比如 URL 的长短,circle 的长短等等。
我们会去做支持日志记录集成,提供一个集成的方式,你可以把调用链的 ID 和日志做绑定,当你有 ELK 类型系统的时候,就可以让它和 skywalking 一起工作。然后你的日志里会有 skywalking 调用链的 ID ,这个调用链的信息和这些日志是精确绑定的。如此,你可以更好的使用日志系统,而不用把日志系统做大规模的复杂的查询,因为每一次的日志都是可以精确地匹配到一次精确地访问上的。
Skywalking 支持多种实现,目前提供是 H2 和 Elastic Search ,Elastic Search 主要用于生产 H2 。目前已经支持了大概 30 个以上的 libraries 的库,常见的基本都有。
(一)Skywalking 生态圈
目前有很多公司和个人在参加我们的项目,3 位 PMC 成员,2 位 Committer Team 成员,还有 15 个其他公司的贡献者,包括华为、阿里、当当、云智慧、OneAPM 等。所以我们能够提供很多大家看起来像是好像曾经你只能在商业产品或者国外看到的一些能力,因为我们很多人曾经或者现在都在专业的 APM 公司做过架构或者核心的研发工程师。
(二)Skywalking 3.2.3

sykwalking 3.2.3 架构图
上图是 skywalking 3.2.3 的整体架构图。
首先针对 Adaptor layer ,我们会与大家合作去做更多的扩展,包括我们的探针,SW3 Cross Process Propagation Protocol ,这实际上是我们的规范, 这个规范也会和全球的其他 APM公司合作,去形成刚才谈到的 TraceContext 的标准。我们会一起去努力把这个标准让所有的Tracer 之间,能够在一定程度上共享信息。也就是说当 A 应用调 B 应用的时候,即使 A、B 应用不属于同一个系统的监控,但是它们都有分布式链路的追踪能力,他们这个链路是有办法让大家串起来的。
我们之前和当当有做过一个尝试,当当内部暂时没有提供 php 和 golang 的探针,但他们可以在内部去通过简单的日志系统或者手工埋探针的方式,来实现我们的规范,我们可以复用我们的 Collector 来实现跨语言的探针,这个是一个开放的力量,我们不需要去做所有的事情,你只需要补充一点周围的事情,就可以满足需求。
机械计算和告警会是下一个阶段的重点,这块我们会和京东金融的团队有深度的合作,他们会和我们一起构建 base line 计算模块,让告警脱离手工设置,通过系统运行过程中做一个自动的计算,最后实际上不要超过平时太多,那么这个在线的系统就没有问题。
(三)Skywalking 追踪核心概念

这里反映了 skywalking 追踪的核心概念以及我们做的事情,就是 skywalking 怎么采集调用链。实际上这个基本是 skywalking 内核的翻译,里面可能会有一些可能在 OpenTracing 见到的概念,但也有一些我们自己的概念。
首先是第一级概念 TraceSegment ,一次访问会跳过 3 个 JOM ,每个 JOM 里面会生成 4 个 Segment 。我们在一次调用里面,所经历的一个线程,会生成一个 TraceSegment 。这里它经历了 4 个线程,不管是否跨 JOM ,A 里面 1 个,B 里面 1 个,B 里面的 New Thread 1 个,C 里面 1 个,所以它经历了四个线程后就会生成四 TraceSegment 对象。
对于入口,不管外围调用是否前置,都会创建一个 entry span,然后走 Extract ,提取前置上下文,当然第一个点没有前置,所以什么都没拿到。然后会创建一个 exit span ,创建一个最出的埋点。之后会做一个 inject的操作,把当前的上下文放在 HTTP 的头里面,顺带这个 HTTP的调用发到 Service B 上。
这个时候在运行的线程里面它一定会 hang 住,因为它需要等对方 HTTP 的返回,所以就会出现在 Service B 上,会同样地创建 TraceSegment ,创建 entry ,然后 Extract 提取 ContextCarrier ,这时它与 1 肯定是不一样的,因为前面做了 inject ,注入了上下文,因此这边一定能够拿到上下文,那么它就会做一个 Segment2 和 Segment1 的绑定关系。然后它又会它需要等对方 HTTP 的返回,所以就会出现在 Service B 上,会同样地创建 TraceSegment ,创建 entry ,然后 Extract 提取 ContextCarrier ,这时它与 1 肯定是不一样的,因为前面做了 inject ,注入了上下文,因此这边一定能够拿到上下文,那么它就会做一个 Segment2 和 Segment1 的绑定关系。然后它又会创建一个 exit ,跟前面一样。
最后面 TraceSegment3 也是一样的,Create 、Extract、exit、stop 退出来。
New Thread 这边实际上起了一个新的线程,这里面的一些概念不是 OpenTracing 里面的。首先我们会做一个 Capture Snapshot 的操作,与 inject 的操作类似,但是里面的数据一个是跨线程,一个是跨进程,所以里面的数据实际上是不太一样的,但是逻辑类似,把当前的上下文保存下来,然后把 Snapshot 传递到新线程里面,再做 Continued Snapshot ,把 sanpshot 继续,这个继续的操作会创建 TraceSegment4 ,因为你把以前的状态做了状态恢复。那么它创建了一个新的 TraceSegment ,同时有去做了一个绑定,这时候它在新线程里面跑的东西就似,把当前的上下文保存下来,然后把 Snapshot 传递到新线程里面,再做 Continued Snapshot ,把 sanpshot 继续,这个继续的操作会创建 TraceSegment4 ,因为你把以前的状态做了状态恢复。那么它创建了一个新的 TraceSegment ,同时有去做了一个绑定,这时候它在新线程里面跑的东西就会在新的 TraceSegment 去存储它想要的信息。
这里描述的基本上是一个通行标准,你在所有的 APM 的产品里面都会见到类似的流程,大家可能做的事情不一样,但是内容基本上都是一样的。所以我这里拿到 skywalking 去做一个分析。
(四)演示实例

演示环节用了一个非常简单的 Spring Cloud 的例子,使用了 Spring Cloud 里面的 Netflix Eureka 等东西做了例子,以下是演示程序的源代码:https://github.com/SkywalkingTest/spring-cloud-example 。
当网络条件调用很好的时候,调用的情况如下图:

调用情况
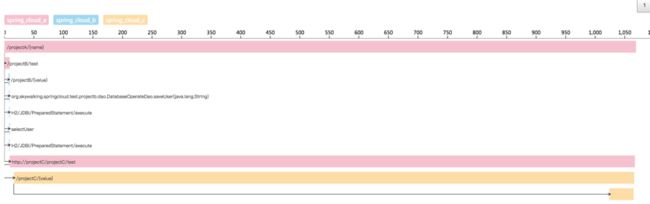
追踪情况
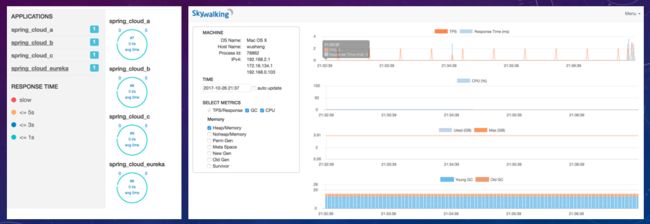
JVM
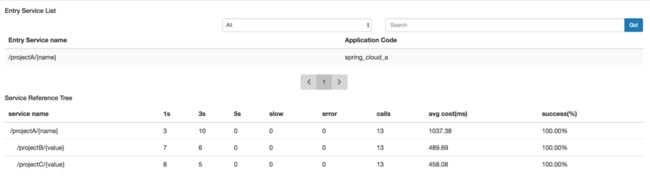
服务依赖树
演示实例详情请观看视频资料。