有些服务器上可能安装了多块GPU供大家共同使用,为了不产生冲突,有时需要按情况指定自己的程序具体在哪些GPU上运行。
(注意:本文主要参考了https://blog.csdn.net/qq_38451119/article/details/81065675,我这里主要是记录一下,以后自己再用到的时候方便查找)
下面是实验室GPU的情况:
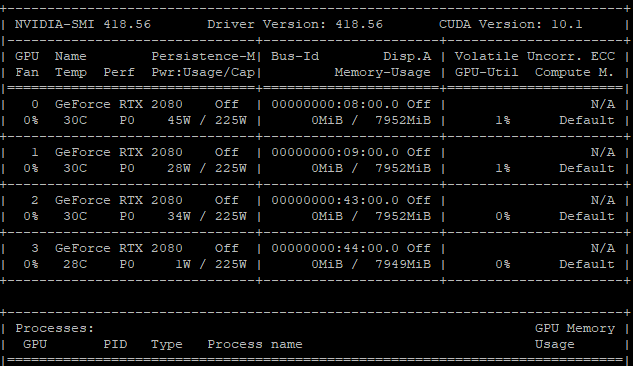
下面是具体的方法:
1. 在python代码中通过CUDA_VISIBLE_DEVICES来指定
比如,我要使用上面编号为“3”的GPU来运行我的程序,则需要在自己的程序中加入以下代码:
1 import os 2 os.environ('CUDA_VISIBLE_DEVICES') = '3'
下面可以通过命令:nvidia-smi 来查看GPU的使用情况:
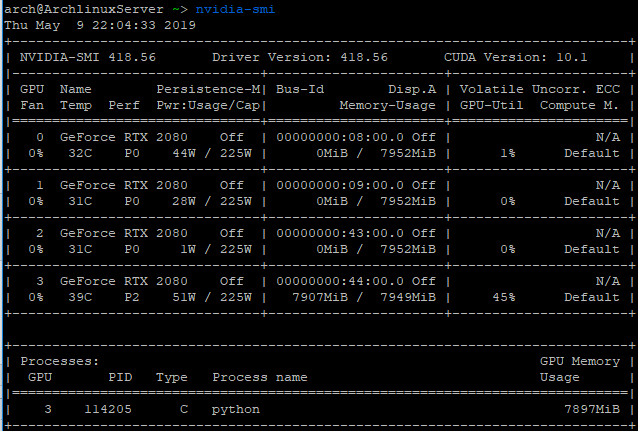
可以看到编号为“3”的GPU已经被我占用了,而其他几块GPU则没被占用,这种就相当于在我们运行程序的时候,将除编号为“3”的GPU以外的其他GPU全部屏蔽了,只有编号为“3”的GPU对当前运行的程序是可见的。
同样,如果要占用多块GPU的话,比如使用编号为”1,2“的GPU来训练,则上面的代码可以改成:
import os os.environ('CUDA_VISIBLE_DEVICES')='1,2'
2. 在终端执行.py文件时通过CUDA_VISIBLE_DEVICES来指定
该方法与方法1本质上是一样的,只不过一个是在代码中指定GPU,一个是在执行代码的命令行中指定GPU。
命令行形式如下:
CUDA_VISIBLE_DEVICES=1 python train.py
3. 在python代码中通过tf.device()函数来指定训练时所要使用的GPU
比如,我要使用上面编号为“1”的GPU来运行我的程序,则需要在自己的程序中加入以下代码:
import tensorflow as tf tf.device('/gpu:1')
下面是实验结果(注:我自己没尝试这种方式,所以下面的实验结果图示直接用的博客https://blog.csdn.net/qq_38451119/article/details/81065675中的):
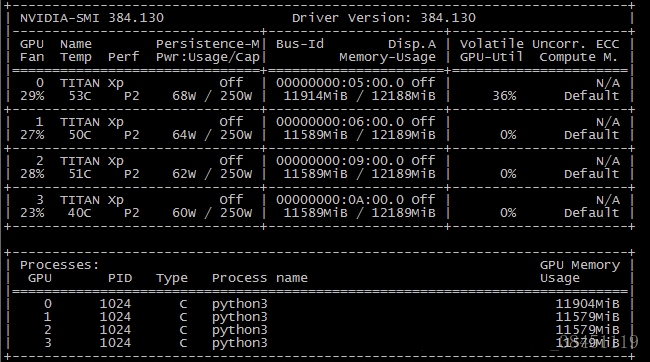
可以看到,这样指定GPU还是有一点毛病的。虽然指定了第“1“块GPU来训练,但是其它几个GPU也还是被占用,只是模型训练的时候,是在第1块GPU上进行。所以,最好使用前面介绍的第1,2种方法。