阿里云图数据库GDB揭秘
背景
如果你关注过db-engines.com,你很可能会发现有一种类别的数据库在最近几年正以火箭般的速度迅速流行起来,那就是Graph DBMS。阿里云于2019年3月重磅发布了数据库新产品——图数据库(Graph Database,简称GDB),本文将从图数据库的基本背景知识说起,带你深入了解阿里云Cloud-Native图数据库GDB。
什么是图数据库
“A graph database is a database that uses graph structures for semantic queries with nodes, edges and properties to represent and store data. A key concept of the system is the graph (or edge or relationship), which directly relates data items in the store a collection of nodes of data and edges representing the relationships between the nodes. The relationships allow data in the store to be linked together directly, and in many cases retrieved with one operation. Graph databases hold the relationships between data as a priority. Querying relationships within a graph database is fast because they are perpetually stored within the database itself. Relationships can be intuitively visualized using graph databases, making it useful for heavily inter-connected data.”,
上面是维基百科上对图数据库的一段定义描述以及一个简单示例。简单说来,典型的图结构由点,边和点边对应属性构成。图数据库则是针对图这种结构的独有特点而专门设计的一种数据库,非常适合高度互连数据集的存储和查询。示例中描述的是一个极度简化的社交关系图,圆圈代表顶点(Vertex/Node), 有方向的线条代表边(Edge),顶点或者边都可以有属性(Property)。现实中的,图数据库覆盖的应用场景非常广泛,比较典型的有社交网络,欺诈检测,推荐引擎,知识图谱和网络/IT运营等。
图数据库 vs 传统关系型数据库
所谓术业有专攻,相对于传统的关系型数据,图数据库更擅长高密互连的数据处理。让我们先从Linkedin类似查询为例来管中窥豹看看图数据库的价值。
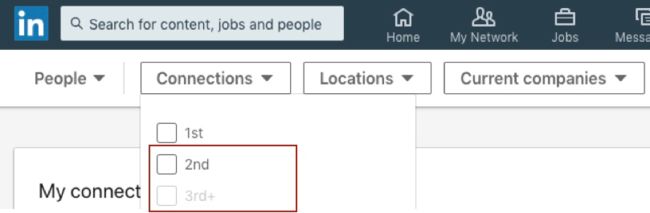
比如,用户UserId-xxx发起“_查询自己2度好友中名字叫James的人_”这样一个查询请求。以传统关系数据库的做法,你可能会写出如下查询语句:
select * from t as t3 where t3.uid in(
select friend_uid from t as t2 where t2.uid in (
select friend_uid from t as t1 where t1.uid='UserId-xxx'
)
) and t3.name='James'抛开查询语句的复杂度,该类查询语句在关系型数据库中执行起来是非常低效的,往往要秒级才能正常返回。如果进一步变为3度查询,则更慢了。那么,要是采用图数据库呢?以Gremlin为例,你可以很简单的写出这样一段查询语句:
g.V('UserId-xxx').repeat(both().simplePath()).times(2).dedup().has('name', 'James')更为关键的是,这种2度,3度查询请求在图数据库中处理起来是非常高效的,性能往往能够轻松的达到传统关系型数据库的十倍乃至几十倍。这种性能的差异并非简单的调优问题,而是更深层次的数据库建模以及内核层面决定的。可以说,图数据库在基因层面更适合高度连接数据库的处理。
下面的表格将从更多层面对二者进行对比:
| 分类 | 关系型数据库 | 图数据库 |
|---|---|---|
| 模型 | 表结构 | 图结构 |
| 存储信息 | 高度结构化数据 | 结构化/半结构化数据 |
| 2度查询 | 低效 | 高效 |
| 3度查询 | 低效/不支持 | 高效 |
| 空间占用 | 中 | 高 |
图模型
图的概念源自图论,大家如果有所了解,可能听得最多的会是无向图,有向图这两种概念。
| 图分类 | 描述 | 示例 |
|---|---|---|
| 无向图 | 一个图中所有的边都是无方向的,比较典型例子就是facebook社交网络中的好友关系。 |  |
| 有向图 | 图中的边是有方向的,比较典型的例子就是Twitter这种社交网络中的关注关系。 |  |
随着理论和技术的不断演进,当前在图数据库的应用当中,最为流行的是下面两种图模型:
| 图模型 | 描述 | 示例 |
|---|---|---|
| 属性图 | 属于有向图,进一步细化了点和边的属性特点(部分进一步增加了Label概念),是当前图数据库采用的主流模型。 |  |
| RDF图 | 核心是一种资源描述方式,每条描述都由主谓宾三元组构成。RDF作为W3C标准大量应用于知识图谱等相关应用。 |  |
RDF是当前W3C的一个推荐标准,同时有标准查询语言SPARQL配合,在早期有大量RDF Stores产品出现。大家可以看到db-engines.com到目前还保留着RDF Stores这样一个分类。后来,属性图模型被大量图数据库产品所采用,属性图相对RDF更为灵活,新的图数据库也逐渐侵蚀部分RDF Stores的市场,更有不少产品在属性图基础之上做RDF及SPARQL的支持,以便无缝的承接RDF及SPARQL之上的各类应用及生态。
图数据库GDB整体介绍
阿里云图数据库(Graph Database, 简称GDB)是一种支持属性图模型,用于处理高度连接数据查询与存储的实时可靠的在线数据库,支持 Apache TinkerPop Gremlin 查询语言,可以帮助用户快速构建基于高度连接的数据集的应用程序。阿里云图数据库GDB具有如下特点:
- 开放图查询语言:支持属性图模型,高度兼容Gremlin图查询语言
- 服务高可用:支持高可用实例,节点故障迅速转移,保障业务连续性
- 高度优化的自研引擎:高度优化的自研图计算层和存储层,云盘多副本保障数据超高可靠,支持ACID事务
- 易运维:提供备份恢复,自动升级,监控告警,故障切换等丰富的运维功能,大幅降低运维成本
开放图查询语言
阿里云图数据库GDB支持属性图模型,公测版对外开放Apache TinkerPop Gremlin图查询语言。

Gremlin是一由Apache TinkerPop提供支持的图查询语言,License为开源的Apache License Version 2.0。Gremlin和传统SQL有明显区别,是一种函数式、面向数据流的查询语言,使用户可以更为直接地控制和表达图查询的复杂逻辑。Gremlin包含一个宽松的DSL规范描述,以及基于Java/Groovy的开源实现。
阿里云图数据库GDB实现了Gremlin的高度兼容,支持直接使用开源的3.3.3版本以3.4版本开源客户端连接GDB进行操作,具体包括Gremlin Console,Java SDK,Python SDK,.Net SDK,并且支持Rest接口。如果希望进一步了解具体兼容性,可以参考:GDB Gremlin实现的兼容性
服务高可用
图数据库GDB公测版本支持高可用实例,后续商业化将进一步开放一写多读实例,提供读实例的水平扩展能力。
高可用版本采用一主一备的经典高可用架构,主备都采用独立的图数据库节点,计算与存储分离,主备之间通过复制(默认半同步)实现数据同步,一旦主库发生故障,将迅速检测并触发主备切换来保证可用性。备库故障对业务无影响,但会快速被检测到并触发备库自愈。未来提供一写多读实例后,所有读写实例将共享底层存储资源(3副本),提升扩展性的同时也将带来整体存储成本的进一步降低。
高度优化的自研引擎
图数据库GDB由阿里云自主研发,是一款高度优化的Cloud-Native图数据库,虽然归属No-SQL数据库分类,但提供了完整的ACID事务支持。在上云之前,图数据库GDB在阿里巴巴已经有大量内部客户使用。图内核经历过多个版本深度打磨,同时针对云环境进行了大量调优。GDB公测版本基于云盘构建,云盘多副本提供了数据超高可靠保障。
下图是GDB内核部分核心能力示意:
整体上,图数据库内核包含计算和存储两层,计算层专注在图相关能力抽象及实现,存储层专注在数据的内部布局及高效存取。下面将对GDB内核的部分核心能力进行进一步解析:
- Gremlin Runtime: 实现了Gremlin DSL的高效解析及执行计划的生成。同时为保障DSL的安全执行,内部实现了一层沙箱来做安全防护。
- Cost-Based Optimizer: 通过完整的信息统计和代价估算,以CBO(Cost-Based Optimizer)为主体,辅以部分RBO(Rule-Based Optimizer),来对执行方案进行优化。
- Parallel Query Execution: 当前主要采用了基于Morsel机制的并行执行, 同时也在基于场景不断探索和验证更有效的并行执行方案。
- Read Committed Isolation Level: GDB提供了一种自动事务机制,针对每一条DSL都会自动生成一个事务并在执行结束时基于结果提交或者终止。公测版本当前默认为Read-Committed隔离级别,更多的隔离级别将在未来开放并提供入口让用户自行权衡设定。
- Fine-Grained Locking: GDB内部针对读,写,读写混合各类请求进行了细致划分,结合隔离级别,对锁进行了非常细粒度的管理。
- Smart Cache: GDB内部实现了两层Cache,包括Object Cache及Block Cache,同时会基于用户的请求特征自行调整Cache策略。
- High Performance Transaction Mechanism: 一个复杂DSL本质对应的是一个复杂的父事务,在执行优化后将会被拆解成多个子事务来执行,GDB内部实现了一套非常高效的事务装置,能够在保证事务正确性的同时提供最大的并发性。
- Schema-Agnostic Indexing: GDB采用Schema-free的设计,支持自动索引,用户无需面对繁杂的索引管理和优化相关事情,只需专注在业务自身的实现即可。
- Highly-Tuned Storage Engine: GDB基于图结构的特点设计了全新的存储方案,同时基于云盘等云上环境进行了大量针对性调优。
- High Reliability: GDB采用云盘作为存储,每份数据3副本,配合高可用设计,能够最大程度的保证数据的可靠性。
易运维
除核心图数据库服务能力外,GDB为用户提供了大量运维配套能力。包括备份恢复,自动升级,监控告警,故障切换等,可以帮助用户大幅降低运维成本。
图数据库GDB未来演进
图数据库GDB还在迅速的演进和完善当中,不久的未来,我们会提供:
- 更强大的备份恢复能力
- 更强大的弹性及水平扩展能力
- 丰富的数据迁移工具
- 完善的数据管理工具(可视化,性能诊断,审计等)
- 常见的图算法
我们也会进一步在各个层面对图数据库的生态进行完善,包括提供相关工具或环境让用户能够便利的对接到业界流行的的一些图相关系统,比如可视化系统,分析系统等。
写在最后
图数据库GDB是阿里云数据库家族为覆盖更全面企业场景而重磅推出的最新力作,拥有很多优秀的特性。当前图数据库GDB已经正式公测发布,https://www.aliyun.com/product/gdb,欢迎体验和反馈!