Comparator排序源码分析
Comparator排序源码分析
comparator是什么:
以下是官网给出的解释,我用有道翻译进行翻译
一种比较函数,它对某些函数进行总排序对象的集合。比较器可以传递给排序方法(例如作为{@link collection #sort(List, Comparator)集合。}或{@link排序数组#sort(Object[],Comparator)数组超过排序顺序。比较器也可以用来控制的顺序某些数据结构(如{@link SortedSet ordered set}或{@link)或为集合提供排序没有{@link可比较的自然顺序}的对象。
比较器c对一组元素施加的顺序当且仅当S与等号一致c.compare(e1, e2)==0具有与之相同的布尔值等于(e2)对于每一个e1和e2年代。
在使用能够施加一项与等于不一致的排序等于对已排序集(或已排序映射)排序。假设一个具有显式比较器c的排序集(或排序映射)与从集合s中抽取的元素(或键)一起使用c对S施加的顺序与等号不一致,排序后的集合(或排序后的映射)将表现“奇怪”。尤其是排序集(或排序映射)将违反集合(或)的总契约map),它是用等号来定义的。
例如,假设添加了两个元素{@code a}和{@code b}{@code (a. = (b) && c.compare(a, b) != 0)}到一个空的{@code TreeSet}与比较器{@code c}。第二个{@code add}操作将返回true(并且树集的大小将会增加),因为{@code a}和但是,从树集的角度来看,{@code b}并不等价这是违反规格的方法。
注:一般来说,比较国也应加以执行. io .可序列化的,因为它们可以用排序方法可序列化的数据结构(如{@link TreeSet}、{@link TreeMap})。在为了使数据结构序列化成功,比较器(if)必须实现序列化。 对于有数学倾向的人,定义给定比较器c对a施加的强制顺序给定对象集合S为:{(x, y),这样c.compare (x, y) & lt; = 0}。这个总阶的商是:{(x, y)使得c.compare(x, y) == 0}。它立即从合同中得到了比较商是关于S的等价关系,它是强制排序是对s的总排序c对S的排序是一致的等于,我们的意思是顺序的商是等价的由对象的{@link Object#equals(Object)定义的关系=(对象)}方法(s):{(x, y)使得x. = (y)}。与{@code Comparable}不同,比较器可以选择允许比较空参数,同时维护对一个等价关系。
如果以上解释篇幅太长,可以看这个
Comparator 是比较器接口。
我们若需要控制某个类的次序,而该类本身不支持排序(即没有实现Comparable接口);那么,我们可以建立一个“该类的比较器”来进行排序。这个“比较器”只需要实现Comparator接口即可。
也就是说,我们可以通过“实现Comparator类来新建一个比较器”,然后通过该比较器对类进行排序。
用法:
如果我们查看Comparetor接口类,会发现@FunctionalInterface这个注解,被该注解描述的接口类为函数式接口,所谓的函数式接口,当然首先是一个接口,然后就是在这个接口里面只能有一个抽象方法。
这种类型的接口也称为SAM接口,即Single Abstract Method interfaces
用这个有什么用 -使用lambda表达式实例化该接口,很方便
当方法的参数是带@FunctionInterface的接口时,在调用该方法时可以使用lambda表达式实例化该接口,达到简化写法的目的
FunctionalInterface
通过JDK8源码javadoc,可以知道这个注解有以下特点:
1、该注解只能标记在"有且仅有一个抽象方法"的接口上。
2、JDK8接口中的静态方法和默认方法,都不算是抽象方法。
3、接口默认继承java.lang.Object,所以如果接口显示声明覆盖了Object中方法,那么也不算抽象方法。
4、该注解不是必须的,如果一个接口符合"函数式接口"定义,那么加不加该注解都没有影响。加上该注解能够更好地让编译器进行检查。如果编写的不是函数式接口,但是加上了@FunctionInterface,那么编译器会报错。
下面我们来分析一下comparetor实现思路及过程
首先我们先定义一个Student对象
public class Student {
private String name;
private int age;
private String sex;
public Student(String name, int age,String sex){
this.name = name;
this.age = age;
this.sex=sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String toString(){
return this.name + ":" + this.age+":"+this.sex;
}
}
定义一个main方法类定义 add方法来对Student进行排序
public class test {
public static void main(String[] args){
add();
}
public static void add(){
List<Student> list = new ArrayList();
list.add(new Student("Aack",10,"男"));
list.add(new Student("rose",36,"女"));
list.add(new Student("lucy",97,"女"));
list.add(new Student("Tom",42,"男"));
list.add(new Student("wang",26,"男"));
System.out.println(list);
list.sort(Comparator.comparing(e ->e.getSex()));
System.out.println(list);
// list.sort(Comparator.comparing(e ->e.getName()));
// System.out.println(list);
// list.sort(Comparator.comparing(e ->e.getAge()));
// System.out.println(list);
// Collections.sort(list, Comparator.comparing(Student::getName).reversed());
// System.out.println(list);
// Collections.sort(list, (o1,o2)-> o1.getName().compareTo(o2.getName()));
// System.out.println(list);
// Collections.sort(list, (o1,o2)-> o1.getSex().compareTo(o2.getSex()));
// System.out.println(list);
}
}
下面我们打上断点开始分析:
程序启动我们向下走
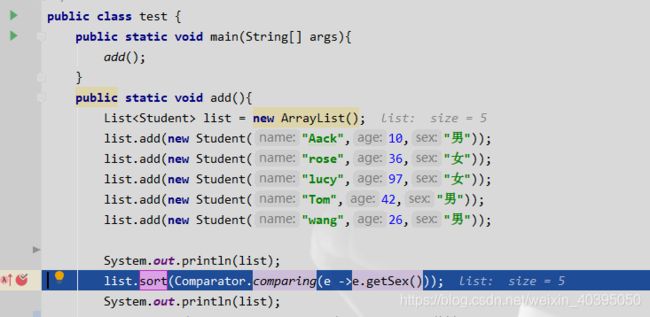
注意堆栈信息,我们并没有直接进入sort方法,虽然我们图显示进入sort方法,但是我们sort参数是一个lambda表达式
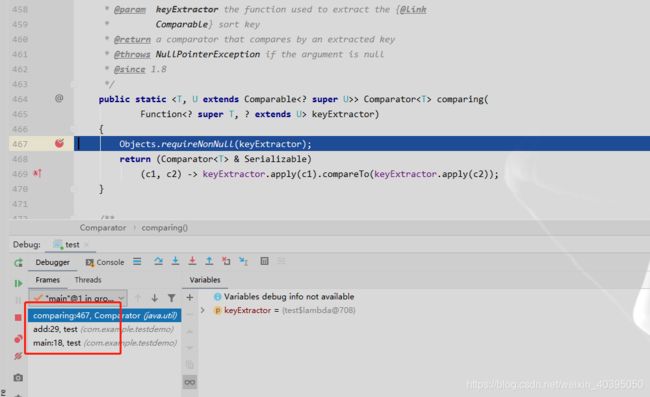
再看蓝色背景部分的代码

这是Object定义的一个判断对象是否为空,返回异常或者此对象

我们可以看到参数中有个Function接口类型的keyExtractor,keyExtractor是待处理元素,首先我们知道Function接口中有个apply方法用于,接收T和U对象返回R对象,根据这里的写法,显而易见我们是将传入进来的T和U转换成继承了Compareable接口的R并进行返回
继续向下debug,可以看到我们执行完了comparing方法,然后又继续执行sort方法


以下属于排序中的知识范围
进入到Arrays工具类中的sort方法

首先判断传入的comparator是否为空,如果为空直接进行排序操作

可以看到我们的c不为空,所以继续向下执行rangeCheck方法进行范围检查:范围检查:0<=fromIndex<=toIndex<=arrayLength
下面为大家贴出rangeCheck的源码可自行研究
/**
* Checks that {@code fromIndex} and {@code toIndex} are in
* the range and throws an exception if they aren't.
*/
private static void rangeCheck(int arrayLength, int fromIndex, int toIndex) {
if (fromIndex > toIndex) {
throw new IllegalArgumentException(
"fromIndex(" + fromIndex + ") > toIndex(" + toIndex + ")");
}
if (fromIndex < 0) {
throw new ArrayIndexOutOfBoundsException(fromIndex);
}
if (toIndex > arrayLength) {
throw new ArrayIndexOutOfBoundsException(toIndex);
}
}
判断用户是否指定排序方式
(sort有一个分支判断,当LegacyMergeSort.userRequested为true的情况下,采用legacyMergeSort,否则采用ComparableTimSort。LegacyMergeSort.userRequested的字面意思大概就是“用户请求传统归并排序”的意思。
legacyMergeSort是传统的归并排序,而ComparableTimSort是优化的归并排序。)

向下继续执行TimSort.sort方法 我只贴出这个方法的核心代码
int nRemaining = hi - lo;//要排序的数量
if (nRemaining < 2)//小于二说明已经有序了
return; // Arrays of size 0 and 1 are always sorted
//数组前一部分升序,后一部分无序
//长度小于32,则调用 binarySort,这是一个不包含合并操作的mini-TimSort排序方式
//32作为阙值,2的五次幂二分法查找最多需要5次,可能是为了解决临时数组占用过长的空间的问题还有可能是为了解决递归深度过深溢出的问题
//那为什么是32而不是16呢,可能是经验值,效率最大化。
if (nRemaining < MIN_MERGE) {//MIN_MERGE 默认值为32,
int initRunLen = countRunAndMakeAscending(a, lo, hi, c);//这个方法是为了查找连续递增,如果是连续递减则倒序反转
binarySort(a, lo, hi, lo + initRunLen, c);//假设lo,到lo+inniRunLen是有序的,二分法对其他部分数据做处理
return;
}

countRunAndMakeAscending方法
run:一个最长的按升序排列的序列;或者一个最长的按严格的降序排列的序列。
方法接收的参数有三个,待查找的数组,起始下标,终点下标。
基本思想是:判断第二个数和第一个数的大小来确定是升序还是降序,
若第二个数小于第一个数,则为降序,然后在while循环中,若后后面的数依旧小于前面的数,则runHi++计数,直到不满足降序;然后调用reverseRange进行反转,变成升序。
若第二个数大于第一个数,则为升序,然后在while循环中,若后面的数依旧大于前面的数,则runHi++计数,直到不满足升序。
返回runHi - lo也就是严格满足升序或者降序的个数。且这个严格序列是从第一个开始的。最后都是严格的升序序列。
@SuppressWarnings({"uncheck", "rawtypes"})
private static int countRunAndMakeAscending(Object[] a, int lo, int hi){
assert lo < hi;
int runHi = lo + 1;
if(runHi == hi)
return 1;
//Find end of run, and reverse range if descending
if(((Comparable) a[runHi++]).compareTo(a[lo]) < 0){ // Descending
while(runHi < hi && ((Comparable) a[runHi]).compareTo(a[runHi -1]) < 0)
runHi++;
reverseRange(a, lo, runHi);
} esle { //Ascending
while(runHi < hi && ((Comparable) a[runHi]).compareTo(a[runHi -1]) >= 0)
runHi++;
}
return runHi - lo;
}
这里我们调用compare方法
因此这一遍执行决定排序的顺序
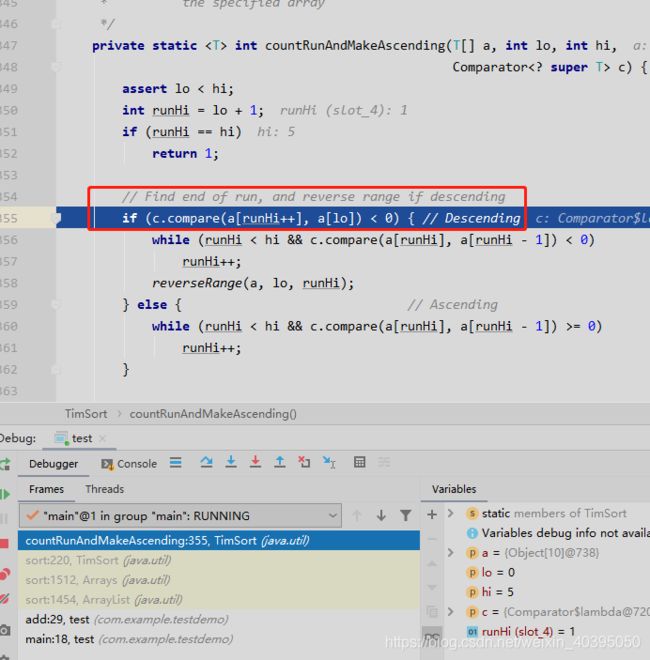
注意我们的堆栈信息,红框是我们当前的方法,绿框是我们调用countRunAndMakeAscending对c.compare(a[runHi++], a[lo])进行判断的值,蓝框是我们countRunAndMakeAscending的判断方法
我们继续向下执行 c1为 rose:36:女 c2为 Aack:10:男
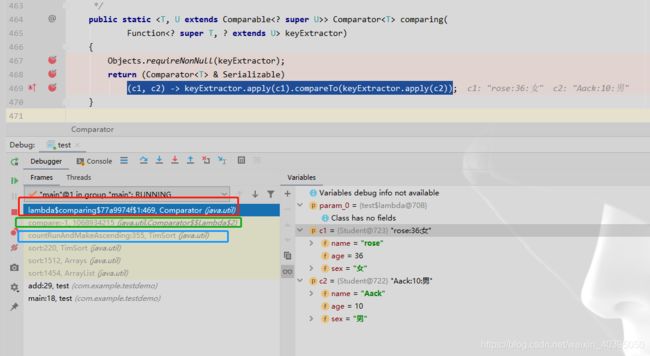
调用compareTo方法,(多出一条堆栈信息,点开查看结果跳到String类,所以我觉得这里应该是做了类型转换,因为compareTo方法的参数就是String类型)
compareTo比较的是两个字符串的字典顺序,如果两个字符串的字典顺序相等,则返回0.如果此字符串比传入的参数字符串的字段顺序小则返回一个小于0的数,如果大则返回一个大于0的数。

继续执行,我们又回到了countRunAndMakeAscending方法中,我们发现他再一次调用了compare方法,所以又重新执行上面的操作
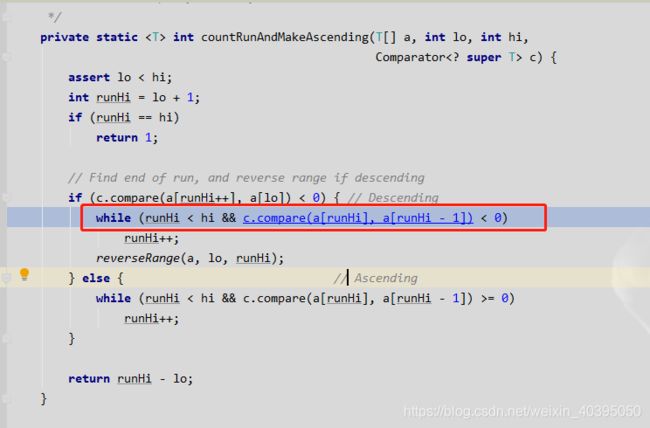
值得注意的是此时比较的参数已经发生变化

比较结束之后,向下执行countRunAndMakeAscending中的reverseRange 我们如果观察这部分代码就会,发现他做了一个数组交换的操作,在冒泡排序中我们经常会有这样的写法 (反转指定数组的指定范围)
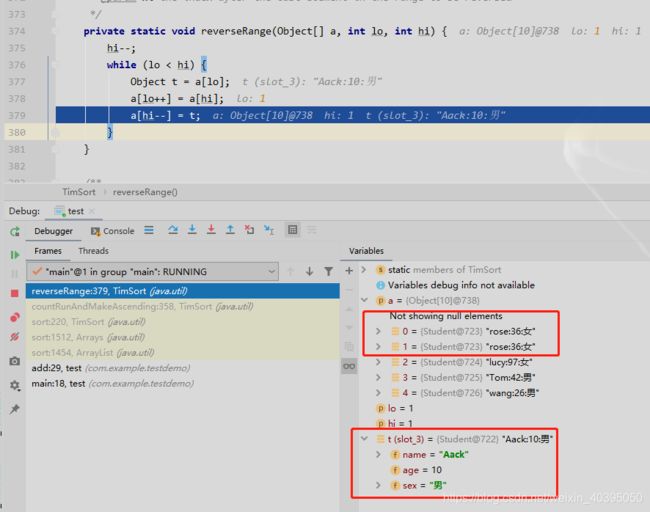
执行结束之后我们的list已经发生了变化,并且返回了当前的计数值 2

继续执行代码跳到了binarySort方法 二分插入排序
举个binarySort的例子
6 2 1 5 8 8 4
//循环执行binarySort方法后,
//会依次把 5 8 8 4 插入到相应的位置
//最终的结果为:
// 8 8 6 5 4 2 1
private static <T> void binarySort(T[] a, int lo, int hi, int start,
Comparator<? super T> c) {
assert lo <= start && start <= hi;
if (start == lo)
start++;
for ( ; start < hi; start++) {
T pivot = a[start];
// Set left (and right) to the index where a[start] (pivot) belongs
int left = lo;
int right = start;
assert left <= right;
//查找到所需插入位置索引
while (left < right) {
int mid = (left + right) >>> 1;
if (c.compare(pivot, a[mid]) < 0)
right = mid;
else
left = mid + 1;
}
assert left == right;
//进行插入(插入位置是1或2时优化)
int n = start - left; // The number of elements to move
// Switch is just an optimization for arraycopy in default case
switch (n) {
case 2: a[left + 2] = a[left + 1];
case 1: a[left + 1] = a[left];
break;
default: System.arraycopy(a, left, a, left + 1, n);
}
a[left] = pivot;
}
}
当binarySort执行到这里,再次调用compare方法,和它后面的元素进行比较
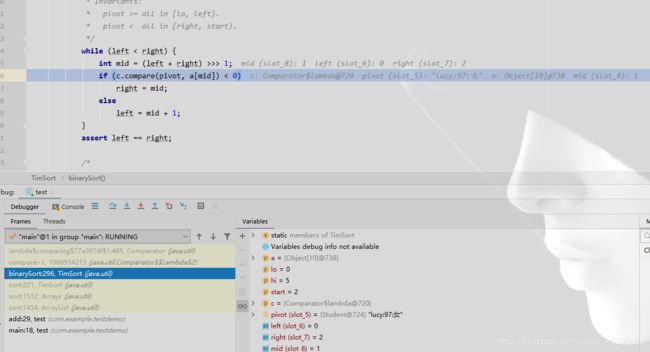

然后执行compareTo方法,返回比较结果,再次回到binarySort方法内进行判断,
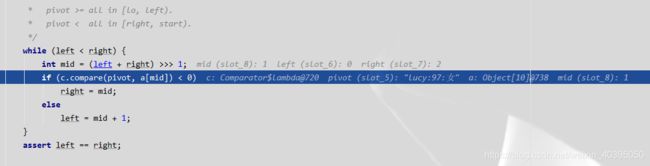
然后重复之前的操作,直到将所有元素排序后,结束!
总的来说这一篇文章是对sort和comparator运行流程的一篇介绍,当中遗漏了很多东西,并没有涉及到太多理论性和概念性的东西,涉及到的算法已经排序结构,如果有机会后续我会继续发表。
我也对这方面的东西没有太多的了解,我希望可以通过这篇文 章让大家多少有一点帮助,底层很多东西,看的也不是很明白,如果本帖有任何不正确的言论和理解,希望大家能够指出。
--作者:额滴神