HMM学习二:Baum-Welch算法详解(学习算法)
一,前言
在上篇博文中,我们学习了隐马尔可夫模型的概率计算问题,如果对隐马尔可夫模型还不胜了解的话,可参看博文HMM学习(一)。
学习问题
隐马尔可夫模型的学习,根据训练数据是包括观测序列和对应的状态序列还是只有观测序列,可以分别由监督学习与非监督学习实现。本节首先介绍监督学习算法,而后介绍非监督学习算法——Baum-Welch算法(也就是EM算法)。
监督学习问题
假设已给训练数据包含S个长度相同的观测序列和对应的状态序列 ( O 1 , I 1 ) , ( O 2 , I 2 ) , . . . , ( O S , I S ) ( O 1 , I 1 ) , ( O 2 , I 2 ) , . . . , ( O S , I S ) {(O_1,I_1),(O_2,I_2),...,(O_S,I_S)}{(O_1,I_1),(O_2,I_2),...,(O_S,I_S)} (O1,I1),(O2,I2),...,(OS,IS)(O1,I1),(O2,I2),...,(OS,IS),那么可以利用极大似然估计方法来估计隐马尔可夫模型的参数,具体方法如下。
1.转移概率 a i j a i j a_{ij}a_{ij} aijaij的估计
设样本中时刻t处于状态i时刻t+1转移到j的频数为 A i j A i j A_{ij}A_{ij} AijAij,那么状态转移概率为 a i j a_{ij} aij的估计是

直接根据给定的O和I进行频数统计,在海藻模型中,我们可以统计100天前的天气转移次数,如在100天内,统计从sunny -> sunny 的次数,sunny -> cloudy 的次数,sunny - > rainy的次数,分别记作 a 1 , a 2 , a 3 a_1,a_2,a_3 a1,a2,a3,那么 a s u n n y − > a n y s t a t e a_{sunny−>any state} asunny−>anystate=[ a 1 a 1 + a 2 + a 3 \frac{a_1}{a_1+a_2+a_3} a1+a2+a3a1, a 2 a 1 + a 2 + a 3 \frac{a_2}{a_1+a_2+a_3} a1+a2+a3a2, a 3 a 1 + a 2 + a 3 ] \frac{a_3}{a_1+a_2+a_3]} a1+a2+a3]a3。因此,状态转移矩阵可以根据给定的隐藏序列 I I I计算得出。
2.观测概率 b j ( k ) b_j(k) bj(k)的估计
设样本中状态为 j j j并观测为 k k k的频数是 B j k B_{jk} Bjk,那么状态为 j j j观测为 k k k的概率 b j ( k ) b_j(k) bj(k)的估计是
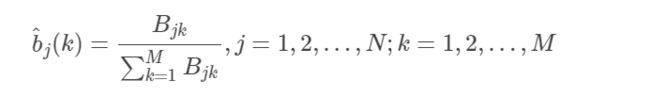
根据公式,我们可以知道 B j k B j k B_{jk}B_{jk} BjkBjk跟观测序列和隐藏状态均有关系,所以给定一组观测序列和对应的隐藏状态如: O = " d r y " , " d a m p " , " s o g g y " , I = " s u n n y " , " c l o u d y " , " r a i n y " O = " d r y " , " d a m p " , " s o g g y " , I = " s u n n y " , " c l o u d y " , " r a i n y " O="dry","damp","soggy",I="sunny","cloudy","rainy"O="dry","damp","soggy",I="sunny","cloudy","rainy" O="dry","damp","soggy",I="sunny","cloudy","rainy"O="dry","damp","soggy",I="sunny","cloudy","rainy",当然这里的数据还不够多,假设我们有足够多的数据,那么统计 s u n n y − > d r y sunny -> dry sunny−>dry的次数, s u n n y − > d r y i s h sunny -> dryish sunny−>dryish的次数, s u n n y − > d a m p sunny -> damp sunny−>damp的次数, s u n n y − > r a i n y sunny - > rainy sunny−>rainy的次数,分别记作 b 1 , b 2 , b 3 , b 4 b_1,b_2,b_3,b_4 b1,b2,b3,b4,那么 b s u n n y − > a n y o b s e r v a t i o n b_{sunny−>any observation} bsunny−>anyobservation= b 1 s u m \frac{b1}{sum} sumb1, b 2 s u m \frac{b_2}{sum} sumb2, b 3 s u m \frac{b_3}{sum} sumb3, b 4 s u m \frac{b_4}{sum} sumb4], s u m = b 1 + b 2 + b 3 + b 4 sum=b1+b2+b3+b4 sum=b1+b2+b3+b4。由此可以根据 O O O和 I I I算出 B i j B i j B_{ij}B_{ij} BijBij。
3.初始状态概率 π i π_i πi的估计 π i π_i πi为S个样本中初始状态为 q i q_i qi的频率
由于监督学习需要使用训练数据,而人工标注训练数据往往代价很高,有时就会利用非监督学习的方法。
上述监督学习问题给定了大量一一对应的观察序列和隐藏序列,用最简单的概率统计方法就能求得转移矩阵,观测概率矩阵的频数,注意这里是频数而非概率。这部分的内容相对简单,但针对非监督学习问题时,由于多了隐藏变量,而系统的各种参数均未知,因此求解非监督学习问题时,就存在一定难度,本文用到的知识有极大似然估计,EM算法,基础概率论,如果对这些知识还不够熟悉的话,建议回到前言提到的链接,看完链接内容后,对理解Baum-Welch算法将大有帮助。
Baum-Welch算法
刚才提到了,非监督学习问题是为了计算模型参数λλ,使得在该参数下 P ( O ∣ λ ) P ( O ∣ λ ) P(O|λ)P(O|λ) P(O∣λ)P(O∣λ)的概率最大。这个问题便是我们的极大似然估计,但 P ( O ∣ λ ) P ( O ∣ λ ) P(O|λ)P(O|λ) P(O∣λ)P(O∣λ)并非孤立的存在,其背后与隐含状态相联系。这句话应该怎么理解呢,在海藻模型中,如我们观测到某一海藻序列 O = " d r y " , " d a m p " , " s o g g y " O={"dry","damp","soggy"} O="dry","damp","soggy",但是什么决定了海藻的湿度情况呢,很明显天气的因素占有很大的一部分,因此盲人在对海藻模型进行建模时,就把隐含的天气转移状态给考虑进去了。正如双硬币模型中,由于实习生b的失误,每组数据我们并不清楚是A掷的还是B掷的,遇到信息缺失的情况,就导致了用单纯的极大似然估计求导法是无法得到解析解的。
假设给定训练数据中包含S个长度为T的观测序列 O 1 , O 2 , . . . , O S {O_1,O_2,...,O_S} O1,O2,...,OS而没有对应的状态序列,目标是学习隐马尔可夫模型 λ = ( A , B , π ) λ=(A,B,π) λ=(A,B,π)的参数。我们将观测序列数据看作观测数据 O O O,状态序列数据看作不可观测的隐数据II,那么隐马尔可夫模型事实上是一个含有隐变量的概率模型
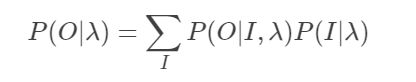
它的参数学习可以由EM算法实现。
1.确定完全数据的对数似然函数
所有观测数据写成 O = ( o 1 , o 2 , . . . , o T ) O=(o_1,o_2,...,o_T) O=(o1,o2,...,oT),所有隐数据写成 I = ( i 1 , i 2 , . . . , i T ) I=(i_1,i_2,...,i_T) I=(i1,i2,...,iT),完全数据是 ( O , I ) = ( i 1 , i 2 , . . . , i T ) (O,I)=(i_1,i_2,...,i_T) (O,I)=(i1,i2,...,iT)。完全数据的对数似然函数是 l o g P ( O , I ∣ λ ) logP(O,I|λ) logP(O,I∣λ)。
2.EM算法的E步:求Q函数

其中, λ ^ \hatλ λ^是隐马尔可夫模型参数的当前估计值, λ λ λ是要极大化的隐马尔可夫模型参数。上式公式需要注意两点,第一,仅仅取 P ( O , I ∣ λ ) P(O,I|λ) P(O,I∣λ)的对数, P ( O , I ∣ λ ^ ) P(O,I|\hatλ) P(O,I∣λ^)是在对数的外面;第二, P ( O , I ∣ λ ^ ) P(O,I|\hatλ) P(O,I∣λ^)是确定的值,即它可能为[0,1]中的任何值,根据 λ ^ \hatλ λ^算出。如果仔细观察式子的话,该式就是对随机变量 I I I求期望。即 E ( f ( I ) ) , f ( I ) = l o g P ( O , I ∣ λ ) E ( f ( I ) ) , f ( I ) = l o g P ( O , I ∣ λ ) E(f(I)),f(I)=logP(O,I|λ)E(f(I)),f(I)=logP(O,I|λ) E(f(I)),f(I)=logP(O,I∣λ)E(f(I)),f(I)=logP(O,I∣λ)。又

于是函数 Q ( λ , λ ^ ) Q(λ,\hatλ) Q(λ,λ^)可以写成:

式中求和都是对所有训练数的序列总长度T进行的。
3.EM算法的M步:极大化Q函数 Q ( λ , λ ^ ) Q(λ,\hatλ) Q(λ,λ^)求模型参数 A , B , π A,B,π A,B,π
由于要极大化的参数在上式中单独地出现在3个项中,所以只需要对各项分别极大化。
(1)上式中的第一项可以写成:

注释: 上面一个公式是将由于 π i 1 π_{i1} πi1是 i = 1 i = 1 i=1的第一个序列的,所以将概率 P ( ) P() P()里面的 I I I转换到第一序列中.
注意到 π i π_i πi满足约束条件 ∑ i = 1 n π i = 1 \displaystyle\sum_{i=1}^{n} π_i = 1 i=1∑nπi=1,利用拉格朗日乘子法,写出拉格朗日函数:
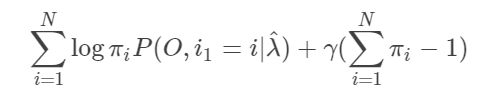
对其求偏导数并令结果为0

注释:求偏导时先只对 π i π_i πi这一个进行求导,求导完成之后再求和
得:

注释:因为 ∑ i = 1 n π i = 1 \displaystyle\sum_{i=1}^{n} π_i = 1 i=1∑nπi=1

(2)上式中的第二项可以写成

类似第一项,应用具有约束条件 ∑ i = 1 n = 1 \displaystyle\sum_{i=1}^{n} = 1 i=1∑n=1的拉格朗日乘子法可以求出
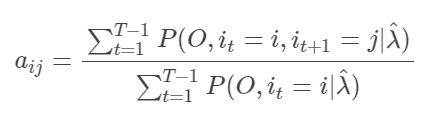
(3)上式中的第三项可以写成

同样用拉格朗日乘子法,约束条件是 ∑ k = 1 M b j ( k ) = 1 \displaystyle\sum_{k=1}^{M} b_j(k)= 1 k=1∑Mbj(k)=1。注意,只有在 o t = v k o_t=v_k ot=vk时, b j ( o t ) b_j(o_t) bj(ot)对 b j ( k ) b_j(k) bj(k)的偏导数才不为0,以 I ( o t = v k ) I(o_t=v_k) I(ot=vk)表示,求得

正因为给出了Q函数,所以进行M步时,我们可以通过求导的方式来求得所有参数的值。但虽然知道了公式的推导过程,实际该如何操作却还是很含糊。不急,接下来我们就开始尝试把这些公式映射到物理空间中去,一步步分析它们的实际含义。
算法实际物理含义
EM算法中M步的各公式的难点在于如何求得这些概率,如 a i j a_{ij} aij该公式分子分母上的联合概率如何计算。其实在我看来,对隐马尔可夫模型中的各种概率计算最后均是映射到节点上去做计算。当然,我们先来观察由EM算法推导出的参数计算公式。
观察式子 a i j 和 b j ( k ) a_{ij}和b_j(k) aij和bj(k),你会发现不管是分子,还是分母,它们都是概率计算,只不过对应的一些状态不一样。具体以 a i j a_{ij} aij举例,如在 a i j a_{ij} aij的分母上计算式子 P ( O , i t = i , i t + 1 = j ∣ λ ^ ) P(O,i_t=i,i_{t+1}=j|\hatλ) P(O,it=i,it+1=j∣λ^),仔细想想,我们在计算什么的时候,有遇到过类似的式子?其实在阐述隐马尔可夫模型的第一个概率计算问题时,我们就做过类似的求解。概率计算是为了计算 P ( O ∣ λ ) P(O|λ) P(O∣λ)的概率,但我们是把式子扩展为 ∑ I P ( O ∣ λ ) \displaystyle\sum_{I}P(O|λ) I∑P(O∣λ)进行计算的。即我们需要在任何隐藏状态序列下求出 P ( O ∣ λ ) P(O|λ) P(O∣λ)的概率。由此我们用前向算法和后向算法来求解该问题.
同样地, P ( O , i t = i , i t + 1 = j ∣ λ ^ ) P(O,i_t=i,i_{t+1}=j|\hatλ) P(O,it=i,it+1=j∣λ^)不就可以看成是对

于是我们就有了前向后向算法中 ξ t ( i , j ) ξt(i,j) ξt(i,j)的定义了,它的定义式为:

还记得前向算法和后向算法是如何定义中间节点的嘛,为了计算 P ( O ∣ λ ) P(O|λ) P(O∣λ),我们给每一个t时刻的隐含状态节点定义了实际的物理含义,即把它们命名为 α t ( i ) 和 β t ( i ) αt(i)和βt(i) αt(i)和βt(i),两个中间变量分别从两边进行有向边加权和有向边汇聚,形成一种递归结构,并且由此不断传播至两端,对任意t=1时刻,和t=T时刻,分别进行累加就能求得 P ( O ∣ λ ) P(O|λ) P(O∣λ),我们还举出了一个小例子,来论证前向算法和后向算法只要满足有向边加权和有向边汇聚就能得到算法的一致性,今天我们根据前向后向算法做进一步的例子推广,从而真正理解 ξ t ( i , j ) ξt(i,j) ξt(i,j)的物理含义。
P ( O ∣ λ ) P(O|λ) P(O∣λ)可写成如下形式:

此时分别当t=1和t=T-1时,前向算法和后向算法分别成立。什么意思呢,也就是根据上式,我们从t=1时刻不断向前递推,将得到前向算法的计算公式,从t=T-1时刻不断向后递推,将得到后向算法的计算公式。这不是废话嘛,没错,但我们实际的来操作一把,注意递推的中间过程,能够帮助我们论证节点图的另外一个重要的性质,也就是节点图的推广性质。
如下图所示:

假设我们从t =T-1时刻开始递推,那么上述式子,把t=T-1代入得

由于α是对i的累加,跟j无关,所以可以把它提到前面去,得

又因为 β t ( i ) β_t(i) βt(i)的递推公式
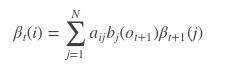
得到:

由 α T − 1 ( i ) α_{T−1}(i) αT−1(i)的递推公式得

所以说,不断的根据α,β两个递推式展开,合并,展开,合并我们能够得到

这是根据前向算法和后向算法的递推公式推导出来的,而前向算法和后向算法的递推式则是由节点图的性质而来,两者之间是等价的.
由此,我们明确了 ξ t ( i , j ) ξ_t(i,j) ξt(i,j)的物理含义,它只是从t时刻出发,由前向算法导出的中间节点Si和从t+1时刻出发,由后向导出的中间节点 S j S_j Sj,且节点 S i 和 S j S_i和S_j Si和Sj中间还有一条加权有向边的关系 a i j b j ( o t + 1 ) a_{ij}b_j(o_{t+1}) aijbj(ot+1),所以我们得

也就是说,我们对 a i j a_{ij} aij分子的计算,我们完全可以有前向算法和后向算法中定义的各个中间变量来求出来。同理,《统计学习方法》中还定义了另外以变量

所以得到:

算法(Baum-Welch算法)

参考文章为:
https://blog.csdn.net/u014688145/article/details/53046765#commentsedit
https://blog.csdn.net/xmu_jupiter/article/details/50965039
http://blog.sina.com.cn/s/blog_8267db980102wpvz.html
李航<<统计学习方法>>