Dubbo从入门到精通-一文贯通
-
dubbo入门
-
服务搭建
-
服务注册与访问
-
dubbo服务高可用
-
dubbo服务后台管理界面
-
Dubbo实现服务降级
-
Dubbo实现版本控制灰度发布:version,group
-
Dubbo实现隐式传参
-
Dubbo启用高速序列化
-
Dubbo服务化配置最佳使用实践
-
Dubbo下的分布式锁实现
-
zookeeper实现分布式锁
-
dubbo常见面试题
dubbo入门

背景:
随着互联网时代的发展,服务架构经历了多重演变:单一架构->垂直架构->分布式架构->soa架构
-
单一架构 orm
所有的前后端服务都集成在一个服务当中,此时能够提高数据库操作的orm框架显得极度重要
-
垂直架构 mvc
随着业务的不断增加,单一应用显得越来越臃肿,为了适应越来越多变化的需求以及高并发服务,将架构进行拆分,特别是对前端以及后台分离的mvc框架显得特别重要
-
分布式架构 rpc
随着业务服务的越来越多,服务之间相互调用越来越频繁,此时通过将基础业务和核心业务抽离,通过统一的服务中心进行维护,
此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键。
-
soa架构 soa
随着机器的越来越多,机器资源的无效浪费,部分服务负载过大的问题显得比较突出。
此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时用于服务治理的soa架构师关键。
需求
-
服务注册与发现
方便服务维护
-
负载均衡
减少对硬件资源依赖,降低硬件成本
-
服务之间依赖关系
自动画出应用之间依赖关系,帮助我们理清关节
-
服务调度与监控
监控服务的运行情况,合理调度服务资源,有效提高集群利用率
架构
节点角色
|
节点
|
角色说明
|
|
Provider
|
暴露服务的服务提供方
|
|
Consumer
|
调用远程服务的服务消费方
|
|
Registry
|
服务注册与发现的注册中心
|
|
Monitor
|
统计服务的调用次数和调用时间的监控中心
|
|
Container
|
服务运行容器
|
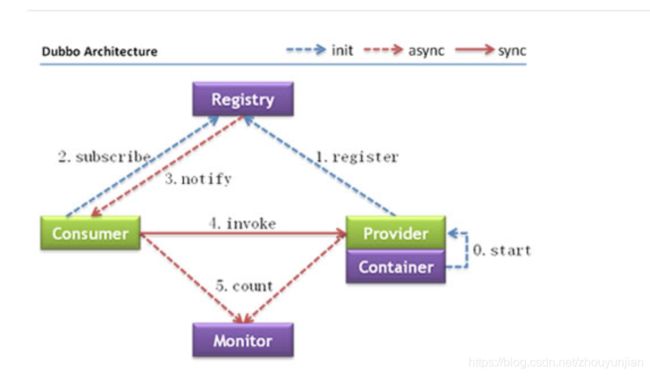
调用关系说明
-
服务容器负责启动,加载,运行服务提供者。
-
服务提供者在启动时,向注册中心注册自己提供的服务。
-
服务消费者在启动时,向注册中心订阅自己所需的服务。
-
注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
-
服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
-
服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
4个方面的问题:高可用、高并发、高性能,服务如何管理
-
客户端如何访问这么多的服务(nginx,tomcat多外暴http端口?)
-
通过API网关,dubbo,zuul
-
服务与服务之间是如何通信的?
-
同步通信(http,RPC)
-
异步通信(MQ)
-
-
这么多的服务如何管理
-
服务治理:什么时候服务上线,什么时候服务下线,这就需要服务的注册与发现
-
-
如果垂直架构里某个功能模块出现宕机或不可用,这个时候我们已经分布式了
-
容错重试机制
-
服务的降级: 写库存、同步支付信息、邮件或其他方式同步给用户
-
服务限流
-
服务熔断
-
服务搭建
-
搭建注册中心
官方推荐zookeeper
下载zookeeper
下载zookeeper修改配置
https://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.6.1/apache-zookeeper-3.6.1-bin.tar.z
1、配置zookeeper
dataDir=/root/logs/zookeeper/data ###数据配置
dataLogDir=/root/logs/zookeeper/log ###日志配置
安装问题:Error: JAVA_HOME is not set and java could not be found in PATH.
需要安装jdk1.8 linux环境: https://blog.csdn.net/qq_42670220/article/details/90753244或者 https://blog.csdn.net/weixin_43893397/article/details/102636437
启动zookeeper
./zkServer.sh start
2、配置dubbo-admin
server.port=9090 ###服务启动端口
spring.velocity.cache=false
spring.velocity.charset=UTF-8
spring.velocity.layout-url=/templates/default.vm
spring.messages.fallback-to-system-locale=false
spring.messages.basename=i18n/message
spring.root.password=root
spring.guest.password=root
dubbo.registry.address=zookeeper://127.0.0.1:2181 ###注册中心地址
3、启动dubbo后台管理服务: dubbo-admin-0.0.1-SNAPSHOT.jar需要自己打包才行
启动dubbo-admin:java -jar dubbo-admin-0.0.1-SNAPSHOT.jar
4、访问服务
http://115.29.66.116:7001/ 用户名/密码:root/root
服务注册与访问
-
搭建dubbo生产端
1、引入pom
2、配置生产端
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xmlns="http://www.springframework.org/schema/beans"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
3、对外服务
@Service
@Component
public class ProductServiceImpl implements ProductService {
@Override
public Product findProductByName(String name) {
System.out.println("==========生产者接收到请求");
Product pro=new Product();
pro.setName("衣服");
pro.setAddress("温州");
pro.setPrice(100);
return pro;
}
}
-
搭建dubbo消费端
1、引入pom(与上同)
2、引入消费端
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xmlns="http://www.springframework.org/schema/beans"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
3、对外接口
@RestController
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/product")
public Product product(){
System.out.println("==========渠道请求过来");
return productService.findProductByName("衣服");
}
}
4、访问结果: http://127.0.0.1:8081/product
{"name":"衣服","address":"温州","price":100}
dubbo服务高可用
如果运行中zookeeper挂了,还是可以消费dubbo暴露的服务
如果zookeeper实现集群后,任意一台宕机后会自动切换到另一台
虽然可以继续访问暴露的服务,但不能新注册了
Dubbo实现服务负载均衡机制&粘滞连接
配置的调用顺序
-
方法级优先,接口级次之,最后是全局
-
如果级别一样,则消费方优先,提供方次之
负载均衡配置
原则:负载均衡即可配置在消费端也可以配置在生产端,一般性服务端(生产端)知道自己的服务性能,尽可能在服务端进行配置
random、roundrobin、l
eastactive
、consistenthash
随机配置,可配置weight="200"
轮询配置,可配置weight="200" 配置权重,如果不配置,默认100,权重越大,命中概率越高
最少活跃数,需要filter="activelimit"过滤
负载均衡策略详解
-
随机 Random LoadBalance 按照权重设置的大小,随机分配
-
轮询 RoundRobin LoadBalance 例如:a b c a执行完b执行然后c,然后在到a...,按照权重比例进行分配轮询
-
最少活跃调用数(权重)LeastActive LoadBalance
活跃数指调用前后计数差,优先调用高的,相同活跃数的随机。使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
-
一致性Hash ConsistentHash LoadBalance
相同参数总是发送到同一个提供者,如果这个提供者挂掉了,它会根据它的虚拟节点,平摊到其它服务者,不会引起巨大的变动
一致性hash算法研究: https://blog.csdn.net/lihao21/article/details/54193868
粘滞连接
一般应用于消费者,让客户端尽量向同一服务端发送请求。当请求到达一个服务端时,如果此服务正常启动,则一直在此服务下
效果:
A机接收到请求

B机一直没有收到

dubbo服务后台管理界面
提供者:
-
服务启用/禁用
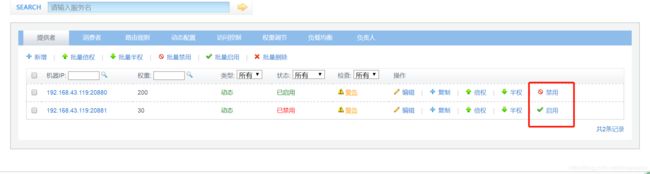
通过控制服务启用/禁用以控制服务是否可访问
-
倍权/半权
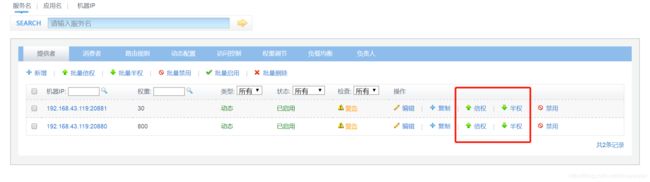
对权重加倍或者减半,此处对随机和轮询方式有效
-
路由配置
消费者:
-
容错
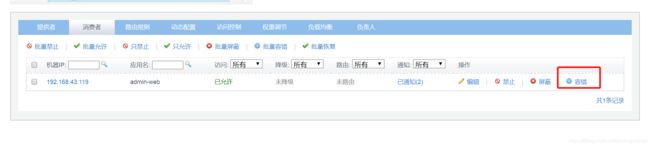
服务异常时,返回空对象,提高用户体验
-
屏蔽

屏蔽后,将不发起远程调用(生产者不可访问),直接在客户端返回空对象。
-
禁止

被禁止的客户端收到不可访问异常
路由规则:
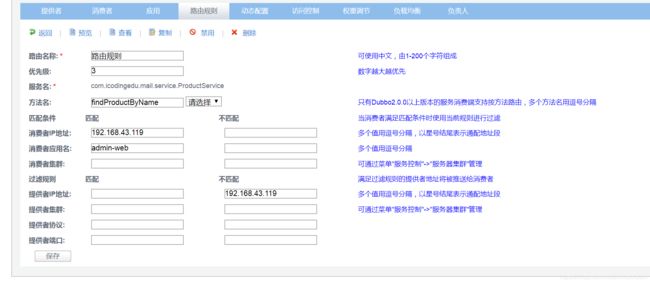
通过维护匹配条件、过滤规则来维护服务是否可访问,例如截图表示服务名为
com.icodingedu.mail.service.ProductService方法名为findProductByName下
ip地址为192.168.43.119的消费者可访问;
ip地址为192.168.43.119的生产者不可访问。
访问控制:

通过配置服务地址、服务名控制访问
负载均衡:
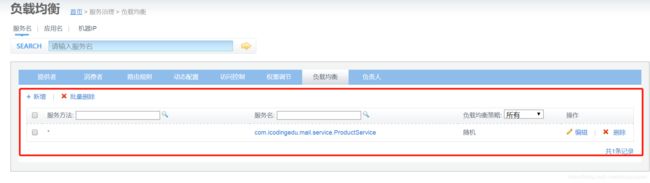
动态配置各个服务、方法级别的负载均衡
Dubbo实现服务降级:Admin管理降级,Mock返回,本地存根主动降级
mock本地伪装
本地伪装只会在消费端配置,服务端无需处理
注意点:如果增加本地伪装,在消费端服务启动前,必须先启动服务端程序,或者设置check="false",启动时不检查
本地存根主动降级
引入本地存根服务
注入接口
public class ProductServiceSub implements ProductService {
private final ProductService productService;
// 构造函数传入真正的远程代理对象
public ProductServiceSub(ProductService productService){
this.productService = productService;
}
@Override
public Product findProductByName(String name) throws InterruptedException {
System.out.println("==========本地存根主动降级");
// TimeUnit.SECONDS.sleep(1);
Product product=productService.findProductByName("本地存根");
//做进一步操作处理
product.setName("zzzzz");
return product;
}
注意:本地存根主动降级只能在consumer端,同时可对远程返回的数据做进一步处理
Dubbo实现版本控制灰度发布:version,group
多版本version
可以按照以下的步骤进行版本迁移:
-
在低压力时间段,先升级一半提供者为新版本
-
再将所有消费者升级为新版本
-
然后将剩下的一半提供者升级为新版本
提供者配置
消费者配置
分组聚合Group
按组合并返回结果 [1]
,比如菜单服务,接口一样,但有多种实现,用group区分,现在消费方需从每种group中调用一次返回结果,合并结果返回,这样就可以实现聚合菜单项。
提供者配置: 一个接口中有多种不同的实现
消费者配置
Dubbo实现隐式传参
可以在服务端口/消费端设置对应的隐式参数,在对应的消费端/服务端获取参数。此方式一般性用于框架配置使用,业务配置不建议。
设置参数:隐式传参设置必须在接口调用之前
RpcContext index = RpcContext.getContext().setAttachment("index","aaaaaa");
获取参数
RpcContext index = RpcContext.getContext().getAttachment("index");
Dubbo启用高速序列化
Java序列化本质就是将Java对象保存成二进制字节码
序列化基础与分析:
https://baijiahao.baidu.com/s?id=1633305649182361563&wfr=spider&for=pc--面试
https://www.cnblogs.com/9dragon/p/10901448.html--重点
作用就是通过网络传输进行相应的转码
dubbo远程调用序列化默认的方式是
hessian2
在进行服务化的过程中:要优化服务间调用可通过两种方式:
-
网络之间的带宽和速度,网络结构
-
传输数据本身的大小:json(gzip压缩)
dubbo高效序列化方式与选择:
kryo和
fst
Kryo和FST的性能依然普遍优于hessian和dubbo序列化
比较与分析:
关于多种序列化选取论述:建议采用kryo方式,相对成熟,可用于生成环境
https://blog.csdn.net/moonpure/article/details/53175519--重点分析与讨论
https://www.cnblogs.com/handsome1013/p/7391258.html--性能对比与沟通
dubbo序列化使用:
1、引入kryo包
2、dubbo中序列化设置为kryo
3、注册需要被序列化的类
public class SerializationOptimizerImpl implements SerializationOptimizer {
@Override
public Collection getSerializableClasses() {
List list=new ArrayList<>(10);
list.add(Product.class);
return list;
}
}
4、添加实例化接口
Dubbo服务化配置最佳使用实践
既然Dubbo是专注服务治理的,dubbo(SPI自己集成)比springcloud(全家桶)在微服务上有较大的差异
就要在服务的调用和提供上做好规划
在 Provider 端尽量多配置 Consumer 端属性
作为提供方,是最能够知道资源到底有多少的?consumer和provider已经是系统内部治理了
微服务分析报告:dubbo和springcloud的区别
https://www.cnblogs.com/matd/articles/10549336.html
https://zhuanlan.zhihu.com/p/52017256
Dubbo下的分布式锁实现
单应用场景下的锁机制
在这种情况下如何处理呢?
1、数据库乐观锁:数据更新状态发生变化后就停止更新,使用version记录的方式
select * from im_product_inventory where variants_id="v1001"; /**version=10**/
update im_product_inventory set inventory=inventory-1,version=version+1 where variants_id="v1001" and version=10;
优点:防止脏数据写入
缺点:没有顺序概念的,没有等待机制,共同抢夺资源,版本异常并不代表数据就无法实现,并且并发会对数据库带来压力
2、悲观锁
假设数据肯定会冲突,使用悲观锁一定要关闭自动自动提交set autocommit=0;
/**开始事务**/
begin transaction;
select inventory from product_inventory where id=1 for update;
/**开始修改**/
update product_inventory set inventory=inventory-1 where id=1;
/**提交事务**/
commit;
一定要注意:select …. for update,MySQL InneDB默认是行锁,行级锁都是基于索引实现的,如果查询条件不是索引列,会把整个表锁组,原因是如果没有索引就会扫整个表,就会锁表
优点:单任务,事务的隔离原子性
缺点:数据库效率执行低下,容易导致系统超时锁表
随着互联网系统的三高架构:高并发、高性能、高可用的提出,悲观锁用的越来越少
3、程序方式
synchronized(this){}
并发等待,并且只有一个线程能进入
分布式场景下的锁机制
乐观锁悲观锁解决方案
1、分布式锁应该具备哪些条件
-
在分布式系统环境下,一个方法在同一时间只能被一个机器一个线程执行
-
高可用的获取锁和释放锁
-
高性能的获取与释放锁
-
具备可重入特性(多个线程同时进入也要保证不出错误)
-
具备锁失效机制,防止死锁
-
具备非阻塞特性,即便没有获取到锁也要能返回锁失效
2、分布式锁有哪些实现方式
-
使用Redis内存数据来实现分布式锁
-
zookeeper来实现分布式锁
-
Chubby:Google,Paxos算法解决
3、通过Redis实现分布式锁理解基本概念
分布式锁有三个核心要素:加锁、解锁、锁超时
-
加锁:操作资源先去Redis里查是否有锁这个资源
-
get?setnx命令,key可以用资源的唯一标识,比如库存id,value?
-
如果这个key存在就返回给用户:目前资源紧张请等待。或者循环访问直到可以使用为止
-
-
解锁:操作完成后通过del释放锁,这个时候另一个线程就能重新获取锁
-
锁超时:如果JVM1在执行业务过程中宕机了,这个时候锁就驻留Redis中无法释放,这个时候就会死锁,JVM2就永远无法执行了,这个时候就需要通过expire 10超时来设置锁的生命周期了
以上三步只是简单的实现了分布式锁的逻辑,上面三个操作有几个致命问题
1、非原子性操作
-
setnx ,JVM1宕机了,expire
-
需要在加锁的时候就把超时时间一并设置成功
2、误删锁
自己的锁因为超时而删除,这个时候下一个线程创建了一个新锁,新锁会被上一个线程锁删除,怎么办
-
锁是谁的吧?value存UUID,线程ID
-
删除的时候判断这个锁里的UUID或线程ID是不是自己,是的话才删除
3、执行的先后顺序
我的执行线程以外还需要一个守护线程,锁超时时间是10秒,每隔9秒或更短来检测一下执行线程是否完成,如果没有完成就延长锁的失效时间,给他续命
zookeeper实现分布式锁
1、zookeeper内部结构
zookeeper是一种分布式协调的服务,通过简单的API解决我们的分布式协调问题
对于zookeeper来讲,其实就是一个树形的目录存储结构,但和目录不同的是节点本身也可以存放数据,每个节点就是一个znode
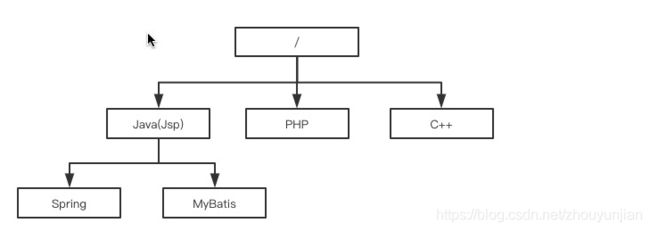
znode由以下四个部分组成
-
data:znode存放数据的地方(一个znode节点能存放的数据大小被限制在1MB以内)
-
ACL:访问权限
-
stat:各种元数据
-
child:当前节点的子节点引用
#bin目录下启动 ./zkServer.sh start
#bin目录下启动客户端 ./zkCli.sh
ls / #列出目录信息,查看目录以及对于信息都可用 ls /目录1/目录2 方式
create /node_1 Java #创建节点及节点值
delete /node_1 #删除节点
rmr /node_1 #删除节点及子节点s
znode有这两个特性:一个是顺序(非顺序),一个是临时(持久)组合出了四种节点方式
-
顺序持久节点
-
非顺序持久节点
-
顺序临时节点
-
非顺序临时节点
Zookeeper的事件通知
就是zk自带的Watch机制,可以理解为注册在特定znode上的触发器,只要这个znode发生改变(删除,修改)会触发znode上注册的对应事件,请求获取这个节点Watch的节点就会收到异步的通知
加锁
@Override
public void lock() {
//尝试获取锁
if(tryLock()){
//拿到锁
System.out.println(Thread.currentThread()+"获得锁成功........");
}else{
System.out.println(Thread.currentThread()+"获得锁失败,阻塞等待........");
//获得锁失败,等待获取锁,阻塞
waitLock();
//等待结束获取锁
lock();
}
}
//等待事件通知处理
protected boolean waitLock() {
IZkDataListener iZkDataListener = new IZkDataListener() {
@Override
public void handleDataChange(String s, Object o) throws Exception {
}
@Override
public void handleDataDeleted(String s) throws Exception {
System.out.println(Thread.currentThread()+"=========接收到节点删除通知:"+s+"等待一会儿");
TimeUnit.SECONDS.sleep(5);
System.out.println(Thread.currentThread()+"=========接收到节点删除通知:"+s+"等待完成");
if(countDownLatch!=null){
//倒计数器
countDownLatch.countDown();
}
}
};
//订阅一个数据改变的通知
zkClient.subscribeDataChanges(lock,iZkDataListener);
if(zkClient.exists(lock)){
countDownLatch = new CountDownLatch(1);
try {
countDownLatch.await();
}catch (Exception e){
e.printStackTrace();
}
}
//取消订阅
zkClient.unsubscribeDataChanges(lock,iZkDataListener);
return false;
}
//创建临时节点
@Override
protected boolean tryLock() {
try {
//创建一个临时节点
zkClient.createEphemeral(lock);
System.out.println(Thread.currentThread()+"创建节点成功.........");
return true;
}catch (Exception e){
e.printStackTrace();
System.out.println(Thread.currentThread()+"创建节点失败.........");
return false;
}
}
释放锁
@Override
public void unlock() {
//创建的是临时节点
//关闭连接来解锁
if(zkClient!=null){
//关闭连接就可以删除节点
// zkClient.close();
zkClient.delete(lock);
System.out.println(Thread.currentThread()+"关闭连接释放锁......");
}
}
dubbo常见面试题
1、Dubbo是什么?
Dubbo是阿里巴巴开源的基于 Java 的高性能 RPC 分布式服务框架,现已成为 Apache 基金会孵化项目。
面试官问你如果这个都不清楚,那下面的就没必要问了。
官网: http://dubbo.apache.org
2、为什么要用Dubbo?
因为是阿里开源项目,国内很多互联网公司都在用,已经经过很多线上考验。内部使用了 Netty、Zookeeper,保证了高性能高可用性。
使用 Dubbo 可以将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,可用于提高业务复用灵活扩展,使前端应用能更快速的响应多变的市场需求。
下面这张图可以很清楚的诠释,最重要的一点是,分布式架构可以承受更大规模的并发流量。
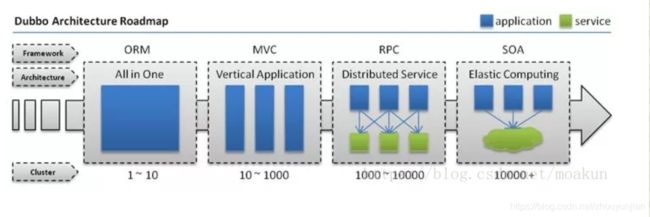
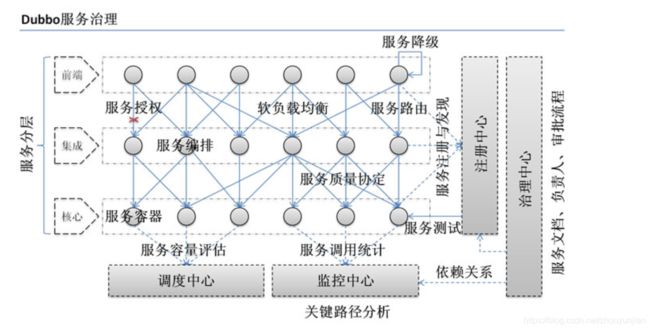
下面是 Dubbo 的服务治理图。
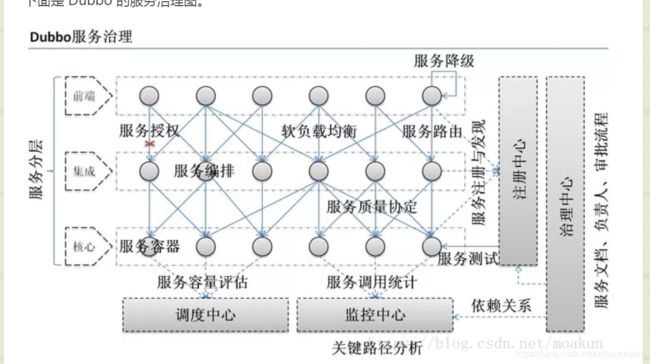
3、Dubbo 和 Spring Cloud 有什么区别?
两个没关联,如果硬要说区别,有以下几点。
1)通信方式不同
Dubbo 使用的是 RPC 通信,而 Spring Cloud 使用的是 HTTP RESTFul 方式。
2)组成部分不同

4、dubbo都支持什么协议,推荐用哪种?
dubbo://(推荐)
rmi://
hessian://
http://
webservice://
thrift://
memcached://
redis://
rest://
5、Dubbo需要 Web 容器吗?
不需要,如果硬要用 Web 容器,只会增加复杂性,也浪费资源。
6、Dubbo内置了哪几种服务容器?
Spring Container
Jetty Container
Log4j Container
Dubbo 的服务容器只是一个简单的 Main 方法,并加载一个简单的 Spring 容器,用于暴露服务。
7、Dubbo里面有哪几种节点角色?
8、画一画服务注册与发现的流程图
略
该图来自 Dubbo 官网,供你参考,如果你说你熟悉 Dubbo, 面试官经常会让你画这个图,记好了。
9、Dubbo默认使用什么注册中心,还有别的选择吗?
推荐使用 Zookeeper 作为注册中心,还有 Redis、Multicast、Simple 注册中心,但不推荐。
10、Dubbo有哪几种配置方式?
1)Spring 配置方式
2)Java API 配置方式
11、Dubbo 核心的配置有哪些?
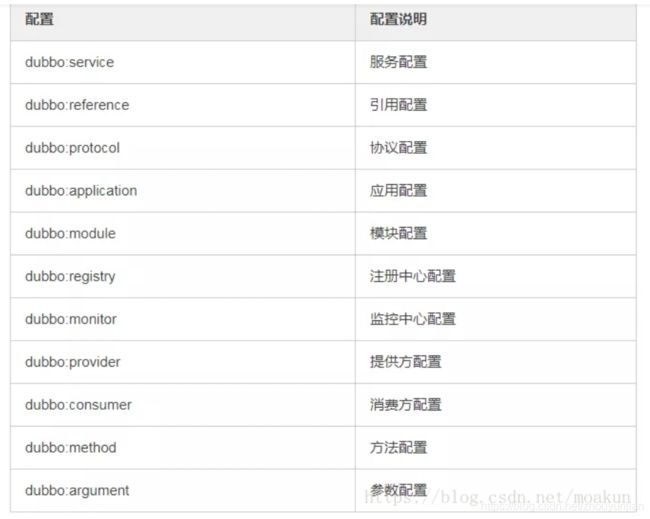
12、在 Provider 上可以配置的 Consumer 端的属性有哪些?
1)timeout:方法调用超时
2)retries:失败重试次数,默认重试 2 次
3)loadbalance:负载均衡算法,默认随机
4)actives 消费者端,最大并发调用限制
13、Dubbo启动时如果依赖的服务不可用会怎样?
Dubbo 缺省会在启动时检查依赖的服务是否可用,不可用时会抛出异常,阻止 Spring 初始化完成,默认 check="true",可以通过 check="false" 关闭检查。
14、Dubbo推荐使用什么序列化框架,你知道的还有哪些?
推荐使用Hessian序列化,还有Duddo、FastJson、Java自带序列化。
15、Dubbo默认使用的是什么通信框架,还有别的选择吗?
Dubbo 默认使用 Netty 框架,也是推荐的选择,另外内容还集成有Mina、Grizzly。
16、Dubbo有哪几种集群容错方案,默认是哪种?

17、Dubbo有哪几种负载均衡策略,默认是哪种?
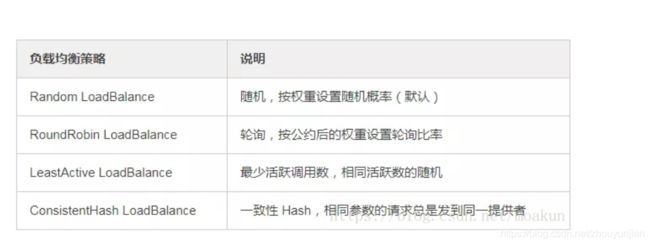
18、注册了多个同一样的服务,如果测试指定的某一个服务呢?
可以配置环境点对点直连,绕过注册中心,将以服务接口为单位,忽略注册中心的提供者列表。
19、Dubbo支持服务多协议吗?
Dubbo 允许配置多协议,在不同服务上支持不同协议或者同一服务上同时支持多种协议。
20、当一个服务接口有多种实现时怎么做?
当一个接口有多种实现时,可以用 group 属性来分组,服务提供方和消费方都指定同一个 group 即可。
21、服务上线怎么兼容旧版本?
可以用版本号(version)过渡,多个不同版本的服务注册到注册中心,版本号不同的服务相互间不引用。这个和服务分组的概念有一点类似。
22、Dubbo可以对结果进行缓存吗?
可以,Dubbo 提供了声明式缓存,用于加速热门数据的访问速度,以减少用户加缓存的工作量。
23、Dubbo服务之间的调用是阻塞的吗?
默认是同步等待结果阻塞的,支持异步调用。
Dubbo 是基于 NIO 的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小,异步调用会返回一个 Future 对象。
24、Dubbo支持分布式事务吗?
目前暂时不支持,后续可能采用基于 JTA/XA 规范实现
25、Dubbo telnet 命令能做什么?
dubbo 通过 telnet 命令来进行服务治理,具体使用看这篇文章《dubbo服务调试管理实用命令》。
telnet localhost 8090
26、Dubbo支持服务降级吗?
Dubbo 2.2.0 以上版本支持。
27、Dubbo如何优雅停机?
Dubbo 是通过 JDK 的 ShutdownHook 来完成优雅停机的,所以如果使用 kill -9 PID 等强制关闭指令,是不会执行优雅停机的,只有通过 kill PID 时,才会执行。
28、服务提供者能实现失效踢出是什么原理?
服务失效踢出基于 Zookeeper 的临时节点原理。
29、如何解决服务调用链过长的问题?
Dubbo 可以使用 Pinpoint 和 Apache Skywalking(Incubator) 实现分布式服务追踪,当然还有其他很多方案。
30、服务读写推荐的容错策略是怎样的?
读操作建议使用 Failover 失败自动切换,默认重试两次其他服务器。
写操作建议使用 Failfast 快速失败,发一次调用失败就立即报错。
31、Dubbo必须依赖的包有哪些?
Dubbo 必须依赖 JDK,其他为可选。
32、Dubbo的管理控制台能做什么?
管理控制台主要包含:路由规则,动态配置,服务降级,访问控制,权重调整,负载均衡,等管理功能。
33、说说 Dubbo 服务暴露的过程。
Dubbo 会在 Spring 实例化完 bean 之后,在刷新容器最后一步发布 ContextRefreshEvent 事件的时候,通知实现了 ApplicationListener 的 ServiceBean 类进行回调 onApplicationEvent 事件方法,Dubbo 会在这个方法中调用 ServiceBean 父类 ServiceConfig 的 export 方法,而该方法真正实现了服务的(异步或者非异步)发布。
34、Dubbo 停止维护了吗?
2014 年开始停止维护过几年,17 年开始重新维护,并进入了 Apache 项目。
35、Dubbo 和 Dubbox 有什么区别?
Dubbox 是继 Dubbo 停止维护后,当当网基于 Dubbo 做的一个扩展项目,如加了服务可 Restful 调用,更新了开源组件等。
36、你还了解别的分布式框架吗?
别的还有 Spring cloud、Facebook 的 Thrift、Twitter 的 Finagle 等。
37、Dubbo 能集成 Spring Boot 吗?
可以的,项目地址如下。
https://github.com/apache/incubator-dubbo-spring-boot-project
38、在使用过程中都遇到了些什么问题?
Dubbo 的设计目的是为了满足高并发小数据量的 rpc 调用,在大数据量下的性能表现并不好,建议使用 rmi 或 http 协议。
39、你读过 Dubbo 的源码吗?
要了解 Dubbo 就必须看其源码,了解其原理,花点时间看下吧,网上也有很多教程,后续有时间我也会在公众号上分享 Dubbo 的源码。
40、你觉得用 Dubbo 好还是 Spring Cloud 好?
扩展性的问题,没有好坏,只有适合不适合,不过我好像更倾向于使用 Dubbo, Spring Cloud 版本升级太快,组件更新替换太频繁,配置太繁琐,还有很多我觉得是没有 Dubbo 顺手的地方……