分布式任务调度
文章内容输出来源:拉勾教育Java高薪训练营
1.分布式任务调度介绍
分布式任务调度有两层含义:
(1)运行在分布式集群环境下的调度任务,即同一定时任务程序部署多份,只应该有一个定时任务执行;
(2)在分布式调度中,对比较大的定时任务进行分布式处理时,即把一个大的作业任务拆分为多个小的作业任务,同时执行,最终完成这个大的任务。
2.分布式任务调度解决方案
(1)基于Quartz开发任务管理平台
(2)分布式调度框架Elastic-Job
(3)分布式调度框架 XXL-JOB
(1)基于Quartz开发任务管理平台
Quartz是一个任务调度框架,使用时间表达式(包括:秒、分、时、日、周、年)来配置某一个任务什么时间去执行。Quartz的使用过程如下:
首先引入jar
<!--任务调度框架quartz-->
<!-- https://mvnrepository.com/artifact/org.quartz-scheduler/quartz -->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.2</version>
</dependency>
然后定义定时任务作业主调度程序
package quartz;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
public class QuartzMain {
// 创建作业任务调度器
public static Scheduler createScheduler() throws SchedulerException {
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
return scheduler;
}
// 创建一个作业任务
public static JobDetail createJob() {
JobBuilder jobBuilder = JobBuilder.newJob(DemoJob.class);
jobBuilder.withIdentity("jobName","myJob");
JobDetail jobDetail = jobBuilder.build();
return jobDetail;
}
/**
* 创建作业任务时间触发器
* cron表达式由七个位置组成,空格分隔
* 1、Seconds(秒) 0~59
* 2、Minutes(分) 0~59
* 3、Hours(小时) 0~23
* 4、Day of Month(天)1~31,注意有的月份不足31天
* 5、Month(月) 0~11,或者 JAN,FEB,MAR,APR,MAY,JUN,JUL,AUG,SEP,OCT,NOV,DEC
* 6、Day of Week(周) 1~7,1=SUN或者 SUN,MON,TUE,WEB,THU,FRI,SAT
* 7、Year(年)1970~2099 可选项
* 示例:
* 0 0 11 * * ? 每天的11点触发执行一次
* 0 30 10 1 * ? 每月1号上午10点半触发执行一次
*/
public static Trigger createTrigger() {
// 创建时间触发器,按日历调度
CronTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity("triggerName","myTrigger")
.startNow()
.withSchedule(CronScheduleBuilder.cronSchedule("0/2 * * * * ?"))
.build();
// 创建触发器,按简单隔离调度
SimpleTrigger trigger1 = TriggerBuilder.newTrigger()
.withIdentity("triggerName","myTrigger")
.startNow()
.withSchedule(SimpleScheduleBuilder
.simpleSchedule()
.withIntervalInSeconds(3)
.repeatForever())
.build();
return trigger;
}
// 定时任务作业主调度程序
public static void main(String[] args) throws SchedulerException {
// 创建一个作业任务调度器
Scheduler scheduler = QuartzMain.createScheduler();
// 创建一个作业任务
JobDetail job = QuartzMain.createJob();
// 创建一个作业任务时间触发器
Trigger trigger = QuartzMain.createTrigger();
// 使用调度器按照时间触发器执行这个作业任务
scheduler.scheduleJob(job,trigger);
scheduler.start();
}
}
最后定义一个job,需实现Job接口
package quartz;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
public class DemoJob implements Job {
public void execute(JobExecutionContext jobExecutionContext)
throws JobExecutionException {
System.out.println("我是一个定时任务逻辑");
}
}
(2)分布式调度框架Elastic-Job
Elastic-Job是当当网开源的一个分布式调度解决方案,基于Quartz二次开发的,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成。在一般的项目中使用Elastic-Job-Lite就可以,它是一个轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服务,而Elastic-Job-Cloud子项目需要结合Mesos以及Docker在云环境下使用。
Elastic-Job的github地址:https://github.com/elasticjob
Elastic-Job-Lite原理:
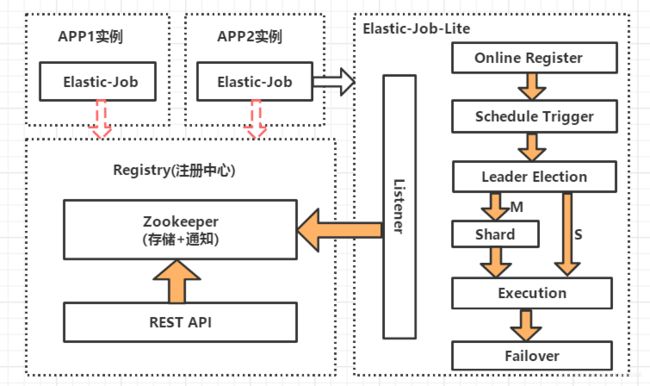
说明:
由于Elastic-Job框架在分布式集群环境下使用,所以引入了Zookeeper;如上图,我们将同一个定时任务程序部署在多个实例(服务器)中,这里分别部署在APP1和APP2中,Elastic-Job-Lite框架通过监听器感知zookeeper节点数据的变化,并做相应的处理,这里主要就是进行leader选举。当两个实例都工作时,会进行leader选举,只执行其中的一个实例的定时任务;当我们停止其中正在执行定时任务的实例时(相当于挂掉),这个定时任务会转移到可以执行定时任务的另一个实例;即Elastic-Job-Lite框架实行对zookeeper节点的监听并进行leader选举从而保证了同一个定时任务程序部署多份时只有一个定时任务在执行。

说明:
如上图,有一个JOB任务,被分成Task0、1、2、3四个任务,相当于这个定时任务被分成了4片,即任务分片为4,Strategy表示分片策略,Zookeeper是注册中心;当只启动一个APP实例时,这个实例会执行Task0、Task1、Task2、Task3,共4片任务,即独立完成这个JOB任务;当启动两个APP实例时,会根据分片策略将Task0和Task1分配给APP1实例执行,Task2和Task3分配给APP2实例执行,即两个实例同时来完成这个JOB任务,也即分担原来APP实例的任务执行;当多个APP实例执行任务时,停止其中一个APP实例,这是每个分片任务又会被重新分配到其他APP实例上进行执行。
Elastic-Job-Lite的使用过程如下:
首先引入依赖jar
<!-- https://mvnrepository.com/artifact/com.dangdang/elastic-job-lite-core -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>2.1.5</version>
</dependency>
然后书写定时任务类:
package elasticjob;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
import util.JdbcUtil;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.List;
import java.util.Map;
public class BackupJob implements SimpleJob {
// 定时任务每执行一次都会执行下面逻辑
@Override
public void execute(ShardingContext shardingContext) {
/*
从resume数据表查找1条未归档的数据,将其归档到resume_bak表,并更新状态为已归档(不删除 原数据)
*/
// 查询出一条数据
String selectSql = "select * from resume where state='未归档' limit 1";
List<Map<String, Object>> list =JdbcUtil.executeQuery(selectSql);
if(list == null || list.size() == 0) {
return;
}
Map<String, Object> stringObjectMap = list.get(0);
long id = (long) stringObjectMap.get("id");
String name = (String) stringObjectMap.get("name");
String education = (String)stringObjectMap.get("education");
// 打印出这条记录
System.out.println("======>>>id:" + id + " name:" +
name + " education:" + education);
// 更新状态
String updateSql = "update resume set state='已归档' where id=?";
JdbcUtil.executeUpdate(updateSql,id);
// 归档这条记录
String insertSql = "insert into resume_bak select * from resume where id=?";
JdbcUtil.executeUpdate(insertSql,id);
}
}
接着书写任务调用主类:
package elasticjob;
import com.dangdang.ddframe.job.config.JobCoreConfiguration;
import com.dangdang.ddframe.job.config.simple.SimpleJobConfiguration;
import com.dangdang.ddframe.job.lite.api.JobScheduler;
import com.dangdang.ddframe.job.lite.config.LiteJobConfiguration;
import com.dangdang.ddframe.job.reg.base.CoordinatorRegistryCenter;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperConfiguration;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter;
public class ElasticJobMain {
public static void main(String[] args) {
// 配置注册中心zookeeper,zookeeper协调调度,不能让任务重复执行,通过命名空间分类管
//理任务,对应到zookeeper的目录
ZookeeperConfiguration zookeeperConfiguration = new
ZookeeperConfiguration("localhost:2181","data-archive-job");
CoordinatorRegistryCenter coordinatorRegistryCenter = new
ZookeeperRegistryCenter(zookeeperConfiguration);
coordinatorRegistryCenter.init();
// 配置任务
JobCoreConfiguration jobCoreConfiguration =
JobCoreConfiguration.newBuilder("archive-job","*/2 * * * * ?",1).build();
SimpleJobConfiguration simpleJobConfiguration = new
SimpleJobConfiguration(jobCoreConfiguration,BackupJob.class.getName());
// 启动任务
new JobScheduler(coordinatorRegistryCenter,
LiteJobConfiguration.newBuilder(simpleJobConfiguration).build()).init();
}
}
JdbcUtil工具类:
package util;
import java.sql.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class JdbcUtil {
//url
private static String url = "jdbc:mysql://localhost:3306/job?characterEncoding=utf8&useSSL=false";
//user
private static String user = "root";
//password
private static String password = "123456";
//驱动程序类
private static String driver = "com.mysql.jdbc.Driver";
static {
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static Connection getConnection() {
try {
return DriverManager.getConnection(url, user,password);
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
public static void close(ResultSet rs, PreparedStatement ps,Connection con) {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if (con != null) {
try {
con.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
}
}
public static void executeUpdate(String sql,Object...obj) {
Connection con = getConnection();
PreparedStatement ps = null;
try {
ps = con.prepareStatement(sql);
for (int i = 0; i < obj.length; i++) {
ps.setObject(i + 1, obj[i]);
}
ps.executeUpdate();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
close(null, ps, con);
}
}
public static List<Map<String,Object>> executeQuery(String sql, Object...obj) {
Connection con = getConnection();
ResultSet rs = null;
PreparedStatement ps = null;
try {
ps = con.prepareStatement(sql);
for (int i = 0; i < obj.length; i++) {
ps.setObject(i + 1, obj[i]);
}
rs = ps.executeQuery();
List<Map<String, Object>> list = new ArrayList<>();
int count = rs.getMetaData().getColumnCount();
while (rs.next()) {
Map<String, Object> map = new HashMap<String,Object>();
for (int i = 0; i < count; i++) {
Object ob = rs.getObject(i + 1);
String key = rs.getMetaData().getColumnName(i + 1);
map.put(key, ob);
}
list.add(map);
}
return list;
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
close(rs, ps, con);
}
return null;
}
}
最后进行测试:
首先可先启动一个进程,然后再启动一个进程,即两个进程模拟分布式环境下,通过一个定时任务部署在两个实例中工作;
然后两个进程逐个启动,观察现象;
最后关闭其中执行的进程,观察现象;
(3)分布式调度框架 XXL-JOB
XXL-JOB是大众点评员工徐雪里于2015年发布的分布式任务调度平台,是一个轻量级分布式任务调度框架,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。
官方地址:https://www.xuxueli.com/xxl-job/
XXL-JOB将定时任务分为两个部分:调度中心和执行器。
XXL-JOB的使用过程如下:
首先部署调度中心:
部署步骤如下:
a. 下载xxl-job源码:http://gitee.com/xuxueli0323/xxl-job/,使用maven编译打包,生成部署的xxl-job-admin.jar;
b. 创建数据库,并初始化相关的表,脚本参考源码目录doc/db/tables_xxl_job.sql;
c. 创建部署目录,并配置数据库等配置,可在打包之前,在源码里面application.properties进行配置,也可以在部署目录里面单独创建application.properties文件里面进行配置(推荐,spring boot优先加载启动目录下的配置,可以避免以后更改数据库等配置时还需要重新打包源码)
d.运行管理平台(请先确保已经配置好Java执行环境,Jdk1.8或者以上)。
然后开发业务系统对接(执行器):
基于spring boot配置执行器
@Configuration
public class XxlJobConfig {
//spring boot应用基本都有appname,这里默认使用spring app name配置
@Value("${spring.application.name:}")
private String springAppName;
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname:}")
private String appName;
//ip地址在多网卡、容器的时候需要指定,否则的话,使用默认就可以,
//spring-cloud-commons中提供了InetUtils工具类,可以帮助获取IP
@Value("${xxl.job.executor.ip:}")
private String ip;
//port可以默认指定一个,如果多个服务部署在同一台服务器上,可以通过检测获取或者规划分配
@Value("${xxl.job.executor.port:9999}")
private int port;
@Value("${xxl.job.accessToken:}")
private String accessToken;
//logpath最好指定在应用目录下,最好不要使用绝对路径,避免和其应用冲突
@Value("${xxl.job.executor.logpath:job-logs}")
private String logPath;
//logretentiondays日志保留天数不用太大,根据需要设置,默认给一个较短的时间即可
@Value("${xxl.job.executor.logretentiondays:7}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
if (StringUtils.isEmpty(appName)) {
if (StringUtils.isEmpty(springAppName)) {
throw new IllegalStateException("missing xxl-job appname config");
}
appName = springAppName;
}
xxlJobSpringExecutor.setAppName(appName);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}
基于@XxlJob注解代码方式开发定时任务(建议制定名称,和调度中心配置保持一致)
@Component
public class SampleXxlJob {
private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);
/**
* 简单任务示例(Bean模式)
*/
@XxlJob("demoJobHandler")
public ReturnT<String> demoJobHandler(String param) throws Exception {
XxlJobLogger.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
XxlJobLogger.log("beat at:" + i);
TimeUnit.SECONDS.sleep(2);
}
return ReturnT.SUCCESS;
}
/**
* 分片广播任务
*/
@XxlJob("shardingJobHandler")
public ReturnT<String> shardingJobHandler(String param) throws Exception {
// 分片参数
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardingVO.getIndex(), shardingVO.getTotal());
// 业务逻辑
for (int i = 0; i < shardingVO.getTotal(); i++) {
if (i == shardingVO.getIndex()) {
XxlJobLogger.log("第 {} 片, 命中分片开始处理", i);
} else {
XxlJobLogger.log("第 {} 片, 忽略", i);
}
}
return ReturnT.SUCCESS;
}
}
配置定时任务
a.先配置执行器,推荐使用自动注册方式,避免集群部署时还需要调整机器地址(注意appname要和业务系统中配置一致);
b.添加完执行器后,添加任务,JobHandler要和代码中配置的名称一致,执行器集群部署可以通过配置路由方式来控制执行,xxl-job调度只支持cron表达式;
c.启动或者执行任务,查询执行日志、注册节点等进行观察。
3.分布式任务调度方案的选择
根据需求,公司可以基于Quartz开发属于自己的任务管理平台,也推荐使用第三方开源的分布式调度框架Elastic-Job和XXL-JOB。
文章内容输出来源:拉勾教育Java高薪训练营
若有错误之处,欢迎留言指正~~~