Lucene.net站内搜索2—Lucene.Net简介和分词
Lucene.Net简介
Lucene.Net是由Java版本的Lucene(卢思银)移植过来的,所有的类、方法都几乎和Lucene一模一样,因此使用时参考Lucene 即可。Lucene.Net只是一个全文检索开发包(就像ADO.Net和管理系统的关系),不是一个成型的搜索引擎,它的功能就是:把数据扔给Lucene.Net ,查询数据的时候从Lucene.Net 查询数据,可以看做是提供了全文检索功能的一个数据库。SQLServer中和Lucene.Net各存一份,目的不一样。Lucene.Net不管文本数据怎么来的。用户可以基于Lucene.Net开发满足自己需求的搜索引擎。 Lucene.Net只能对文本信息进行检索。如果不是文本信息,要转换为文本信息,比如要检索Excel文件,就要用NPOI把Excel读取成字符串,然后把字符串扔给Lucene.Net。Lucene.Net会把扔给它的文本切词保存,加快检索速度。midomi.com。因为是保存的时候分词(切词),所以搜索速度非常快!索引库默认保存的是“词的目录”
要快速的从《红楼梦》中找出词,可以先遍历这本书建一个词和页数的对应目录。第一次“找词”非常慢,但是搜索就快了。

分词
分词是核心的算法,搜索引擎内部保存的就是一个个的“词(Word)”。英文分词很简单,按照空格分隔就可以。中文则麻烦,把“北京,Hi欢迎你们大家” 拆成“北京 Hi 欢迎 你们大家”。
“the”,“,”,“和”,“啊”,“的”等对于搜索来说无意义的词一般都属于不参与分词的无意义单词(noise word)。
Lucene.Net中不同的分词算法就是不同的类。所有分词算法类都从Analyzer类继承,不同的分词算法有不同的优缺点。
(*)内置的StandardAnalyzer是将英文按照空格、标点符号等进行分词,将中文按照单个字进行分词,一个汉字算一个词。代码见备注
(*)二元分词算法,每两个汉字算一个单词,“欢迎你们大家”会分词为“欢迎 迎你 你们 们大 大家”,网上找到的一个二元分词算法CJKAnalyzer。面试的时候能说出不同的分词算法的差异。
无论是一元分词还是二元分词,分词效率比较高,但是分出无用词,因此索引库大。查询效率低。
基于词库的分词算法,基于一个词库进行分词,可以提高分词的成功率。有庖丁解牛、盘古分词等。效率低。
1、 StandardAnalyzer示例(不用背代码,拷过来知道改哪里即可,我复制粘贴的代码你也一样复制粘贴)
Analyzer analyzer = new StandardAnalyzer();
TokenStream tokenStream = analyzer.TokenStream("",newStringReader("我是真的爱你"));
Lucene.Net.Analysis.Token token = null;
while ((token =tokenStream.Next()) != null)
{
Console.WriteLine(token.TermText());
}
盘古分词算法使用
具体用法参考《PanguMannual.pdf》
打开PanGu4Lucene\WebDemo\Bin,添加对PanGu.dll(同目录下不要有Pangu.xml,那个默认的配置文件的选项对于分词结果有很多无用信息)、PanGu.Lucene.Analyzer.dll的引用
把上面代码的Analyzer用PanGuAnalyzer代替
运行发现提示需要dct文件,因为不能把词库写死在dll中,因此需要提供单独的词库文件,根据报错放到合适的路径中。
通用技巧:把Dict目录下的文件“复制到输出目录”设定为“如果较新则复制”,每次生成的时候都会自动把文件拷到bin\Debug 下,非常方便。(只有Web应用程序有那个选项,网站没有。)永远不要对bing\debug下的东西做直接的修改,要改“源文件”。
词库的编辑,使用DictManage.exe,对单词编辑的时候要先查找。工作的项目中要将行业单词添加到词库中,比如餐饮搜索、租房搜索、视频搜索等。
注:出现Dict路径的问题,没有找到配置文件,默认就是Dict目录,设定Pangu.xml的复制到输出设置为“如果较新则复制”即可。或者词典目录就命名为Dict,不要配置文件。
Demo:
一元分词
1、 新建项目——ASP.NET Web应用程序SearchDemo
2、 新建文件夹lib,存放dll文件Lucene.Net.dll
3、 添加Lucene.Net.dll引用

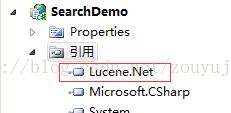

二元分词
1、拷贝两个类到根目录下
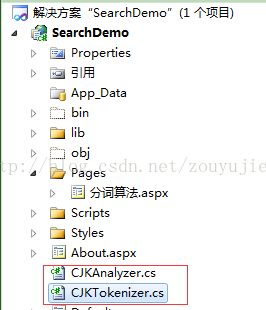

盘古分词
1、 拷贝两个dll PanGu.dll和PanGu.Lucene.Analyzer.dll到lib目录下

2、 添加这两个dll的引用
3、 添加Dict词库目录和词库文件
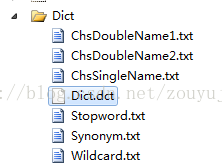
4、 修改分词代码
5、 如果出现如下错误

把Dict目录下的文件“复制到输出目录”设定为“如果较新则复制”


分词代码如下:
aspx:
using Lucene.Net.Analysis;
using System.IO;
using Lucene.Net.Analysis.Standard;
using NSharp.SearchEngine.Lucene.Analysis.Cjk;
using Lucene.Net.Analysis.PanGu;
namespace SearchDemo.Pages
{
public partial class 分词算法 : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
}
protected void btnOnePartWord_Click(object sender, EventArgs e)
{
Analyzer oneAnalyzer = new StandardAnalyzer(); //一元分词
PartWordMethod(oneAnalyzer);
}
private void PartWordMethod(Analyzer analyzer)
{
lstWord.Items.Clear();
//Analyzer analyzer = new PanGuAnalyzer();
TokenStream tokenStream = analyzer.TokenStream("", new StringReader(txtContent.Text));
Lucene.Net.Analysis.Token token = null;
while ((token = tokenStream.Next()) != null)
{
string word = token.TermText();
lstWord.Items.Add(word);
}
}
protected void btnTwoPartWord_Click(object sender, EventArgs e)
{
Analyzer oneAnalyzer = new CJKAnalyzer(); //二元分词
PartWordMethod(oneAnalyzer);
}
protected void btnPanGu_Click(object sender, EventArgs e)
{
Analyzer oneAnalyzer = new PanGuAnalyzer(); //盘古分词
PartWordMethod(oneAnalyzer);
}
}
}